 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Data Pecking: A Context-Aware Approach for Automated Quality Evaluation of Structured Medical Data
Jul 03, 2025



Background: The use of Electronic Health Records (EHRs) for epidemiological studies and artificial intelligence (AI) training is increasing rapidly. The reliability of the results depends on the accuracy and completeness of EHR data. However, EHR data often contain significant quality issues, including misrepresentations of subpopulations, biases, and systematic errors, as they are primarily collected for clinical and billing purposes. Existing quality assessment methods remain insufficient, lacking systematic procedures to assess data fitness for research. Methods: We present the Medical Data Pecking approach, which adapts unit testing and coverage concepts from software engineering to identify data quality concerns. We demonstrate our approach using the Medical Data Pecking Tool (MDPT), which consists of two main components: (1) an automated test generator that uses large language models and grounding techniques to create a test suite from data and study descriptions, and (2) a data testing framework that executes these tests, reporting potential errors and coverage. Results: We evaluated MDPT on three datasets: All of Us (AoU), MIMIC-III, and SyntheticMass, generating 55-73 tests per cohort across four conditions. These tests correctly identified 20-43 non-aligned or non-conforming data issues. We present a detailed analysis of the LLM-generated test suites in terms of reference grounding and value accuracy. Conclusion: Our approach incorporates external medical knowledge to enable context-sensitive data quality testing as part of the data analysis workflow to improve the validity of its outcomes. Our approach tackles these challenges from a quality assurance perspective, laying the foundation for further development such as additional data modalities and improved grounding methods.
Interpretable Graph Learning Over Sets of Temporally-Sparse Data
May 25, 2025Real-world medical data often includes measurements from multiple signals that are collected at irregular and asynchronous time intervals. For example, different types of blood tests can be measured at different times and frequencies, resulting in fragmented and unevenly scattered temporal data. Similar issues of irregular sampling of different attributes occur in other domains, such as monitoring of large systems using event log files or the spread of fake news on social networks. Effectively learning from such data requires models that can handle sets of temporally sparse and heterogeneous signals. In this paper, we propose Graph Mixing Additive Networks (GMAN), a novel and interpretable-by-design model for learning over irregular sets of temporal signals. Our method achieves state-of-the-art performance in real-world medical tasks, including a 4-point increase in the AUROC score of in-hospital mortality prediction, compared to existing methods. We further showcase GMAN's flexibility by applying it to a fake news detection task. We demonstrate how its interpretability capabilities, including node-level, graph-level, and subset-level importance, allow for transition phases detection and gaining medical insights with real-world high-stakes implications. Finally, we provide theoretical insights on GMAN expressive power.
Depth-Width tradeoffs in Algorithmic Reasoning of Graph Tasks with Transformers
Mar 03, 2025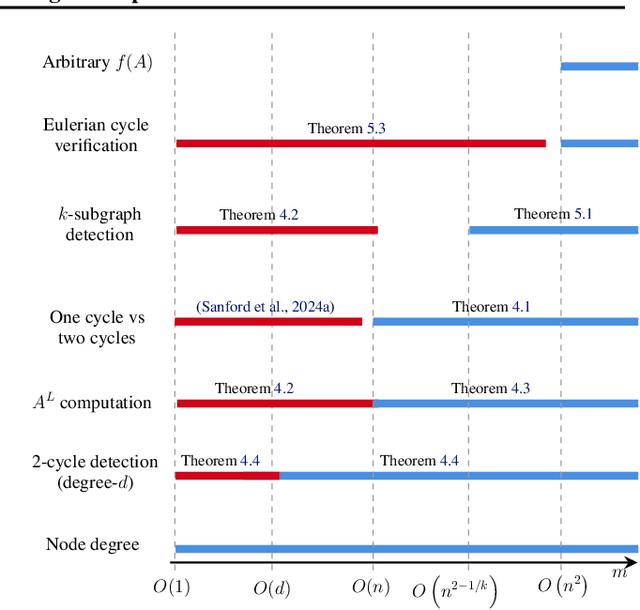
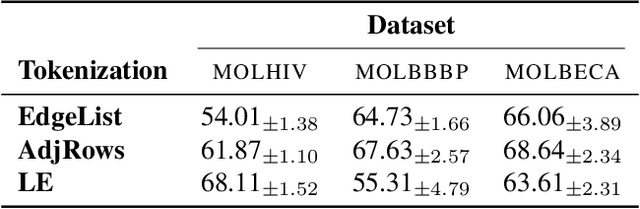
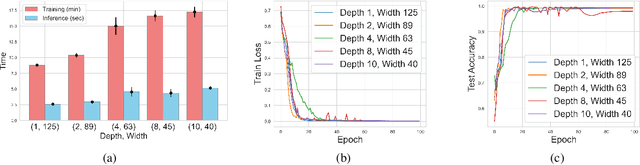

Transformers have revolutionized the field of machine learning. In particular, they can be used to solve complex algorithmic problems, including graph-based tasks. In such algorithmic tasks a key question is what is the minimal size of a transformer that can implement a task. Recent work has begun to explore this problem for graph-based tasks, showing that for sub-linear embedding dimension (i.e., model width) logarithmic depth suffices. However, an open question, which we address here, is what happens if width is allowed to grow linearly. Here we analyze this setting, and provide the surprising result that with linear width, constant depth suffices for solving a host of graph-based problems. This suggests that a moderate increase in width can allow much shallower models, which are advantageous in terms of inference time. For other problems, we show that quadratic width is required. Our results demonstrate the complex and intriguing landscape of transformer implementations of graph-based algorithms. We support our theoretical results with empirical evaluations.
