 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight-Field Microscopy for optical imaging of neuronal activity: when model-based methods meet data-driven approaches
Oct 24, 2021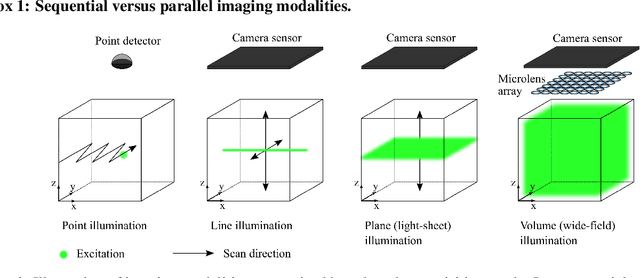
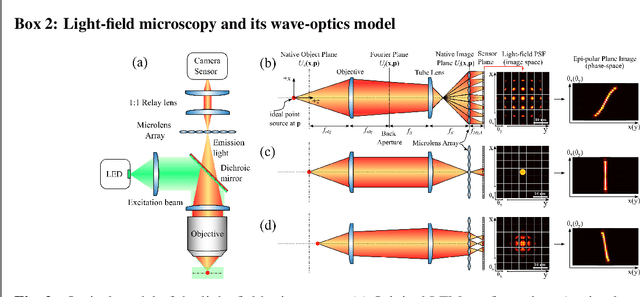
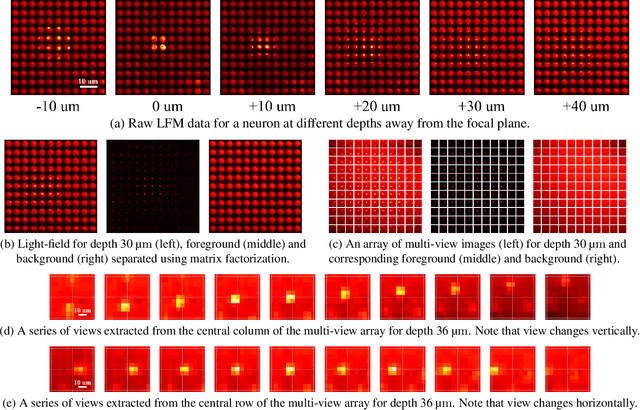
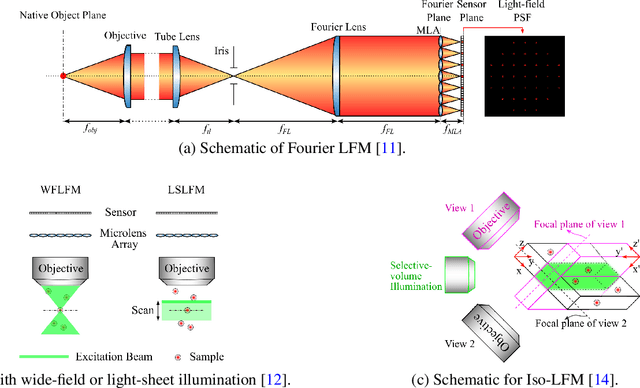
Understanding how networks of neurons process information is one of the key challenges in modern neuroscience. A necessary step to achieve this goal is to be able to observe the dynamics of large populations of neurons over a large area of the brain. Light-field microscopy (LFM), a type of scanless microscope, is a particularly attractive candidate for high-speed three-dimensional (3D) imaging. It captures volumetric information in a single snapshot, allowing volumetric imaging at video frame-rates. Specific features of imaging neuronal activity using LFM call for the development of novel machine learning approaches that fully exploit priors embedded in physics and optics models. Signal processing theory and wave-optics theory could play a key role in filling this gap, and contribute to novel computational methods with enhanced interpretability and generalization by integrating model-driven and data-driven approaches. This paper is devoted to a comprehensive survey to state-of-the-art of computational methods for LFM, with a focus on model-based and data-driven approaches.
