 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Maps : Using the Semigroup Property for Parameter Tuning
Mar 06, 2022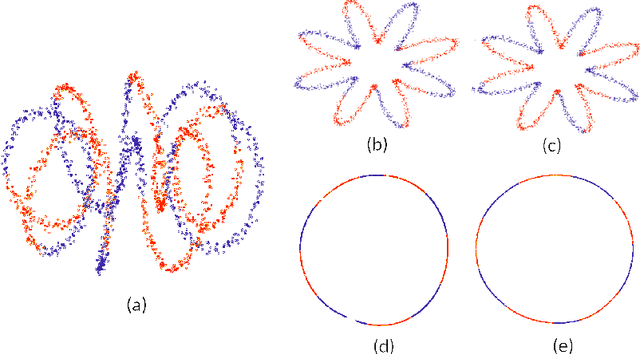


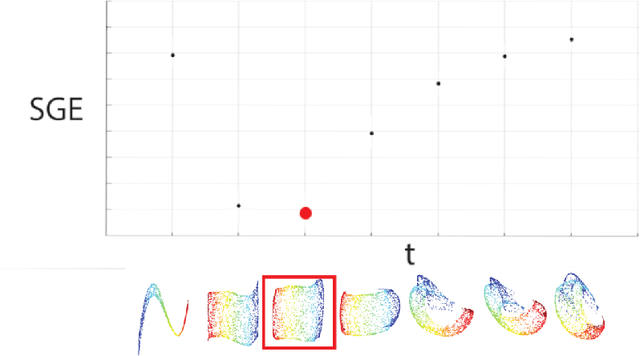
Diffusion maps (DM) constitute a classic dimension reduction technique, for data lying on or close to a (relatively) low-dimensional manifold embedded in a much larger dimensional space. The DM procedure consists in constructing a spectral parametrization for the manifold from simulated random walks or diffusion paths on the data set. However, DM is hard to tune in practice. In particular, the task to set a diffusion time t when constructing the diffusion kernel matrix is critical. We address this problem by using the semigroup property of the diffusion operator. We propose a semigroup criterion for picking t. Experiments show that this principled approach is effective and robust.
Mixed X-Ray Image Separation for Artworks with Concealed Designs
Jan 23, 2022
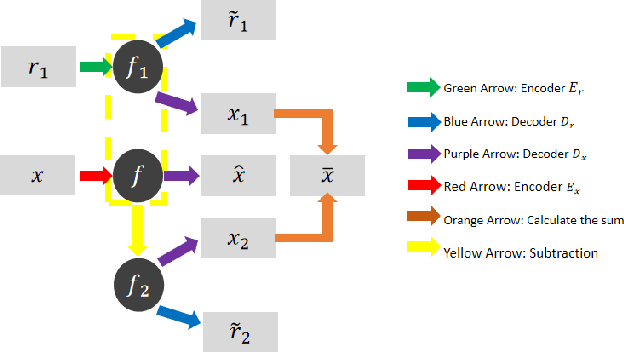
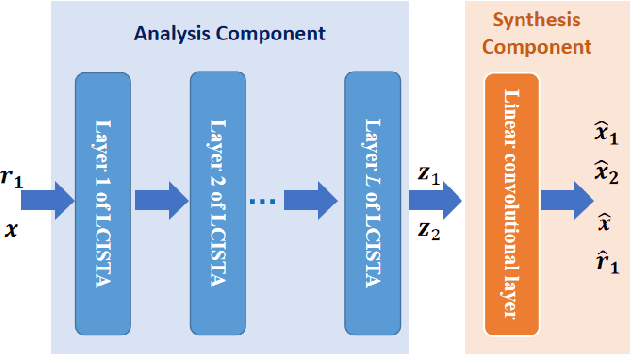
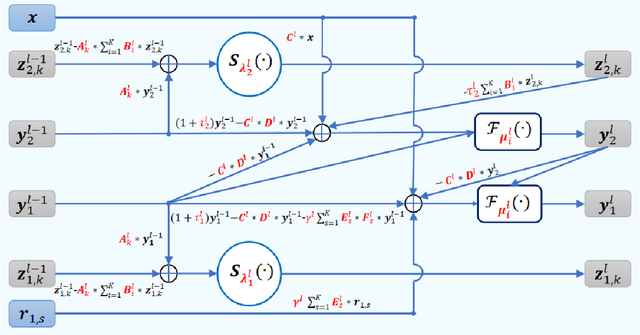
In this paper, we focus on X-ray images of paintings with concealed sub-surface designs (e.g., deriving from reuse of the painting support or revision of a composition by the artist), which include contributions from both the surface painting and the concealed features. In particular, we propose a self-supervised deep learning-based image separation approach that can be applied to the X-ray images from such paintings to separate them into two hypothetical X-ray images. One of these reconstructed images is related to the X-ray image of the concealed painting, while the second one contains only information related to the X-ray of the visible painting. The proposed separation network consists of two components: the analysis and the synthesis sub-networks. The analysis sub-network is based on learned coupled iterative shrinkage thresholding algorithms (LCISTA) designed using algorithm unrolling techniques, and the synthesis sub-network consists of several linear mappings. The learning algorithm operates in a totally self-supervised fashion without requiring a sample set that contains both the mixed X-ray images and the separated ones. The proposed method is demonstrated on a real painting with concealed content, Do\~na Isabel de Porcel by Francisco de Goya, to show its effectiveness.
