 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeisfeiler-Leman Is Incomplete on Simple Spectrum Graphs, so Canonicalize Them
May 22, 2026Graphs with a simple spectrum admit cubic-time isomorphism testing, yet we prove that for every natural number $k$, the $k$-Weisfeiler-Leman ($k$-WL) test cannot distinguish all non-isomorphic graphs with a simple spectrum. As the WL hierarchy upper-bounds the distinguishing power of widely-used Graph Neural Networks (GNNs), this incompleteness applies to all such GNNs, ruling out completeness for every $k$-WL-aligned GNN family. To close this gap, we introduce PRiSM (Partition, Refine, Solve, Match), the first provably complete canonicalization of simple-spectrum eigendecompositions. PRiSM obtains the completeness guarantee that prior canonicalizations provably lack, and resolves the open problem of achieving complete expressivity on simple-spectrum graphs. When composed with DeepSets or a Transformer, PRiSM achieves universal approximation on simple-spectrum graphs, justifying the use of canonicalized Laplacian positional encodings. Empirically, PRiSM performs comparably to or outperforms existing spectral canonicalizations on graph regression, classification, and expressivity
Quantitative Approximation Rates for Group Equivariant Learning
Feb 23, 2026The universal approximation theorem establishes that neural networks can approximate any continuous function on a compact set. Later works in approximation theory provide quantitative approximation rates for ReLU networks on the class of $α$-Hölder functions $f: [0,1]^N \to \mathbb{R}$. The goal of this paper is to provide similar quantitative approximation results in the context of group equivariant learning, where the learned $α$-Hölder function is known to obey certain group symmetries. While there has been much interest in the literature in understanding the universal approximation properties of equivariant models, very few quantitative approximation results are known for equivariant models. In this paper, we bridge this gap by deriving quantitative approximation rates for several prominent group-equivariant and invariant architectures. The architectures that we consider include: the permutation-invariant Deep Sets architecture; the permutation-equivariant Sumformer and Transformer architectures; joint invariance to permutations and rigid motions using invariant networks based on frame averaging; and general bi-Lipschitz invariant models. Overall, we show that equally-sized ReLU MLPs and equivariant architectures are equally expressive over equivariant functions. Thus, hard-coding equivariance does not result in a loss of expressivity or approximation power in these models.
Transport, Don't Generate: Deterministic Geometric Flows for Combinatorial Optimization
Feb 11, 2026Recent advances in Neural Combinatorial Optimization (NCO) have been dominated by diffusion models that treat the Euclidean Traveling Salesman Problem (TSP) as a stochastic $N \times N$ heatmap generation task. In this paper, we propose CycFlow, a framework that replaces iterative edge denoising with deterministic point transport. CycFlow learns an instance-conditioned vector field that continuously transports input 2D coordinates to a canonical circular arrangement, where the optimal tour is recovered from this $2N$ dimensional representation via angular sorting. By leveraging data-dependent flow matching, we bypass the quadratic bottleneck of edge scoring in favor of linear coordinate dynamics. This paradigm shift accelerates solving speed by up to three orders of magnitude compared to state-of-the-art diffusion baselines, while maintaining competitive optimality gaps.
Toward bilipshiz geometric models
Nov 13, 2025Many neural networks for point clouds are, by design, invariant to the symmetries of this datatype: permutations and rigid motions. The purpose of this paper is to examine whether such networks preserve natural symmetry aware distances on the point cloud spaces, through the notion of bi-Lipschitz equivalence. This inquiry is motivated by recent work in the Equivariant learning literature which highlights the advantages of bi-Lipschitz models in other scenarios. We consider two symmetry aware metrics on point clouds: (a) The Procrustes Matching (PM) metric and (b) Hard Gromov Wasserstien distances. We show that these two distances themselves are not bi-Lipschitz equivalent, and as a corollary deduce that popular invariant networks for point clouds are not bi-Lipschitz with respect to the PM metric. We then show how these networks can be modified so that they do obtain bi-Lipschitz guarantees. Finally, we provide initial experiments showing the advantage of the proposed bi-Lipschitz model over standard invariant models, for the tasks of finding correspondences between 3D point clouds.