Model-inspired Deep Learning for Light-Field Microscopy with Application to Neuron Localization
Mar 10, 2021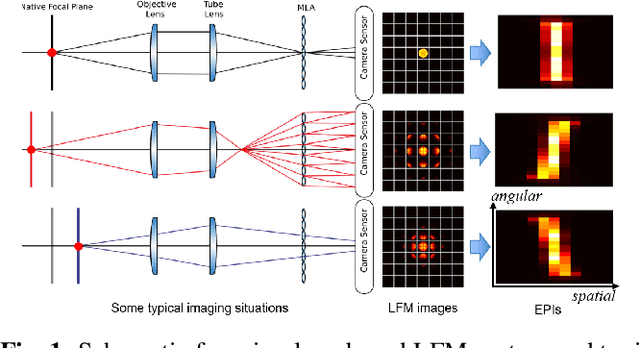
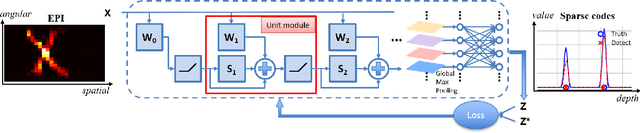
Light-field microscopes are able to capture spatial and angular information of incident light rays. This allows reconstructing 3D locations of neurons from a single snap-shot.In this work, we propose a model-inspired deep learning approach to perform fast and robust 3D localization of sources using light-field microscopy images. This is achieved by developing a deep network that efficiently solves a convolutional sparse coding (CSC) problem to map Epipolar Plane Images (EPI) to corresponding sparse codes. The network architecture is designed systematically by unrolling the convolutional Iterative Shrinkage and Thresholding Algorithm (ISTA) while the network parameters are learned from a training dataset. Such principled design enables the deep network to leverage both domain knowledge implied in the model, as well as new parameters learned from the data, thereby combining advantages of model-based and learning-based methods. Practical experiments on localization of mammalian neurons from light-fields show that the proposed approach simultaneously provides enhanced performance, interpretability and efficiency.
Coupled Dictionary Learning for Multi-contrast MRI Reconstruction
Jun 26, 2018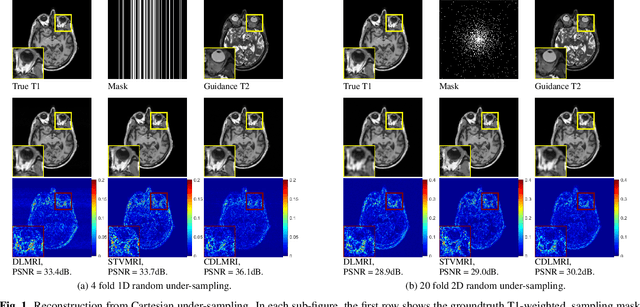
Medical imaging tasks often involve multiple contrasts, such as T1- and T2-weighted magnetic resonance imaging (MRI) data. These contrasts capture information associated with the same underlying anatomy and thus exhibit similarities. In this paper, we propose a Coupled Dictionary Learning based multi-contrast MRI reconstruction (CDLMRI) approach to leverage an available guidance contrast to restore the target contrast. Our approach consists of three stages: coupled dictionary learning, coupled sparse denoising, and $k$-space consistency enforcing. The first stage learns a group of dictionaries that capture correlations among multiple contrasts. By capitalizing on the learned adaptive dictionaries, the second stage performs joint sparse coding to denoise the corrupted target image with the aid of a guidance contrast. The third stage enforces consistency between the denoised image and the measurements in the $k$-space domain. Numerical experiments on the retrospective under-sampling of clinical MR images demonstrate that incorporating additional guidance contrast via our design improves MRI reconstruction, compared to state-of-the-art approaches.