Neural Network Approximation of Refinable Functions
Jul 28, 2021
In the desire to quantify the success of neural networks in deep learning and other applications, there is a great interest in understanding which functions are efficiently approximated by the outputs of neural networks. By now, there exists a variety of results which show that a wide range of functions can be approximated with sometimes surprising accuracy by these outputs. For example, it is known that the set of functions that can be approximated with exponential accuracy (in terms of the number of parameters used) includes, on one hand, very smooth functions such as polynomials and analytic functions (see e.g. \cite{E,S,Y}) and, on the other hand, very rough functions such as the Weierstrass function (see e.g. \cite{EPGB,DDFHP}), which is nowhere differentiable. In this paper, we add to the latter class of rough functions by showing that it also includes refinable functions. Namely, we show that refinable functions are approximated by the outputs of deep ReLU networks with a fixed width and increasing depth with accuracy exponential in terms of their number of parameters. Our results apply to functions used in the standard construction of wavelets as well as to functions constructed via subdivision algorithms in Computer Aided Geometric Design.
Image Separation with Side Information: A Connected Auto-Encoders Based Approach
Sep 16, 2020
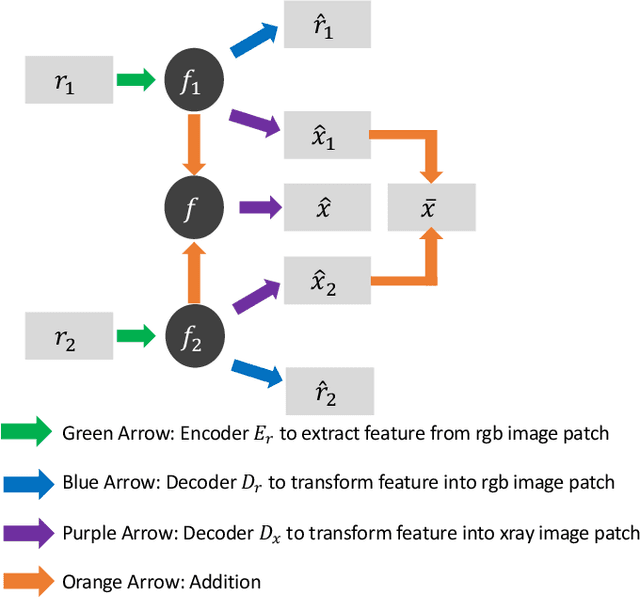
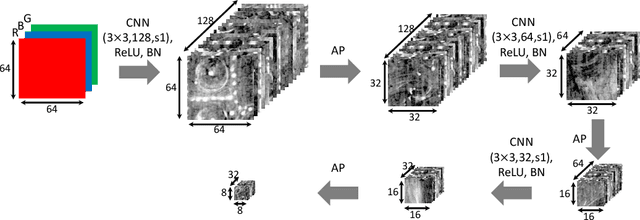
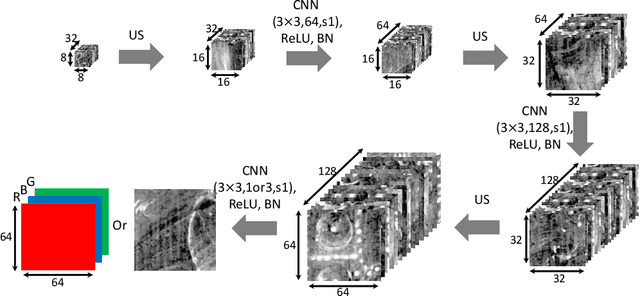
X-radiography (X-ray imaging) is a widely used imaging technique in art investigation. It can provide information about the condition of a painting as well as insights into an artist's techniques and working methods, often revealing hidden information invisible to the naked eye. In this paper, we deal with the problem of separating mixed X-ray images originating from the radiography of double-sided paintings. Using the visible color images (RGB images) from each side of the painting, we propose a new Neural Network architecture, based upon 'connected' auto-encoders, designed