 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rate-Distortion-Perception-Classification Tradeoff: Joint Source Coding and Modulation via Inverse-Domain GANs
Dec 22, 2023The joint source coding and modulation (JSCM) framework was enabled by recent developments in deep learning, which allows to automatically learn from data, and in an end-to-end fashion, the best compression codes and modulation schemes. In this paper, we show the existence of a strict tradeoff between channel rate, distortion, perception, and classification accuracy in a JSCM scenario. We then propose two image compression methods to navigate that tradeoff: an inverse-domain generative adversarial network (ID-GAN), which achieves extreme compression, and a simpler, heuristic method that reveals insights about the performance of ID-GAN. Experiment results not only corroborate the theoretical findings, but also demonstrate that the proposed ID-GAN algorithm significantly improves system performance compared to traditional separation-based methods and recent deep JSCM architectures.
Measurement-Consistent Networks via a Deep Implicit Layer for Solving Inverse Problems
Nov 06, 2022End-to-end deep neural networks (DNNs) have become state-of-the-art (SOTA) for solving inverse problems. Despite their outstanding performance, during deployment, such networks are sensitive to minor variations in the training pipeline and often fail to reconstruct small but important details, a feature critical in medical imaging, astronomy, or defence. Such instabilities in DNNs can be explained by the fact that they ignore the forward measurement model during deployment, and thus fail to enforce consistency between their output and the input measurements. To overcome this, we propose a framework that transforms any DNN for inverse problems into a measurement-consistent one. This is done by appending to it an implicit layer (or deep equilibrium network) designed to solve a model-based optimization problem. The implicit layer consists of a shallow learnable network that can be integrated into the end-to-end training. Experiments on single-image super-resolution show that the proposed framework leads to significant improvements in reconstruction quality and robustness over the SOTA DNNs.
Enhanced Hyperspectral Image Super-Resolution via RGB Fusion and TV-TV Minimization
Jun 13, 2021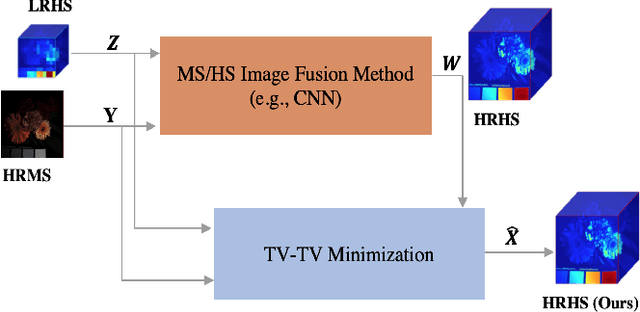
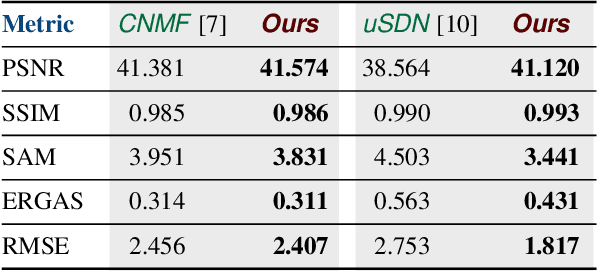

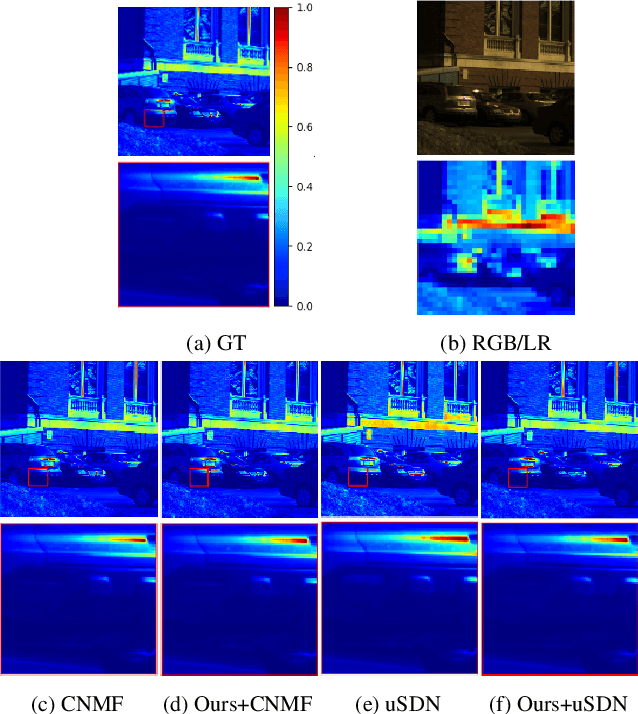
Hyperspectral (HS) images contain detailed spectral information that has proven crucial in applications like remote sensing, surveillance, and astronomy. However, because of hardware limitations of HS cameras, the captured images have low spatial resolution. To improve them, the low-resolution hyperspectral images are fused with conventional high-resolution RGB images via a technique known as fusion based HS image super-resolution. Currently, the best performance in this task is achieved by deep learning (DL) methods. Such methods, however, cannot guarantee that the input measurements are satisfied in the recovered image, since the learned parameters by the network are applied to every test image. Conversely, model-based algorithms can typically guarantee such measurement consistency. Inspired by these observations, we propose a framework that integrates learning and model based methods. Experimental results show that our method produces images of superior spatial and spectral resolution compared to the current leading methods, whether model- or DL-based.
