 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWe Should Separate Memorization from Copyright
Feb 09, 2026The widespread use of foundation models has introduced a new risk factor of copyright issue. This issue is leading to an active, lively and on-going debate amongst the data-science community as well as amongst legal scholars. Where claims and results across both sides are often interpreted in different ways and leading to different implications. Our position is that much of the technical literature relies on traditional reconstruction techniques that are not designed for copyright analysis. As a result, memorization and copying have been conflated across both technical and legal communities and in multiple contexts. We argue that memorization, as commonly studied in data science, should not be equated with copying and should not be used as a proxy for copyright infringement. We distinguish technical signals that meaningfully indicate infringement risk from those that instead reflect lawful generalization or high-frequency content. Based on this analysis, we advocate for an output-level, risk-based evaluation process that aligns technical assessments with established copyright standards and provides a more principled foundation for research, auditing, and policy.
CARLoS: Retrieval via Concise Assessment Representation of LoRAs at Scale
Dec 09, 2025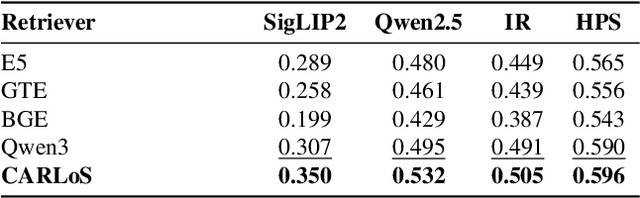
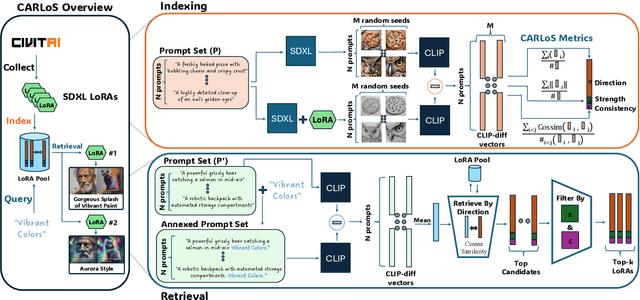
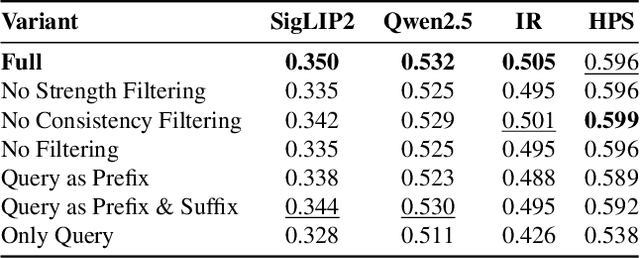

The rapid proliferation of generative components, such as LoRAs, has created a vast but unstructured ecosystem. Existing discovery methods depend on unreliable user descriptions or biased popularity metrics, hindering usability. We present CARLoS, a large-scale framework for characterizing LoRAs without requiring additional metadata. Analyzing over 650 LoRAs, we employ them in image generation over a variety of prompts and seeds, as a credible way to assess their behavior. Using CLIP embeddings and their difference to a base-model generation, we concisely define a three-part representation: Directions, defining semantic shift; Strength, quantifying the significance of the effect; and Consistency, quantifying how stable the effect is. Using these representations, we develop an efficient retrieval framework that semantically matches textual queries to relevant LoRAs while filtering overly strong or unstable ones, outperforming textual baselines in automated and human evaluations. While retrieval is our primary focus, the same representation also supports analyses linking Strength and Consistency to legal notions of substantiality and volition, key considerations in copyright, positioning CARLoS as a practical system with broader relevance for LoRA analysis.
Not Every Image is Worth a Thousand Words: Quantifying Originality in Stable Diffusion
Aug 15, 2024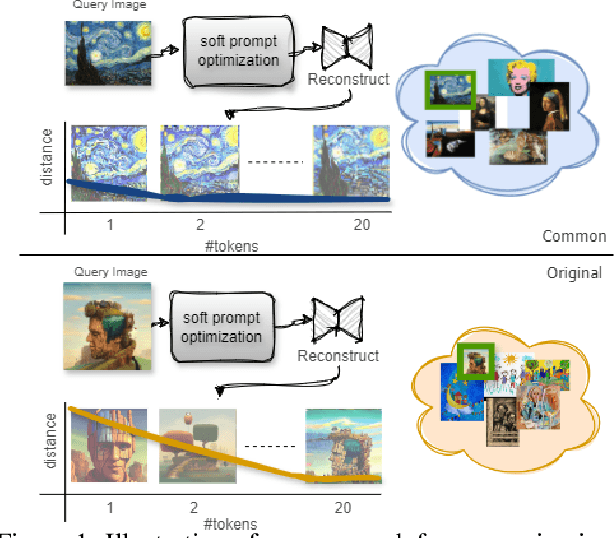



This work addresses the challenge of quantifying originality in text-to-image (T2I) generative diffusion models, with a focus on copyright originality. We begin by evaluating T2I models' ability to innovate and generalize through controlled experiments, revealing that stable diffusion models can effectively recreate unseen elements with sufficiently diverse training data. Then, our key insight is that concepts and combinations of image elements the model is familiar with, and saw more during training, are more concisly represented in the model's latent space. We hence propose a method that leverages textual inversion to measure the originality of an image based on the number of tokens required for its reconstruction by the model. Our approach is inspired by legal definitions of originality and aims to assess whether a model can produce original content without relying on specific prompts or having the training data of the model. We demonstrate our method using both a pre-trained stable diffusion model and a synthetic dataset, showing a correlation between the number of tokens and image originality. This work contributes to the understanding of originality in generative models and has implications for copyright infringement cases.
