 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LLM Predictions via Inter-Layer Structural Encoders
Mar 24, 2026The standard practice in Large Language Models (LLMs) is to base predictions on the final-layer token representations. Recent studies, however, show that intermediate layers encode substantial information, which may contain more task-relevant features than the final-layer representations alone. Importantly, it was shown that for different tasks, different layers may be optimal. In this work we introduce Inter-Layer Structural Encoders (ILSE), a powerful structural approach to learn one effective representation from the LLM's internal layer representations all together. Central to ILSE is Cayley-Encoder, a mathematically grounded geometric encoder that leverages expander Cayley graphs for efficient inter-layer information propagation. We evaluate ILSE across 13 classification and semantic similarity tasks with 9 pre-trained LLMs ranging from 14 million to 8 billion parameters. ILSE consistently outperforms baselines and existing approaches, achieving up to 44% improvement in accuracy and 25% in similarity metrics. We further show that ILSE is data-efficient in few-shot regimes and can make small LLMs competitive with substantially larger models.
A Graph Meta-Network for Learning on Kolmogorov-Arnold Networks
Feb 18, 2026Weight-space models learn directly from the parameters of neural networks, enabling tasks such as predicting their accuracy on new datasets. Naive methods -- like applying MLPs to flattened parameters -- perform poorly, making the design of better weight-space architectures a central challenge. While prior work leveraged permutation symmetries in standard networks to guide such designs, no analogous analysis or tailored architecture yet exists for Kolmogorov-Arnold Networks (KANs). In this work, we show that KANs share the same permutation symmetries as MLPs, and propose the KAN-graph, a graph representation of their computation. Building on this, we develop WS-KAN, the first weight-space architecture that learns on KANs, which naturally accounts for their symmetry. We analyze WS-KAN's expressive power, showing it can replicate an input KAN's forward pass - a standard approach for assessing expressiveness in weight-space architectures. We construct a comprehensive ``zoo'' of trained KANs spanning diverse tasks, which we use as benchmarks to empirically evaluate WS-KAN. Across all tasks, WS-KAN consistently outperforms structure-agnostic baselines, often by a substantial margin. Our code is available at https://github.com/BarSGuy/KAN-Graph-Metanetwork.
Billion-Scale Graph Foundation Models
Feb 04, 2026Graph-structured data underpins many critical applications. While foundation models have transformed language and vision via large-scale pretraining and lightweight adaptation, extending this paradigm to general, real-world graphs is challenging. In this work, we present Graph Billion- Foundation-Fusion (GraphBFF): the first end-to-end recipe for building billion-parameter Graph Foundation Models (GFMs) for arbitrary heterogeneous, billion-scale graphs. Central to the recipe is the GraphBFF Transformer, a flexible and scalable architecture designed for practical billion-scale GFMs. Using the GraphBFF, we present the first neural scaling laws for general graphs and show that loss decreases predictably as either model capacity or training data scales, depending on which factor is the bottleneck. The GraphBFF framework provides concrete methodologies for data batching, pretraining, and fine-tuning for building GFMs at scale. We demonstrate the effectiveness of the framework with an evaluation of a 1.4 billion-parameter GraphBFF Transformer pretrained on one billion samples. Across ten diverse, real-world downstream tasks on graphs unseen during training, spanning node- and link-level classification and regression, GraphBFF achieves remarkable zero-shot and probing performance, including in few-shot settings, with large margins of up to 31 PRAUC points. Finally, we discuss key challenges and open opportunities for making GFMs a practical and principled foundation for graph learning at industrial scale.
Spectral Graph Neural Networks are Incomplete on Graphs with a Simple Spectrum
Jun 05, 2025Spectral features are widely incorporated within Graph Neural Networks (GNNs) to improve their expressive power, or their ability to distinguish among non-isomorphic graphs. One popular example is the usage of graph Laplacian eigenvectors for positional encoding in MPNNs and Graph Transformers. The expressive power of such Spectrally-enhanced GNNs (SGNNs) is usually evaluated via the k-WL graph isomorphism test hierarchy and homomorphism counting. Yet, these frameworks align poorly with the graph spectra, yielding limited insight into SGNNs' expressive power. We leverage a well-studied paradigm of classifying graphs by their largest eigenvalue multiplicity to introduce an expressivity hierarchy for SGNNs. We then prove that many SGNNs are incomplete even on graphs with distinct eigenvalues. To mitigate this deficiency, we adapt rotation equivariant neural networks to the graph spectra setting to propose a method to provably improve SGNNs' expressivity on simple spectrum graphs. We empirically verify our theoretical claims via an image classification experiment on the MNIST Superpixel dataset and eigenvector canonicalization on graphs from ZINC.