Overcoming Measurement Inconsistency in Deep Learning for Linear Inverse Problems: Applications in Medical Imaging
Nov 29, 2020

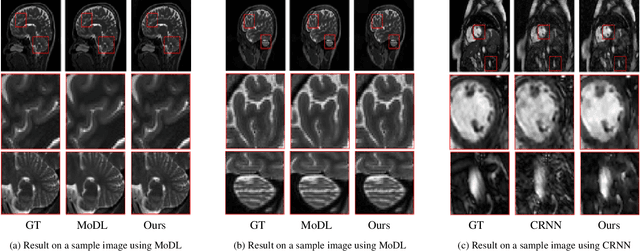
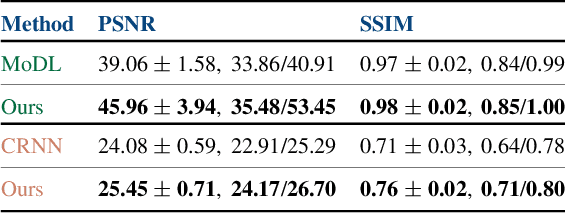
The remarkable performance of deep neural networks (DNNs) currently makes them the method of choice for solving linear inverse problems. They have been applied to super-resolve and restore images, as well as to reconstruct MR and CT images. In these applications, DNNs invert a forward operator by finding, via training data, a map between the measurements and the input images. It is then expected that the map is still valid for the test data. This framework, however, introduces measurement inconsistency during testing. We show that such inconsistency, which can be critical in domains like medical imaging or defense, is intimately related to the generalization error. We then propose a framework that post-processes the output of DNNs with an optimization algorithm that enforces measurement consistency. Experiments on MR images show that enforcing measurement consistency via our method can lead to large gains in reconstruction performance.
Robust Single-Image Super-Resolution via CNNs and TV-TV Minimization
Apr 02, 2020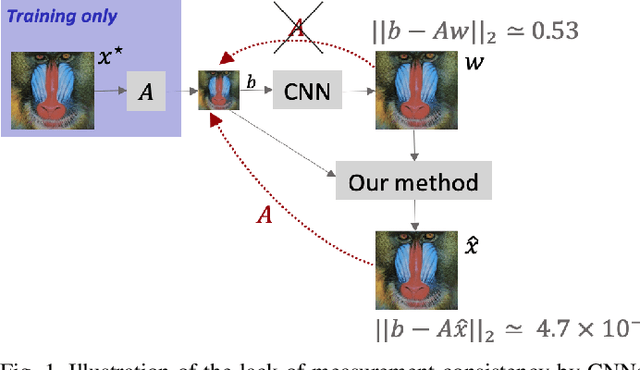
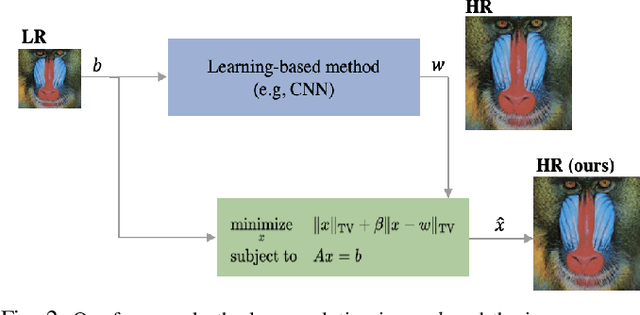


Single-image super-resolution is the process of increasing the resolution of an image, obtaining a high-resolution (HR) image from a low-resolution (LR) one. By leveraging large training datasets, convolutional neural networks (CNNs) currently achieve the state-of-the-art performance in this task. Yet, during testing/deployment, they fail to enforce consistency between the HR and LR images: if we downsample the output HR image, it never matches its LR input. Based on this observation, we propose to post-process the CNN outputs with an optimization problem that we call TV-TV minimization, which enforces consistency. As our extensive experiments show, such post-processing not only improves the quality of the images, in terms of PSNR and SSIM, but also makes the super-resolution task robust to operator mismatch, i.e., when the true downsampling operator is different from the one used to create the training dataset.