Spectral Graph Neural Networks are Incomplete on Graphs with a Simple Spectrum
Jun 05, 2025Spectral features are widely incorporated within Graph Neural Networks (GNNs) to improve their expressive power, or their ability to distinguish among non-isomorphic graphs. One popular example is the usage of graph Laplacian eigenvectors for positional encoding in MPNNs and Graph Transformers. The expressive power of such Spectrally-enhanced GNNs (SGNNs) is usually evaluated via the k-WL graph isomorphism test hierarchy and homomorphism counting. Yet, these frameworks align poorly with the graph spectra, yielding limited insight into SGNNs' expressive power. We leverage a well-studied paradigm of classifying graphs by their largest eigenvalue multiplicity to introduce an expressivity hierarchy for SGNNs. We then prove that many SGNNs are incomplete even on graphs with distinct eigenvalues. To mitigate this deficiency, we adapt rotation equivariant neural networks to the graph spectra setting to propose a method to provably improve SGNNs' expressivity on simple spectrum graphs. We empirically verify our theoretical claims via an image classification experiment on the MNIST Superpixel dataset and eigenvector canonicalization on graphs from ZINC.
On the (Non) Injectivity of Piecewise Linear Janossy Pooling
May 26, 2025Multiset functions, which are functions that map multisets to vectors, are a fundamental tool in the construction of neural networks for multisets and graphs. To guarantee that the vector representation of the multiset is faithful, it is often desirable to have multiset mappings that are both injective and bi-Lipschitz. Currently, there are several constructions of multiset functions achieving both these guarantees, leading to improved performance in some tasks but often also to higher compute time than standard constructions. Accordingly, it is natural to inquire whether simpler multiset functions achieving the same guarantees are available. In this paper, we make a large step towards giving a negative answer to this question. We consider the family of k-ary Janossy pooling, which includes many of the most popular multiset models, and prove that no piecewise linear Janossy pooling function can be injective. On the positive side, we show that when restricted to multisets without multiplicities, even simple deep-sets models suffice for injectivity and bi-Lipschitzness.
The stability of generalized phase retrieval problem over compact groups
May 07, 2025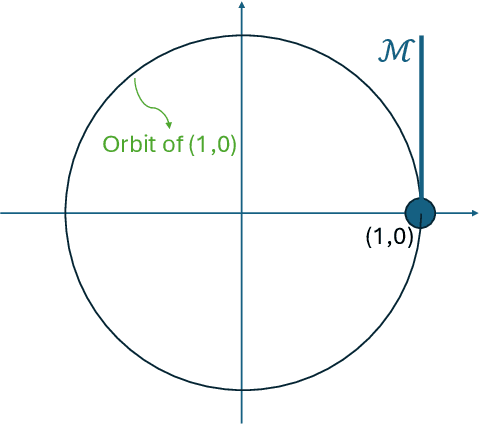
The generalized phase retrieval problem over compact groups aims to recover a set of matrices, representing an unknown signal, from their associated Gram matrices, leveraging prior structural knowledge about the signal. This framework generalizes the classical phase retrieval problem, which reconstructs a signal from the magnitudes of its Fourier transform, to a richer setting involving non-abelian compact groups. In this broader context, the unknown phases in Fourier space are replaced by unknown orthogonal matrices that arise from the action of a compact group on a finite-dimensional vector space. This problem is primarily motivated by advances in electron microscopy to determining the 3D structure of biological macromolecules from highly noisy observations. To capture realistic assumptions from machine learning and signal processing, we model the signal as belonging to one of several broad structural families: a generic linear subspace, a sparse representation in a generic basis, the output of a generic ReLU neural network, or a generic low-dimensional manifold. Our main result shows that, under mild conditions, the generalized phase retrieval problem not only admits a unique solution (up to inherent group symmetries), but also satisfies a bi-Lipschitz property. This implies robustness to both noise and model mismatch, an essential requirement for practical use, especially when measurements are severely corrupted by noise. These findings provide theoretical support for a wide class of scientific problems under modern structural assumptions, and they offer strong foundations for developing robust algorithms in high-noise regimes.