Interpretable Graph Learning Over Sets of Temporally-Sparse Data
May 25, 2025Real-world medical data often includes measurements from multiple signals that are collected at irregular and asynchronous time intervals. For example, different types of blood tests can be measured at different times and frequencies, resulting in fragmented and unevenly scattered temporal data. Similar issues of irregular sampling of different attributes occur in other domains, such as monitoring of large systems using event log files or the spread of fake news on social networks. Effectively learning from such data requires models that can handle sets of temporally sparse and heterogeneous signals. In this paper, we propose Graph Mixing Additive Networks (GMAN), a novel and interpretable-by-design model for learning over irregular sets of temporal signals. Our method achieves state-of-the-art performance in real-world medical tasks, including a 4-point increase in the AUROC score of in-hospital mortality prediction, compared to existing methods. We further showcase GMAN's flexibility by applying it to a fake news detection task. We demonstrate how its interpretability capabilities, including node-level, graph-level, and subset-level importance, allow for transition phases detection and gaining medical insights with real-world high-stakes implications. Finally, we provide theoretical insights on GMAN expressive power.
Identifying Critical Phases for Disease Onset with Sparse Haematological Biomarkers
Mar 18, 2025Routinely collected clinical blood tests are an emerging molecular data source for large-scale biomedical research but inherently feature irregular sampling and informative observation. Traditional approaches rely on imputation, which can distort learning signals and bias predictions while lacking biological interpretability. We propose a novel methodology using Graph Neural Additive Networks (GNAN) to model biomarker trajectories as time-weighted directed graphs, where nodes represent sampling events and edges encode the time delta between events. GNAN's additive structure enables the explicit decomposition of feature and temporal contributions, allowing the detection of critical disease-associated time points. Unlike conventional imputation-based approaches, our method preserves the temporal structure of sparse data without introducing artificial biases and provides inherently interpretable predictions by decomposing contributions from each biomarker and time interval. This makes our model clinically applicable, as well as allowing it to discover biologically meaningful disease signatures.
Depth-Width tradeoffs in Algorithmic Reasoning of Graph Tasks with Transformers
Mar 03, 2025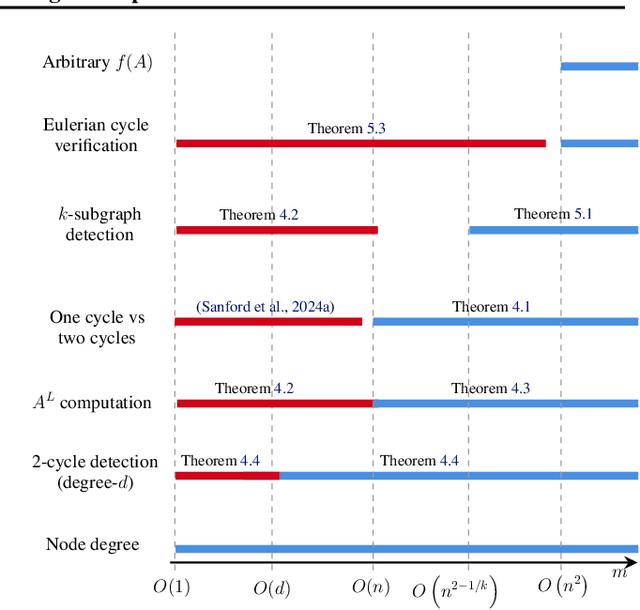

Transformers have revolutionized the field of machine learning. In particular, they can be used to solve complex algorithmic problems, including graph-based tasks. In such algorithmic tasks a key question is what is the minimal size of a transformer that can implement a task. Recent work has begun to explore this problem for graph-based tasks, showing that for sub-linear embedding dimension (i.e., model width) logarithmic depth suffices. However, an open question, which we address here, is what happens if width is allowed to grow linearly. Here we analyze this setting, and provide the surprising result that with linear width, constant depth suffices for solving a host of graph-based problems. This suggests that a moderate increase in width can allow much shallower models, which are advantageous in terms of inference time. For other problems, we show that quadratic width is required. Our results demonstrate the complex and intriguing landscape of transformer implementations of graph-based algorithms. We support our theoretical results with empirical evaluations.