to separate the mixed X-ray image into two simulated X-ray images corresponding to each side. In this proposed architecture, the convolutional auto encoders extract features from the RGB images. These features are then used to (1) reproduce both of the original RGB images, (2) reconstruct the hypothetical separated X-ray images, and (3) regenerate the mixed X-ray image. The algorithm operates in a totally self-supervised fashion without requiring a sample set that contains both the mixed X-ray images and the separated ones. The methodology was tested on images from the double-sided wing panels of the \textsl{Ghent Altarpiece}, painted in 1432 by the brothers Hubert and Jan van Eyck. These tests show that the proposed approach outperforms other state-of-the-art X-ray image separation methods for art investigation applications.
Approximating the Riemannian Metric from Point Clouds via Manifold Moving Least Squares
Jul 20, 2020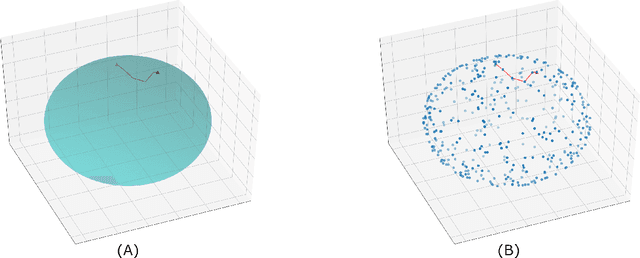

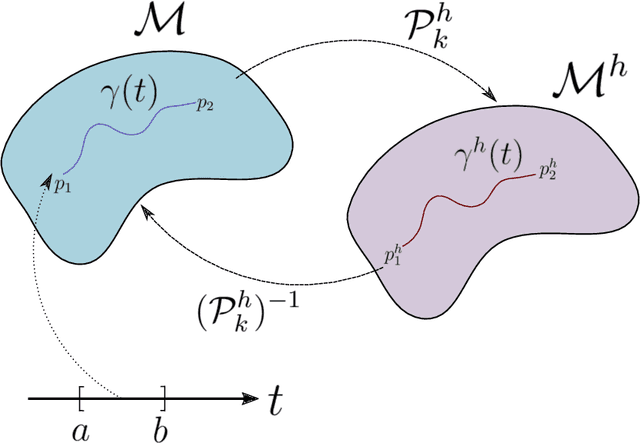

The approximation of both geodesic distances and shortest paths on point cloud sampled from an embedded submanifold $\mathcal{M}$ of Euclidean space has been a long-standing challenge in computational geometry. Given a sampling resolution parameter $ h $, state-of-the-art discrete methods yield $ O(h^2) $ approximations at most. In this paper, we investigate the convergence of such approximations made by Manifold Moving Least-Squares (Manifold-MLS), a method that constructs an approximating manifold $\mathcal{M}^h$ using information from a given point cloud that was developed by Sober \& Levin in 2019 . They showed that the Manifold-MLS procedure approximates the original manifold with approximation order of $ O(h^{k})$ provided that the original manifold $\mathcal{M} \in C^{k}$ is closed, i.e. $\mathcal{M}$ is a compact manifold without boundary. In this paper, we show that under the same conditions, the Riemannian metric of $ \mathcal{M}^h $ approximates the Riemannian metric of $ \mathcal{M}, $; i.e., $\mathcal{M}$ is nearly isometric to $\mathcal{M}^h$. Explicitly, given points $ p_1, p_2 \in \mathcal{M} $ with geodesic distance $ \rho_{\mathcal{M}}(p_1, p_2) $, we show that their corresponding