Towards Invariance to Node Identifiers in Graph Neural Networks
Feb 19, 2025Message-Passing Graph Neural Networks (GNNs) are known to have limited expressive power, due to their message passing structure. One mechanism for circumventing this limitation is to add unique node identifiers (IDs), which break the symmetries that underlie the expressivity limitation. In this work, we highlight a key limitation of the ID framework, and propose an approach for addressing it. We begin by observing that the final output of the GNN should clearly not depend on the specific IDs used. We then show that in practice this does not hold, and thus the learned network does not possess this desired structural property. Such invariance to node IDs may be enforced in several ways, and we discuss their theoretical properties. We then propose a novel regularization method that effectively enforces ID invariance to the network. Extensive evaluations on both real-world and synthetic tasks demonstrate that our approach significantly improves ID invariance and, in turn, often boosts generalization performance.
On the Utilization of Unique Node Identifiers in Graph Neural Networks
Nov 04, 2024Graph neural networks have inherent representational limitations due to their message-passing structure. Recent work has suggested that these limitations can be overcome by using unique node identifiers (UIDs). Here we argue that despite the advantages of UIDs, one of their disadvantages is that they lose the desirable property of permutation-equivariance. We thus propose to focus on UID models that are permutation-equivariant, and present theoretical arguments for their advantages. Motivated by this, we propose a method to regularize UID models towards permutation equivariance, via a contrastive loss. We empirically demonstrate that our approach improves generalization and extrapolation abilities while providing faster training convergence. On the recent BREC expressiveness benchmark, our proposed method achieves state-of-the-art performance compared to other random-based approaches.
Improving Engagement and Efficacy of mHealth Micro-Interventions for Stress Coping: an In-The-Wild Study
Jul 16, 2024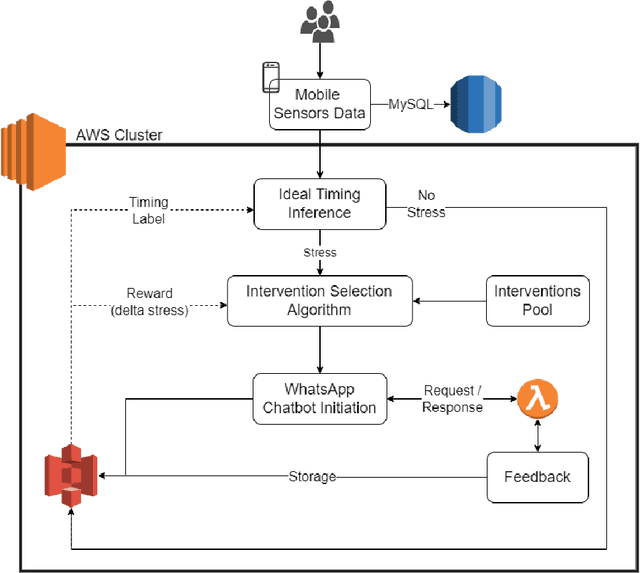

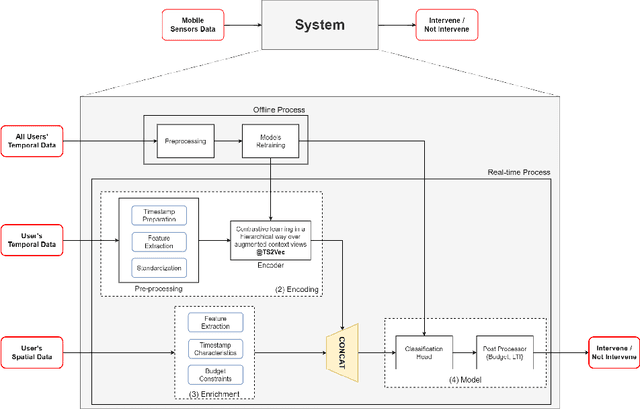
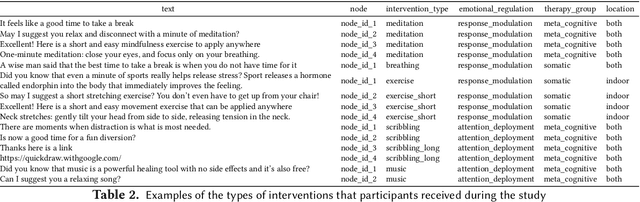
Sustaining long-term user engagement with mobile health (mHealth) interventions while preserving their high efficacy remains an ongoing challenge in real-world well-being applications. To address this issue, we introduce a new algorithm, the Personalized, Context-Aware Recommender (PCAR), for intervention selection and evaluate its performance in a field experiment. In a four-week, in-the-wild experiment involving 29 parents of young children, we delivered personalized stress-reducing micro-interventions through a mobile chatbot. We assessed their impact on stress reduction using momentary stress level ecological momentary assessments (EMAs) before and after each intervention. Our findings demonstrate