Not All Similarities Are Created Equal: Leveraging Data-Driven Biases to Inform GenAI Copyright Disputes
Mar 26, 2024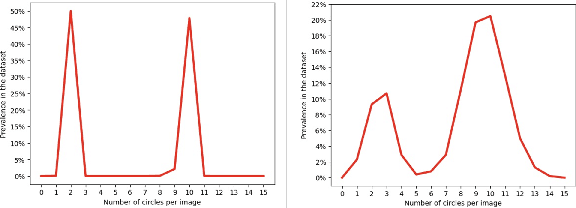
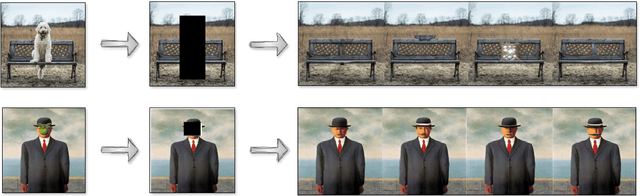
The advent of Generative Artificial Intelligence (GenAI) models, including GitHub Copilot, OpenAI GPT, and Stable Diffusion, has revolutionized content creation, enabling non-professionals to produce high-quality content across various domains. This transformative technology has led to a surge of synthetic content and sparked legal disputes over copyright infringement. To address these challenges, this paper introduces a novel approach that leverages the learning capacity of GenAI models for copyright legal analysis, demonstrated with GPT2 and Stable Diffusion models. Copyright law distinguishes between original expressions and generic ones (Sc\`enes \`a faire), protecting the former and permitting reproduction of the latter. However, this distinction has historically been challenging to make consistently, leading to over-protection of copyrighted works. GenAI offers an unprecedented opportunity to enhance this legal analysis by revealing shared patterns in preexisting works. We propose a data-driven approach to identify the genericity of works created by GenAI, employing "data-driven bias" to assess the genericity of expressive compositions. This approach aids in copyright scope determination by utilizing the capabilities of GenAI to identify and prioritize expressive elements and rank them according to their frequency in the model's dataset. The potential implications of measuring expressive genericity for copyright law are profound. Such scoring could assist courts in determining copyright scope during litigation, inform the registration practices of Copyright Offices, allowing registration of only highly original synthetic works, and help copyright owners signal the value of their works and facilitate fairer licensing deals. More generally, this approach offers valuable insights to policymakers grappling with adapting copyright law to the challenges posed by the era of GenAI.
Can Copyright be Reduced to Privacy?
May 24, 2023
There is an increasing concern that generative AI models may produce outputs that are remarkably similar to the copyrighted input content on which they are trained. This worry has escalated as the quality and complexity of generative models have immensely improved, and the availability of large datasets containing copyrighted material has increased. Researchers are actively exploring strategies to mitigate the risk of producing infringing samples, and a recent line of work suggests to employ techniques such as differential privacy and other forms of algorithmic stability to safeguard copyrighted content. In this work, we examine the question whether algorithmic stability techniques such as differential privacy are suitable to ensure the responsible use of generative models without inadvertently violating copyright laws. We argue that there are fundamental differences between privacy and copyright that should not be overlooked. In particular we highlight that although algorithmic stability may be perceived as a practical tool to detect copying, it does not necessarily equate to copyright protection. Therefore, if it is adopted as standard for copyright infringement, it may undermine copyright law intended purposes.
The Case Against Explainability
May 20, 2023
As artificial intelligence (AI) becomes more prevalent there is a growing demand from regulators to accompany decisions made by such systems with explanations. However, a persistent gap exists between the need to execute a meaningful right to explanation vs. the ability of Machine Learning systems to deliver on such a legal requirement. The regulatory appeal towards "a right to explanation" of AI systems can be attributed to the significant role of explanations, part of the notion called reason-giving, in law. Therefore, in this work we examine reason-giving's purposes in law to analyze whether reasons provided by end-user Explainability can adequately fulfill them. We find that reason-giving's legal purposes include: (a) making a better and more just decision, (b) facilitating due-process, (c) authenticating human agency, and (d) enhancing the decision makers' authority. Using this methodology, we demonstrate end-user Explainabilty's inadequacy to fulfil reason-giving's role in law, given reason-giving's functions rely on its impact over a human decision maker. Thus, end-user Explainability fails, or is unsuitable, to fulfil the first, second and third legal function. In contrast we find that end-user Explainability excels in the fourth function, a quality which raises serious risks considering recent end-user Explainability research trends, Large Language Models' capabilities, and the ability to manipulate end-users by both humans and machines. Hence, we suggest that in some cases the right to explanation of AI systems could bring more harm than good to end users. Accordingly, this study carries some important policy ramifications, as it calls upon regulators and Machine Learning practitioners to reconsider the widespread pursuit of end-user Explainability and a right to explanation of AI systems.