points $ p_1^h, p_2^h \in \mathcal{M}^h $ have a geodesic distance of $ \rho_{\mathcal{M}^h}(p_1^h,p_2^h) = \rho_{\mathcal{M}}(p_1, p_2) + O(h^{k-1}) $. We then use this result, as well as the fact that $ \mathcal{M}^h $ can be sampled with any desired resolution, to devise a naive algorithm that yields approximate geodesic distances with rate of convergence $ O(h^{k-1}) $. We show the potential and the robustness to noise of the proposed method on some numerical simulations.
Expression of Fractals Through Neural Network Functions
May 27, 2019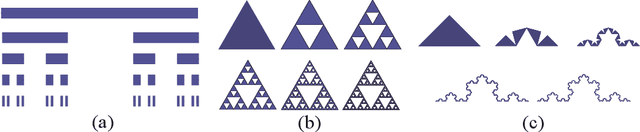
To help understand the underlying mechanisms of neural networks (NNs), several groups have, in recent years, studied the number of linear regions $\ell$ of piecewise linear functions generated by deep neural networks (DNN). In particular, they showed that $\ell$ can grow exponentially with the number of network parameters $p$, a property often used to explain the advantages of DNNs over shallow NNs in approximating complicated functions. Nonetheless, a simple dimension argument shows that DNNs cannot generate all piecewise linear functions with $\ell$ linear regions as soon as $\ell > p$. It is thus natural to seek to characterize specific families of functions with $\ell$ linear regions that can be constructed by DNNs. Iterated Function Systems (IFS) generate sequences of piecewise linear functions $F_k$ with a number of linear regions exponential in $k$. We show that, under mild assumptions, $F_k$ can be generated by a NN using only $\mathcal{O}(k)$ parameters. IFS are used extensively to generate, at low computational cost, natural-looking landscape textures in artificial images. They have also been proposed for compression of natural images, albeit with less commercial success. The surprisingly good performance of this fractal-based compression suggests that our visual system may lock in, to some extent, on self-similarities in images. The combination of this phenomenon with the capacity, demonstrated here, of DNNs to efficiently approximate IFS may contribute to the success of DNNs, particularly striking for image processing tasks, as well as suggest new algorithms for representing self similarities in images based on the DNN mechanism.
