 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Image Super-resolution via Joint Sparse Representations induced by Coupled Dictionaries
Paper and Code
Mar 08, 2018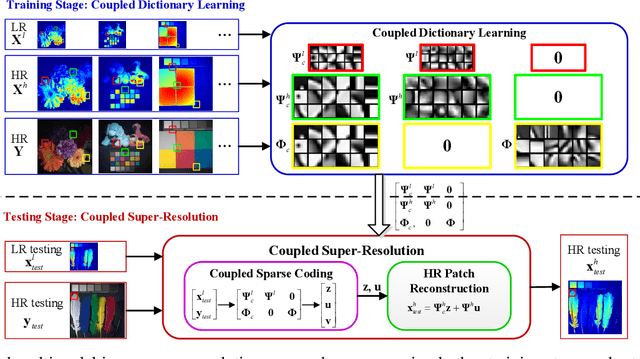


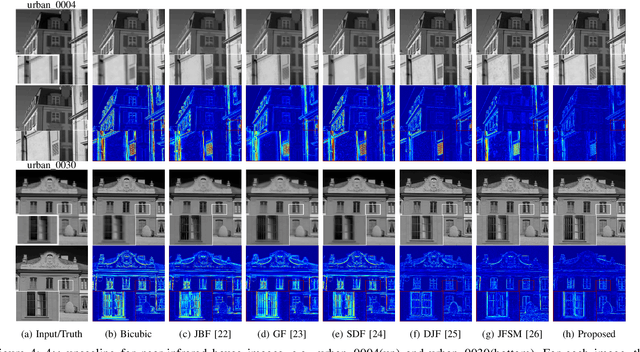
Real-world data processing problems often involve various image modalities associated with a certain scene, including RGB images, infrared images or multi-spectral images. The fact that different image modalities often share certain attributes, such as certain edges, textures and other structure primitives, represents an opportunity to enhance various image processing tasks. This paper proposes a new approach to construct a high-resolution (HR) version of a low-resolution (LR) image given another HR image modality as reference, based on joint sparse representations induced by coupled dictionaries. Our approach, which captures the similarities and disparities between different image modalities in a learned sparse feature domain in \emph{lieu} of the original image domain, consists of two phases. The coupled dictionary learning phase is used to learn a set of dictionaries that couple different image modalities in the sparse feature domain given a set of training data. In turn, the coupled super-resolution phase leverages such coupled dictionaries to construct a HR version of the LR target image given another related image modality. One of the merits of our sparsity-driven approach relates to the fact that it overcomes drawbacks such as the texture copying artifacts commonly resulting from inconsistency between the guidance and target images. Experiments on real multimodal images demonstrate that incorporating appropriate guidance information via joint sparse representation induced by coupled dictionary learning brings notable benefits in the super-resolution task with respect to the state-of-the-art. Of particular relevance, the proposed approach also demonstrates better robustness than competing deep-learning-based methods in the presence of noise.