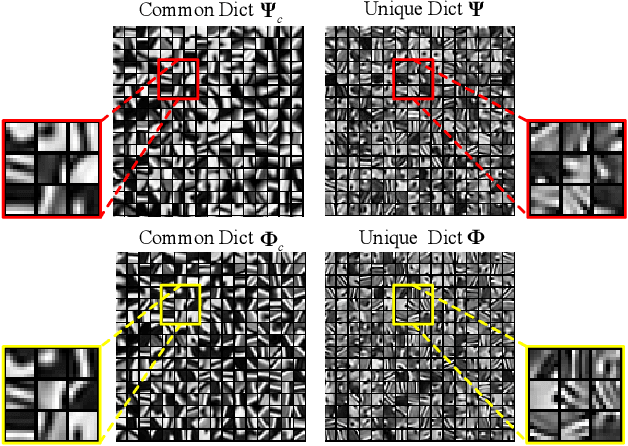
Multimodal Image Denoising based on Coupled Dictionary Learning
Jun 26, 2018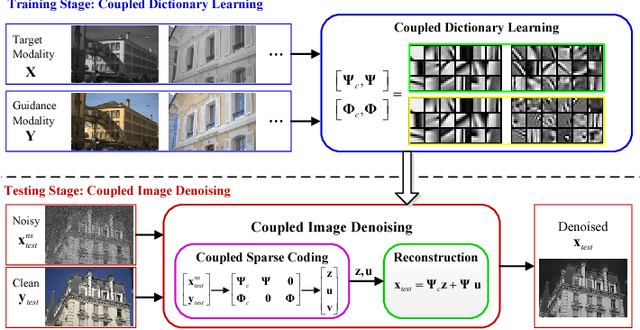

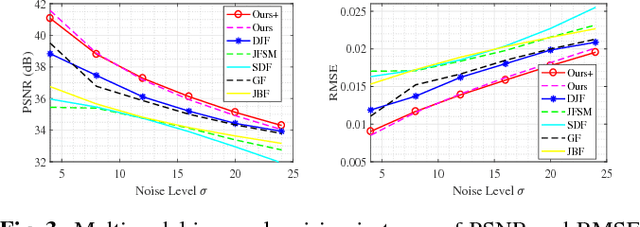
In this paper, we propose a new multimodal image denoising approach to attenuate white Gaussian additive noise in a given image modality under the aid of a guidance image modality. The proposed coupled image denoising approach consists of two stages: coupled sparse coding and reconstruction. The first stage performs joint sparse transform for multimodal images with respect to a group of learned coupled dictionaries, followed by a shrinkage operation on the sparse representations. Then, in the second stage, the shrunken representations, together with coupled dictionaries, contribute to the reconstruction of the denoised image via an inverse transform. The proposed denoising scheme demonstrates the capability to capture both the common and distinct features of different data modalities. This capability makes our approach more robust to inconsistencies between the guidance and the target images, thereby overcoming drawbacks such as the texture copying artifacts. Experiments on real multimodal images demonstrate that the proposed approach is able to better employ guidance information to bring notable benefits in the image denoising task with respect to the state-of-the-art.