Stop memorizing: A data-dependent regularization framework for intrinsic pattern learning
Sep 23, 2018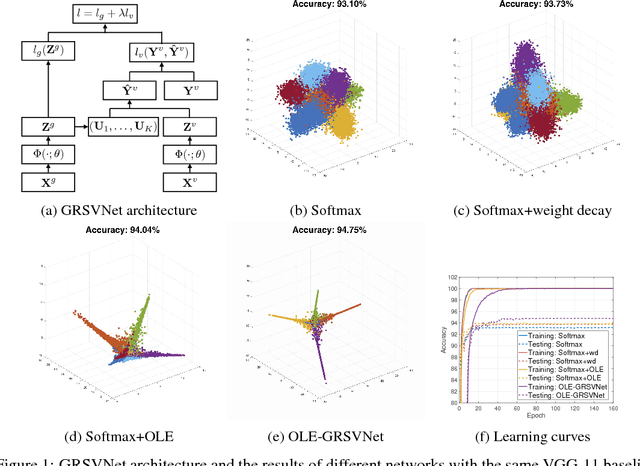
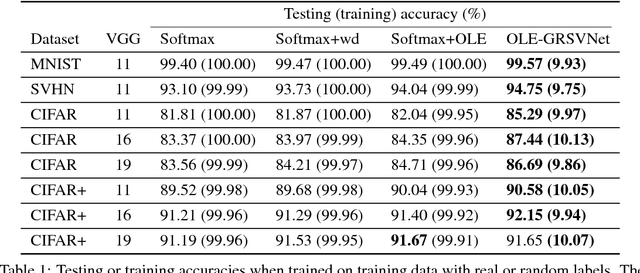
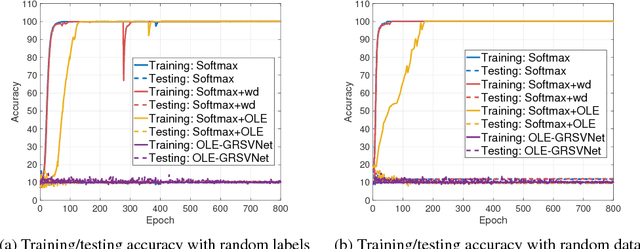
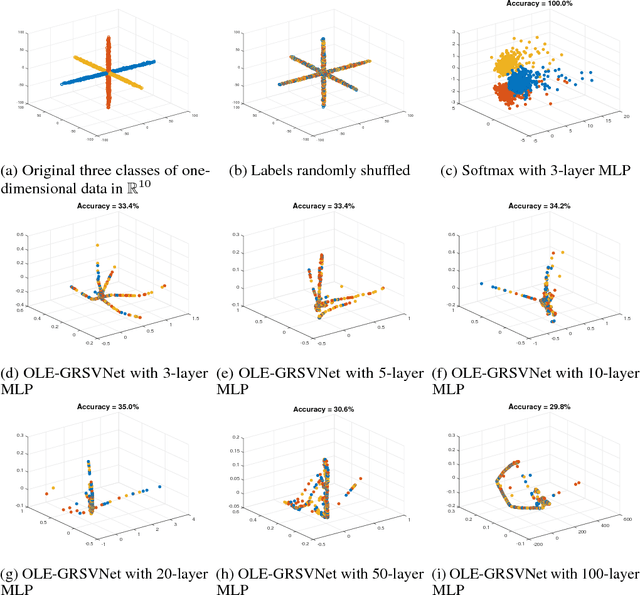
Deep neural networks (DNNs) typically have enough capacity to fit random data by brute force even when conventional data-dependent regularizations focusing on the geometry of the features are imposed. We find out that the reason for this is the inconsistency between the enforced geometry and the standard softmax cross entropy loss. To resolve this, we propose a new framework for data-dependent DNN regularization, the Geometrically-Regularized-Self-Validating neural Networks (GRSVNet). During training, the geometry enforced on one batch of features is simultaneously validated on a separate batch using a validation loss consistent with the geometry. We study a particular case of GRSVNet, the Orthogonal-Low-rank Embedding (OLE)-GRSVNet, which is capable of producing highly discriminative features residing in orthogonal low-rank subspaces. Numerical experiments show that OLE-GRSVNet outperforms DNNs with conventional regularization when trained on real data. More importantly, unlike conventional DNNs, OLE-GRSVNet refuses to memorize random data or random labels, suggesting it only learns intrinsic patterns by reducing the memorizing capacity of the baseline DNN.