Fourier Sliced-Wasserstein Embedding for Multisets and Measures
Apr 03, 2025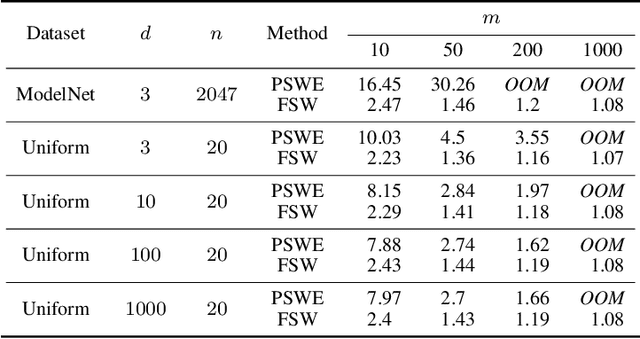
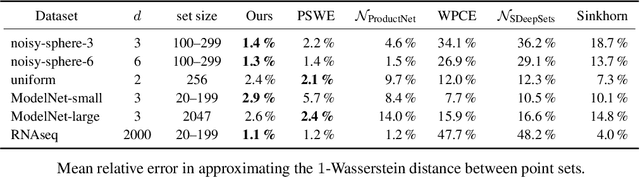
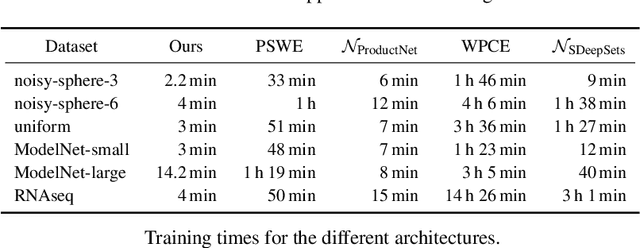
We present the Fourier Sliced-Wasserstein (FSW) embedding - a novel method to embed multisets and measures over $\mathbb{R}^d$ into Euclidean space. Our proposed embedding approximately preserves the sliced Wasserstein distance on distributions, thereby yielding geometrically meaningful representations that better capture the structure of the input. Moreover, it is injective on measures and bi-Lipschitz on multisets - a significant advantage over prevalent methods based on sum- or max-pooling, which are provably not bi-Lipschitz, and, in many cases, not even injective. The required output dimension for these guarantees is near-optimal: roughly $2 N d$, where $N$ is the maximal input multiset size. Furthermore, we prove that it is impossible to embed distributions over $\mathbb{R}^d$ into Euclidean space in a bi-Lipschitz manner. Thus, the metric properties of our embedding are, in a sense, the best possible. Through numerical experiments, we demonstrate that our method yields superior multiset representations that improve performance in practical learning tasks. Specifically, we show that (a) a simple combination of the FSW embedding with an MLP achieves state-of-the-art performance in learning the (non-sliced) Wasserstein distance; and (b) replacing max-pooling with the FSW embedding makes PointNet significantly more robust to parameter reduction, with only minor performance degradation even after a 40-fold reduction.
Bi-Lipschitz Ansatz for Anti-Symmetric Functions
Mar 06, 2025Motivated by applications for simulating quantum many body functions, we propose a new universal ansatz for approximating anti-symmetric functions. The main advantage of this ansatz over previous alternatives is that it is bi-Lipschitz with respect to a naturally defined metric. As a result, we are able to obtain quantitative approximation results for approximation of Lipschitz continuous antisymmetric functions. Moreover, we provide preliminary experimental evidence to the improved performance of this ansatz for learning antisymmetric functions.
FSW-GNN: A Bi-Lipschitz WL-Equivalent Graph Neural Network
Oct 10, 2024Many of the most popular graph neural networks fall into the category of message-passing neural networks (MPNNs). Famously, MPNNs' ability to distinguish between graphs is limited to graphs separable by the Weisfeiler-Lemann (WL) graph isomorphism test, and the strongest MPNNs, in terms of separation power, are WL-equivalent. Recently, it was shown that the quality of separation provided by standard WL-equivalent MPNN can be very low, resulting in WL-separable graphs being mapped to very similar, hardly distinguishable features. This paper addresses this issue by seeking bi-Lipschitz continuity guarantees for MPNNs. We demonstrate that, in contrast with standard summation-based MPNNs, which lack bi-Lipschitz properties, our proposed model provides a bi-Lipschitz graph embedding with respect to two standard graph metrics. Empirically, we show that our MPNN is competitive with standard MPNNs for several graph learning tasks and is far more accurate in over-squashing long-range tasks.