Single Image Super-Resolution via CNN Architectures and TV-TV Minimization
Jul 11, 2019
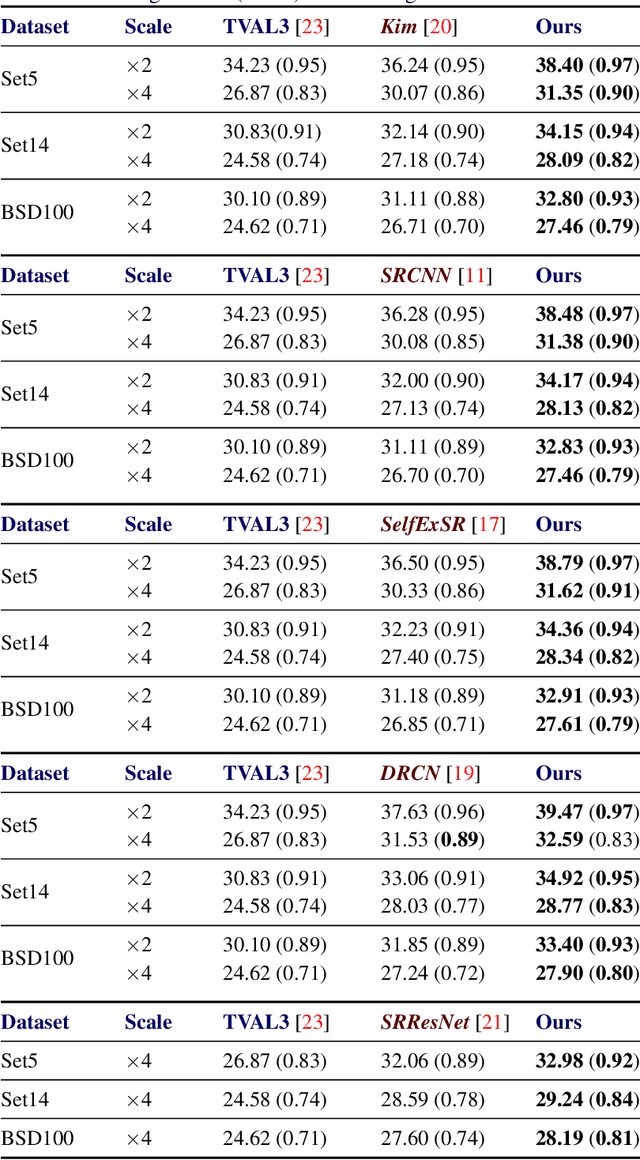


Super-resolution (SR) is a technique that allows increasing the resolution of a given image. Having applications in many areas, from medical imaging to consumer electronics, several SR methods have been proposed. Currently, the best performing methods are based on convolutional neural networks (CNNs) and require extensive datasets for training. However, at test time, they fail to impose consistency between the super-resolved image and the given low-resolution image, a property that classic reconstruction-based algorithms naturally enforce in spite of having poorer performance. Motivated by this observation, we propose a new framework that joins both approaches and produces images with superior quality than any of the prior methods. Although our framework requires additional computation, our experiments on Set5, Set14, and BSD100 show that it systematically produces images with better peak signal to noise ratio (PSNR) and structural similarity (SSIM) than the current state-of-the-art CNN architectures for SR.