the superiority of PCAR intervention selection in enhancing the engagement and efficacy of mHealth micro-interventions to stress coping compared to random intervention selection and a control group that did not receive any intervention. Furthermore, we show that even brief, one-minute interventions can significantly reduce perceived stress levels (p=0.001). We observe that individuals are most receptive to one-minute interventions during transitional periods between activities, such as transitioning from afternoon activities to bedtime routines. Our study contributes to the literature by introducing a personalized context-aware intervention selection algorithm that improves engagement and efficacy of mHealth interventions, identifying key timing for stress interventions, and offering insights into mechanisms to improve stress coping.
The Intelligible and Effective Graph Neural Additive Networks
Jun 03, 2024



Graph Neural Networks (GNNs) have emerged as the predominant approach for learning over graph-structured data. However, most GNNs operate as black-box models and require post-hoc explanations, which may not suffice in high-stakes scenarios where transparency is crucial. In this paper, we present a GNN that is interpretable by design. Our model, Graph Neural Additive Network (GNAN), is a novel extension of the interpretable class of Generalized Additive Models, and can be visualized and fully understood by humans. GNAN is designed to be fully interpretable, allowing both global and local explanations at the feature and graph levels through direct visualization of the model. These visualizations describe the exact way the model uses the relationships between the target variable, the features, and the graph. We demonstrate the intelligibility of GNANs in a series of examples on different tasks and datasets. In addition, we show that the accuracy of GNAN is on par with black-box GNNs, making it suitable for critical applications where transparency is essential, alongside high accuracy.
Tighter Bounds on the Information Bottleneck with Application to Deep Learning
Feb 12, 2024



Deep Neural Nets (DNNs) learn latent representations induced by their downstream task, objective function, and other parameters. The quality of the learned representations impacts the DNN's generalization ability and the coherence of the emerging latent space. The Information Bottleneck (IB) provides a hypothetically optimal framework for data modeling, yet it is often intractable. Recent efforts combined DNNs with the IB by applying VAE-inspired variational methods to approximate bounds on mutual information, resulting in improved robustness to adversarial attacks. This work introduces a new and tighter variational bound for the IB, improving performance of previous IB-inspired DNNs. These advancements strengthen the case for the IB and its variational approximations as a data modeling framework, and provide a simple method to significantly enhance the adversarial robustness of classifier DNNs.