Position: Graph Learning Will Lose Relevance Due To Poor Benchmarks
Feb 20, 2025
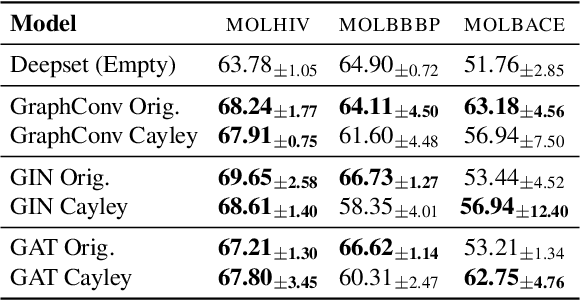
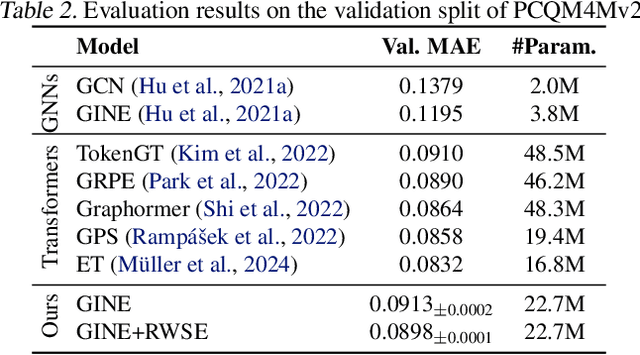
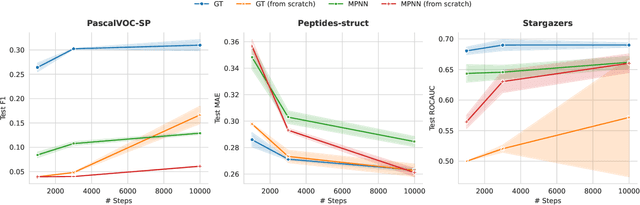
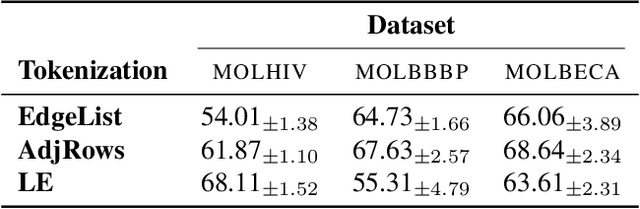
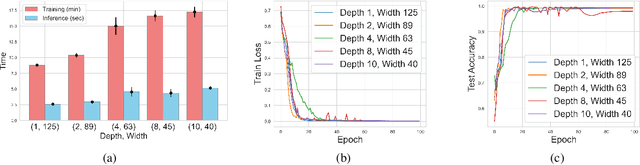
While machine learning on graphs has demonstrated promise in drug design and molecular property prediction, significant benchmarking challenges hinder its further progress and relevance. Current benchmarking practices often lack focus on transformative, real-world applications, favoring narrow domains like two-dimensional molecular graphs over broader, impactful areas such as combinatorial optimization, relational databases, or chip design. Additionally, many benchmark datasets poorly represent the underlying data, leading to inadequate abstractions and misaligned use cases. Fragmented evaluations and an excessive focus on accuracy further exacerbate these issues, incentivizing overfitting rather than fostering generalizable insights. These limitations have prevented the development of truly useful graph foundation models. This position paper calls for a paradigm shift toward more meaningful benchmarks, rigorous evaluation protocols, and stronger collaboration with domain experts to drive impactful and reliable advances in graph learning research, unlocking the potential of graph learning.
Towards Invariance to Node Identifiers in Graph Neural Networks
Feb 19, 2025Message-Passing Graph Neural Networks (GNNs) are known to have limited expressive power, due to their message passing structure. One mechanism for circumventing this limitation is to add unique node identifiers (IDs), which break the symmetries that underlie the expressivity limitation. In this work, we highlight a key limitation of the ID framework, and propose an approach for addressing it. We begin by observing that the final output of the GNN should clearly not depend on the specific IDs used. We then show that in practice this does not hold, and thus the learned network does not possess this desired structural property. Such invariance to node IDs may be enforced in several ways, and we discuss their theoretical properties. We then propose a novel regularization method that effectively enforces ID invariance to the network. Extensive evaluations on both real-world and synthetic tasks demonstrate that our approach significantly improves ID invariance and, in turn, often boosts generalization performance.
On the Utilization of Unique Node Identifiers in Graph Neural Networks
Nov 04, 2024Graph neural networks have inherent representational limitations due to their message-passing structure. Recent work has suggested that these limitations can be overcome by using unique node identifiers (UIDs). Here we argue that despite the advantages of UIDs, one of their disadvantages is that they lose the desirable property of permutation-equivariance. We thus propose to focus on UID models that are permutation-equivariant, and present theoretical arguments for their advantages. Motivated by this, we propose a method to regularize UID models towards permutation equivariance, via a contrastive loss. We empirically demonstrate that our approach improves generalization and extrapolation abilities while providing faster training convergence. On the recent BREC expressiveness benchmark, our proposed method achieves state-of-the-art performance compared to other random-based approaches.