Multimodal Image Super-resolution via Joint Sparse Representations induced by Coupled Dictionaries
Mar 08, 2018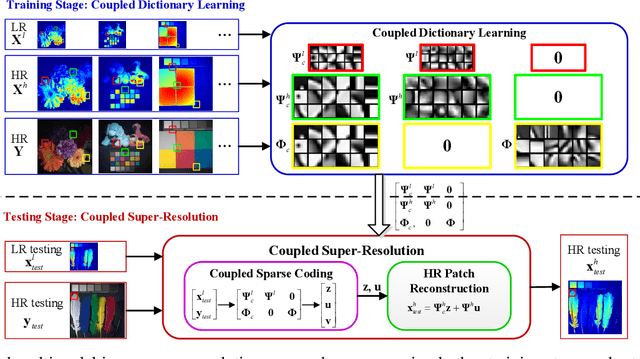


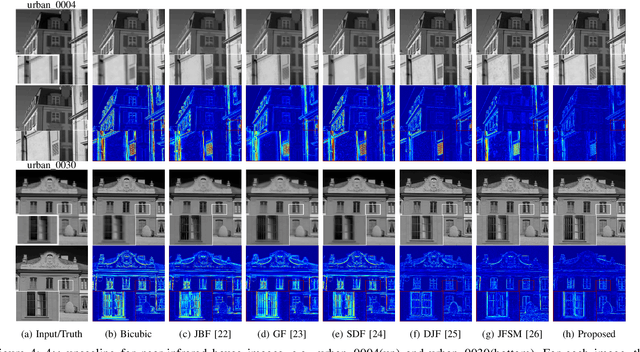
Real-world data processing problems often involve various image modalities associated with a certain scene, including RGB images, infrared images or multi-spectral images. The fact that different image modalities often share certain attributes, such as certain edges, textures and other structure primitives, represents an opportunity to enhance various image processing tasks. This paper proposes a new approach to construct a high-resolution (HR) version of a low-resolution (LR) image given another HR image modality as reference, based on joint sparse representations induced by coupled dictionaries. Our approach, which captures the similarities and disparities between different image modalities in a learned sparse feature domain in \emph{lieu} of the original image domain, consists of two phases. The coupled dictionary learning phase is used to learn a set of dictionaries that couple different image modalities in the sparse feature domain given a set of training data. In turn, the coupled super-resolution phase leverages such coupled dictionaries to construct a HR version of the LR target image given another related image modality. One of the merits of our sparsity-driven approach relates to the fact that it overcomes drawbacks such as the texture copying artifacts commonly resulting from inconsistency between the guidance and target images. Experiments on real multimodal images demonstrate that incorporating appropriate guidance information via joint sparse representation induced by coupled dictionary learning brings notable benefits in the super-resolution task with respect to the state-of-the-art. Of particular relevance, the proposed approach also demonstrates better robustness than competing deep-learning-based methods in the presence of noise.