Multi-modal Image Processing based on Coupled Dictionary Learning
Jun 26, 2018
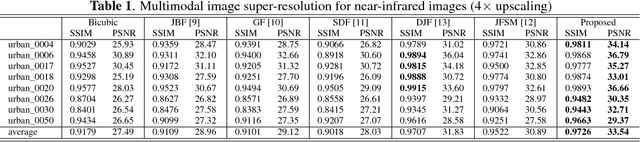


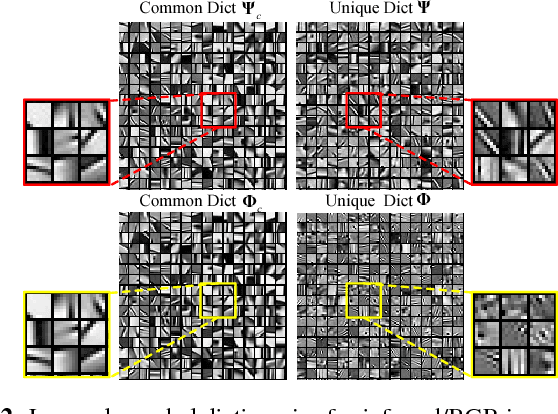
In real-world scenarios, many data processing problems often involve heterogeneous images associated with different imaging modalities. Since these multimodal images originate from the same phenomenon, it is realistic to assume that they share common attributes or characteristics. In this paper, we propose a multi-modal image processing framework based on coupled dictionary learning to capture similarities and disparities between different image modalities. In particular, our framework can capture favorable structure similarities across different image modalities such as edges, corners, and other elementary primitives in a learned sparse transform domain, instead of the original pixel domain, that can be used to improve a number of image processing tasks such as denoising, inpainting, or super-resolution. Practical experiments demonstrate that incorporating multimodal information using our framework brings notable benefits.
Multimodal Image Super-resolution via Joint Sparse Representations induced by Coupled Dictionaries
Mar 08, 2018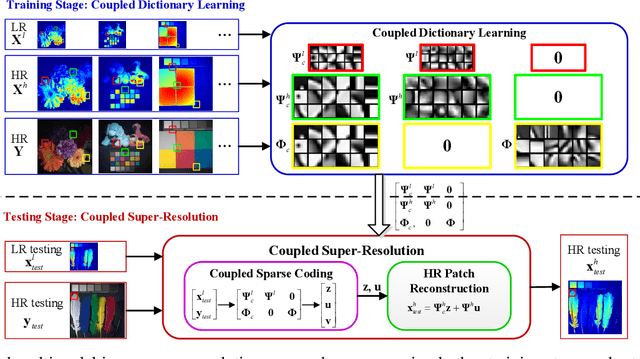


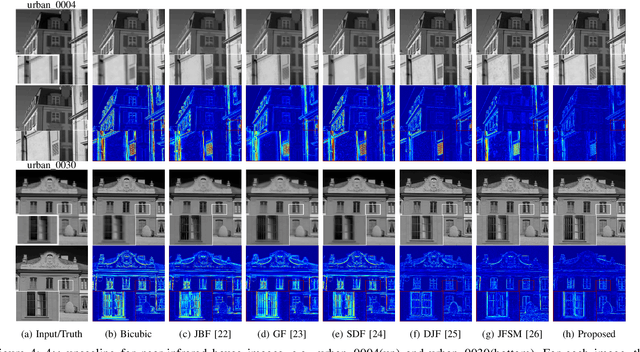
Real-world data processing problems often involve various image modalities associated with a certain scene, including RGB images, infrared images or multi-spectral images. The fact that different image modalities often share certain attributes, such as certain edges, textures and other structure primitives, represents an opportunity to enhance various image processing tasks. This paper proposes a new approach to construct a high-resolution (HR) version of a low-resolution (LR) image given another HR image modality as reference, based on joint sparse representations induced by coupled dictionaries. Our approach, which captures the similarities and disparities between different image modalities in a learned sparse feature domain in \emph{lieu} of the original image domain, consists of two phases. The coupled dictionary learning phase is used to learn a set of dictionaries that couple different image modalities in the sparse feature domain given a set of training data. In turn, the coupled super-resolution phase leverages such coupled dictionaries to construct a HR version of the LR target image given another related image modality. One of the merits of our sparsity-driven approach relates to the fact that it overcomes drawbacks such as the texture copying artifacts commonly resulting from inconsistency between the guidance and target images. Experiments on real multimodal images demonstrate that incorporating appropriate guidance information via joint sparse representation induced by coupled dictionary learning brings notable benefits in the super-resolution task with respect to the state-of-the-art. Of particular relevance, the proposed approach also demonstrates better robustness than competing deep-learning-based methods in the presence of noise.