Gaussian Process Landmarking on Manifolds
Jul 28, 2018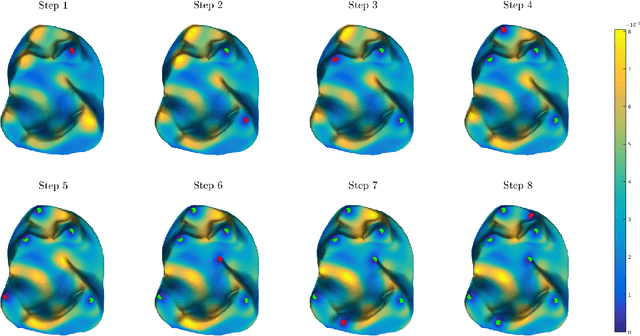
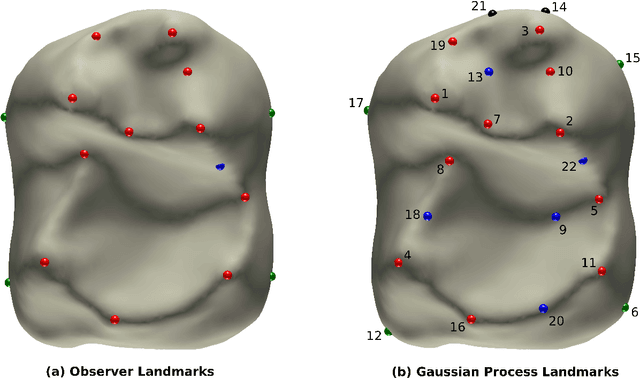
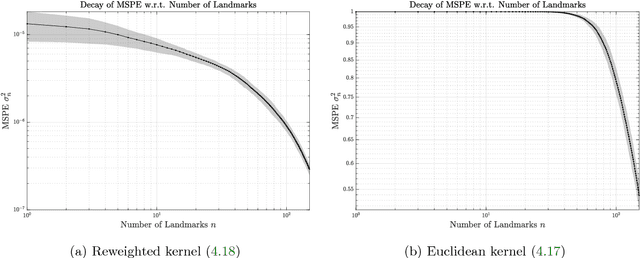
As a means of improving analysis of biological shapes, we propose an algorithm for sampling a Riemannian manifold by sequentially selecting points with maximum uncertainty under a Gaussian process model. This greedy strategy is known to be near-optimal in the experimental design literature, and appears to outperform the use of user-placed landmarks in representing the geometry of biological objects in our application. In the noiseless regime, we establish an upper bound for the mean squared prediction error (MSPE) in terms of the number of samples and geometric quantities of the manifold, demonstrating that the MSPE for our proposed sequential design decays at a rate comparable to the oracle rate achievable by any sequential or non-sequential optimal design; to our knowledge this is the first result of this type for sequential experimental design. The key is to link the greedy algorithm to reduced basis methods in the context of model reduction for partial differential equations. We expect this approach will find additional applications in other fields of research.
Non-Oscillatory Pattern Learning for Non-Stationary Signals
May 22, 2018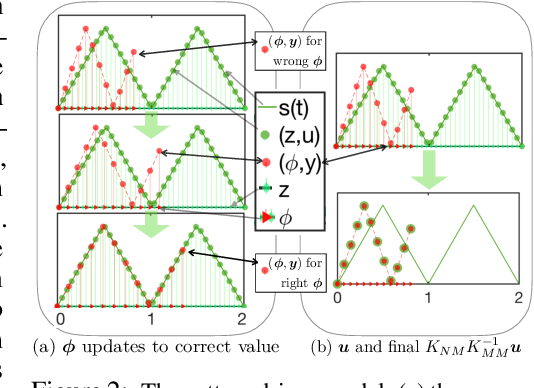