Graph Neural Networks Use Graphs When They Shouldn't
Sep 08, 2023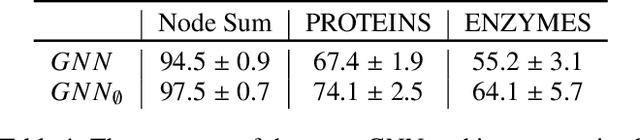
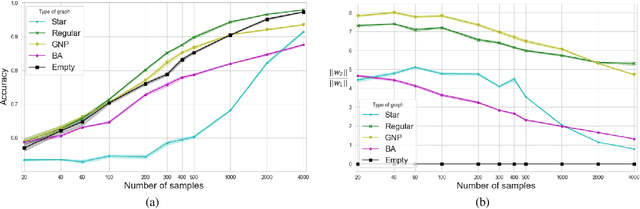
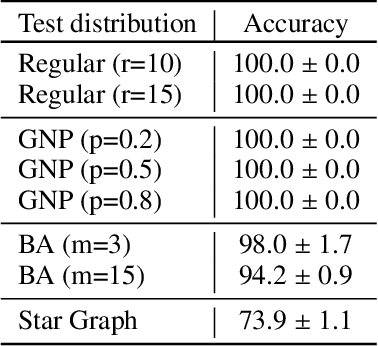
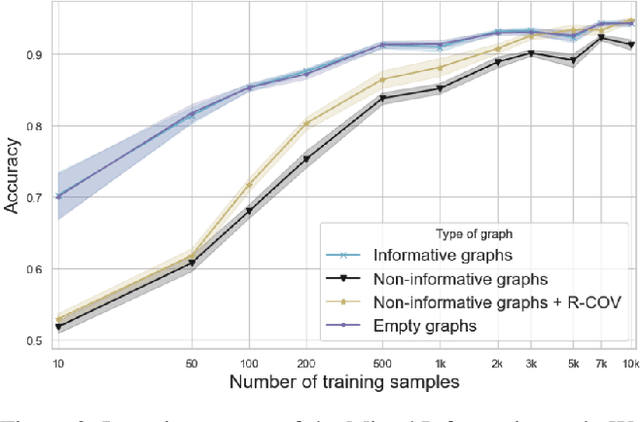
Predictions over graphs play a crucial role in various domains, including social networks, molecular biology, medicine, and more. Graph Neural Networks (GNNs) have emerged as the dominant approach for learning on graph data. Instances of graph labeling problems consist of the graph-structure (i.e., the adjacency matrix), along with node-specific feature vectors. In some cases, this graph-structure is non-informative for the predictive task. For instance, molecular properties such as molar mass depend solely on the constituent atoms (node features), and not on the molecular structure. While GNNs have the ability to ignore the graph-structure in such cases, it is not clear that they will. In this work, we show that GNNs actually tend to overfit the graph-structure in the sense that they use it even when a better solution can be obtained by ignoring it. We examine this phenomenon with respect to different graph distributions and find that regular graphs are more robust to this overfitting. We then provide a theoretical explanation for this phenomenon, via analyzing the implicit bias of gradient-descent-based learning of GNNs in this setting. Finally, based on our empirical and theoretical findings, we propose a graph-editing method to mitigate the tendency of GNNs to overfit graph-structures that should be ignored. We show that this method indeed improves the accuracy of GNNs across multiple benchmarks.
The Case Against Explainability
May 20, 2023
As artificial intelligence (AI) becomes more prevalent there is a growing demand from regulators to accompany decisions made by such systems with explanations. However, a persistent gap exists between the need to execute a meaningful right to explanation vs. the ability of Machine Learning systems to deliver on such a legal requirement. The regulatory appeal towards "a right to explanation" of AI systems can be attributed to the significant role of explanations, part of the notion called reason-giving, in law. Therefore, in this work we examine reason-giving's purposes in law to analyze whether reasons provided by end-user Explainability can adequately fulfill them. We find that reason-giving's legal purposes include: (a) making a better and more just decision, (b) facilitating due-process, (c) authenticating human agency, and (d) enhancing the decision makers' authority. Using this methodology, we demonstrate end-user Explainabilty's inadequacy to fulfil reason-giving's role in law, given reason-giving's functions rely on its impact over a human decision maker. Thus, end-user Explainability fails, or is unsuitable, to fulfil the first, second and third legal function. In contrast we find that end-user Explainability excels in the fourth function, a quality which raises serious risks considering recent end-user Explainability research trends, Large Language Models' capabilities, and the ability to manipulate end-users by both humans and machines. Hence, we suggest that in some cases the right to explanation of AI systems could bring more harm than good to end users. Accordingly, this study carries some important policy ramifications, as it calls upon regulators and Machine Learning practitioners to reconsider the widespread pursuit of end-user Explainability and a right to explanation of AI systems.