X-ray image separation via coupled dictionary learning
May 20, 2016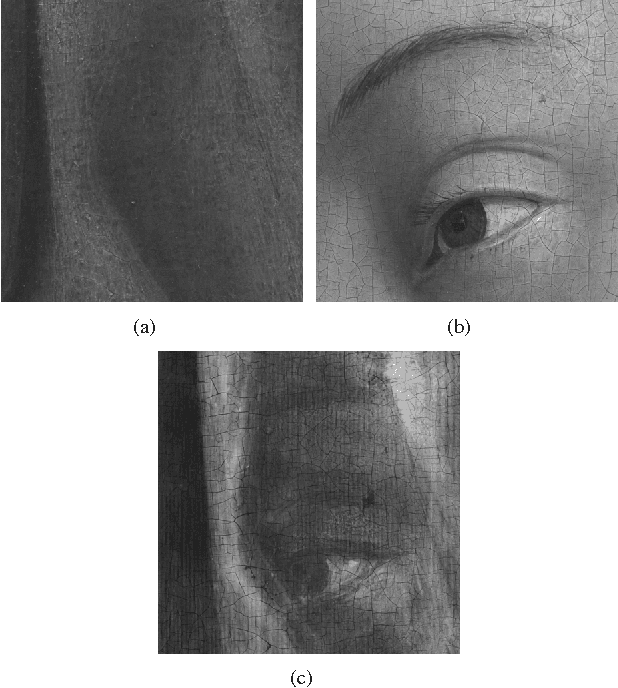
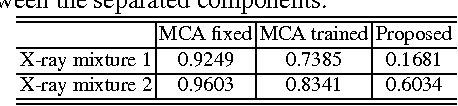
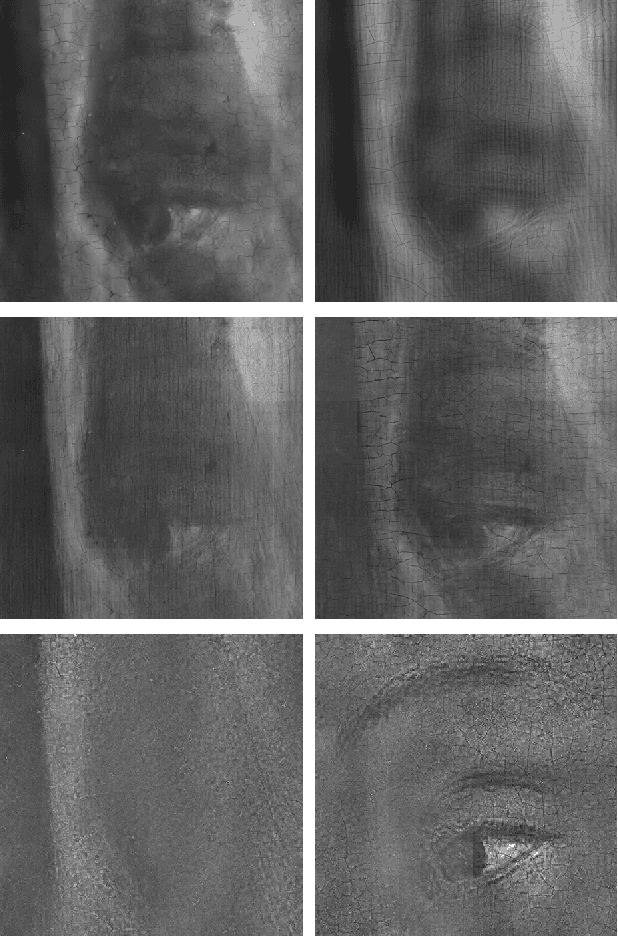
In support of art investigation, we propose a new source sepa- ration method that unmixes a single X-ray scan acquired from double-sided paintings. Unlike prior source separation meth- ods, which are based on statistical or structural incoherence of the sources, we use visual images taken from the front- and back-side of the panel to drive the separation process. The coupling of the two imaging modalities is achieved via a new multi-scale dictionary learning method. Experimental results demonstrate that our method succeeds in the discrimination of the sources, while state-of-the-art methods fail to do so.
Compressed Sensing With Side Information: Geometrical Interpretation and Performance Bounds
Oct 10, 2014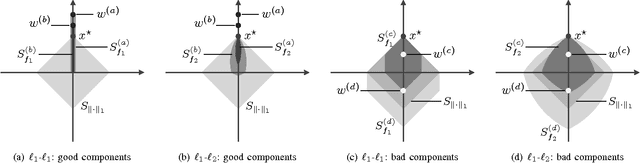
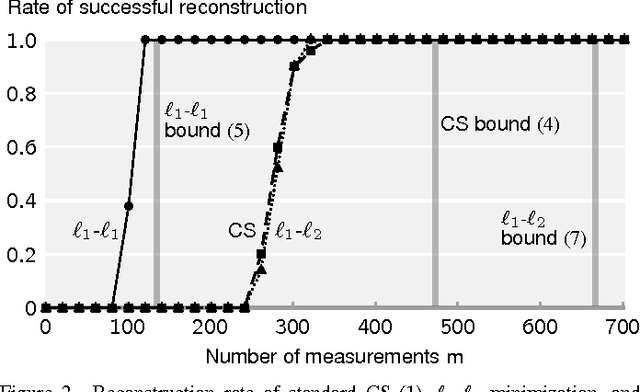

We address the problem of Compressed Sensing (CS) with side information. Namely, when reconstructing a target CS signal, we assume access to a similar signal. This additional knowledge, the side information, is integrated into CS via L1-L1 and L1-L2 minimization. We then provide lower bounds on the number of measurements that these problems require for successful reconstruction of the target signal. If the side information has good quality, the number of measurements is significantly reduced via L1-L1 minimization, but not so much via L1-L2 minimization. We provide geometrical interpretations and experimental results illustrating our findings.