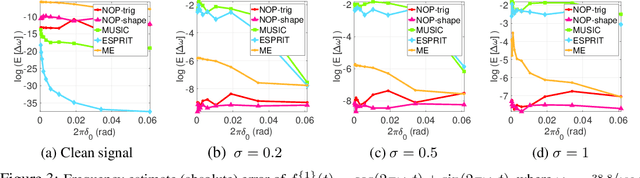
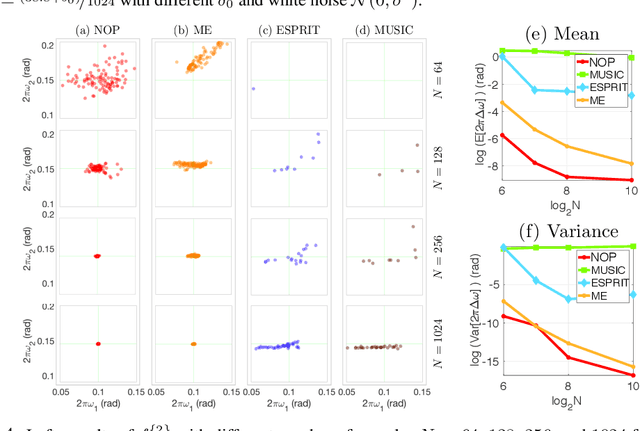
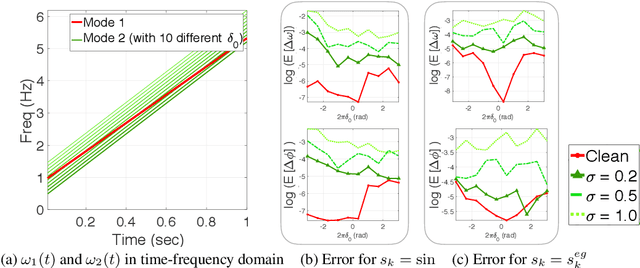
This paper proposes a novel non-oscillatory pattern (NOP) learning scheme for several oscillatory data analysis problems including signal decomposition, super-resolution, and signal sub-sampling. To the best of our knowledge, the proposed NOP is the first algorithm for these problems with fully non-stationary oscillatory data with close and crossover frequencies, and general oscillatory patterns. NOP is capable of handling complicated situations while existing algorithms fail; even in simple cases, e.g., stationary cases with trigonometric patterns, numerical examples show that NOP admits competitive or better performance in terms of accuracy and robustness than several state-of-the-art algorithms.
Identification of Shallow Neural Networks by Fewest Samples
Apr 04, 2018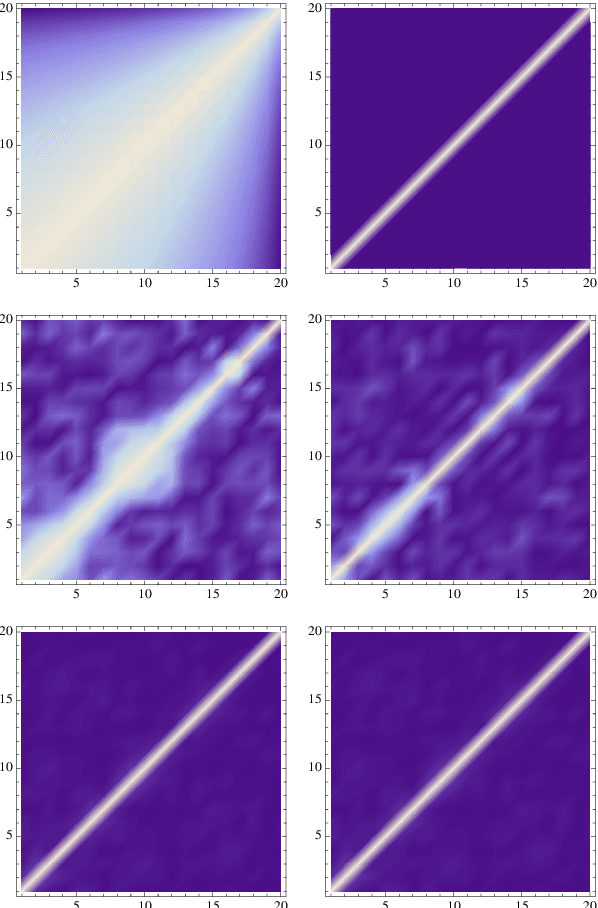
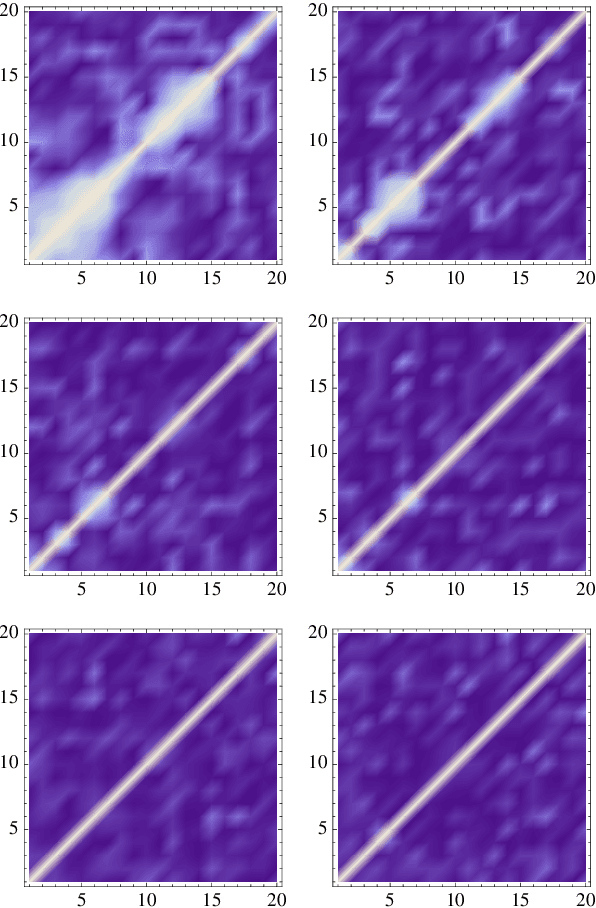
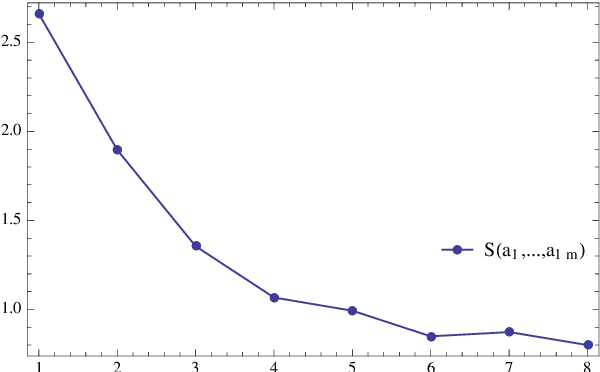
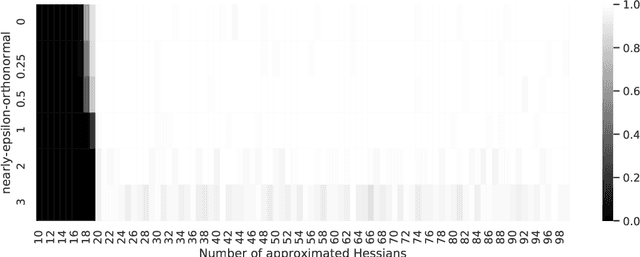
We address the uniform approximation of sums of ridge functions $\sum_{i=1}^m g_i(a_i\cdot x)$ on ${\mathbb R}^d$, representing the shallowest form of feed-forward neural network, from a small number of query samples, under mild smoothness assumptions on the functions $g_i$'s and near-orthogonality of the ridge directions $a_i$'s. The sample points are randomly generated and are universal, in the sense that the sampled queries on those points will allow the proposed recovery algorithms to perform a uniform approximation of any sum of ridge functions with high-probability. Our general approximation strategy is developed as a sequence of algorithms to perform individual sub-tasks. We first approximate the span of the ridge directions. Then we use a straightforward substitution, which reduces the dimensionality of the problem from $d$ to $m$. The core of the construction is then the approximation of ridge directions expressed in terms of rank-$1$ matrices $a_i \otimes a_i$, realized by formulating their individual identification as a suitable nonlinear program, maximizing the spectral norm of certain competitors constrained over the unit Frobenius sphere. The final step is then to approximate the functions $g_1,\dots,g_m$ by $\hat g_1,\dots,\hat g_m$. Higher order differentiation, as used in our construction, of sums of ridge functions or of their compositions, as in deeper neural network, yields a natural connection between neural network weight identification and tensor product decomposition identification. In the case of the shallowest feed-forward neural network, we show that second order differentiation and tensors of order two (i.e., matrices) suffice.