 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Equivalence Queries, Revisited
Apr 06, 2026Modern machine learning systems, such as generative models and recommendation systems, often evolve through a cycle of deployment, user interaction, and periodic model updates. This differs from standard supervised learning frameworks, which focus on loss or regret minimization over a fixed sequence of prediction tasks. Motivated by this setting, we revisit the classical model of learning from equivalence queries, introduced by Angluin (1988). In this model, a learner repeatedly proposes hypotheses and, when a deployed hypothesis is inadequate, receives a counterexample. Under fully adversarial counterexample generation, however, the model can be overly pessimistic. In addition, most prior work assumes a \emph{full-information} setting, where the learner also observes the correct label of the counterexample, an assumption that is not always natural. We address these issues by restricting the environment to a broad class of less adversarial counterexample generators, which we call \emph{symmetric}. Informally, such generators choose counterexamples based only on the symmetric difference between the hypothesis and the target. This class captures natural mechanisms such as random counterexamples (Angluin and Dohrn, 2017; Bhatia, 2021; Chase, Freitag, and Reyzin, 2024), as well as generators that return the simplest counterexample according to a prescribed complexity measure. Within this framework, we study learning from equivalence queries under both full-information and bandit feedback. We obtain tight bounds on the number of learning rounds in both settings and highlight directions for future work. Our analysis combines a game-theoretic view of symmetric adversaries with adaptive weighting methods and minimax arguments.
We Should Separate Memorization from Copyright
Feb 09, 2026The widespread use of foundation models has introduced a new risk factor of copyright issue. This issue is leading to an active, lively and on-going debate amongst the data-science community as well as amongst legal scholars. Where claims and results across both sides are often interpreted in different ways and leading to different implications. Our position is that much of the technical literature relies on traditional reconstruction techniques that are not designed for copyright analysis. As a result, memorization and copying have been conflated across both technical and legal communities and in multiple contexts. We argue that memorization, as commonly studied in data science, should not be equated with copying and should not be used as a proxy for copyright infringement. We distinguish technical signals that meaningfully indicate infringement risk from those that instead reflect lawful generalization or high-frequency content. Based on this analysis, we advocate for an output-level, risk-based evaluation process that aligns technical assessments with established copyright standards and provides a more principled foundation for research, auditing, and policy.
All ERMs Can Fail in Stochastic Convex Optimization Lower Bounds in Linear Dimension
Feb 09, 2026We study the sample complexity of the best-case Empirical Risk Minimizer in the setting of stochastic convex optimization. We show that there exists an instance in which the sample size is linear in the dimension, learning is possible, but the Empirical Risk Minimizer is likely to be unique and to overfit. This resolves an open question by Feldman. We also extend this to approximate ERMs. Building on our construction we also show that (constrained) Gradient Descent potentially overfits when horizon and learning rate grow w.r.t sample size. Specifically we provide a novel generalization lower bound of $Ω\left(\sqrt{ηT/m^{1.5}}\right)$ for Gradient Descent, where $η$ is the learning rate, $T$ is the horizon and $m$ is the sample size. This narrows down, exponentially, the gap between the best known upper bound of $O(ηT/m)$ and existing lower bounds from previous constructions.
CARLoS: Retrieval via Concise Assessment Representation of LoRAs at Scale
Dec 09, 2025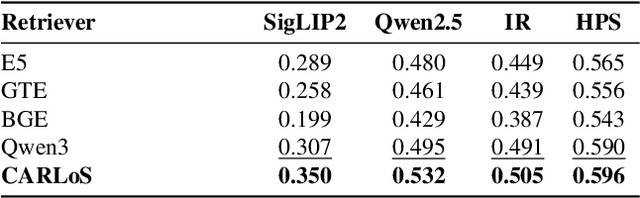
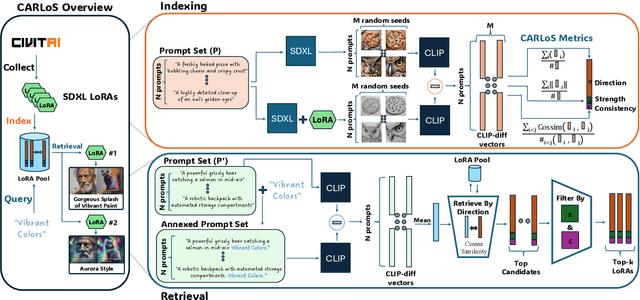
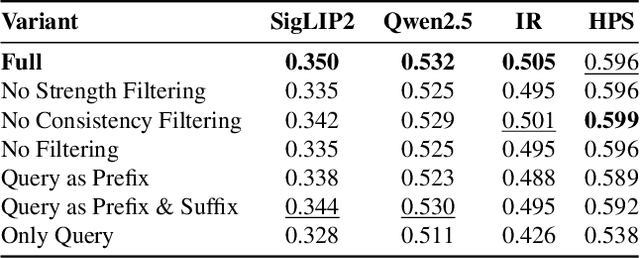

The rapid proliferation of generative components, such as LoRAs, has created a vast but unstructured ecosystem. Existing discovery methods depend on unreliable user descriptions or biased popularity metrics, hindering usability. We present CARLoS, a large-scale framework for characterizing LoRAs without requiring additional metadata. Analyzing over 650 LoRAs, we employ them in image generation over a variety of prompts and seeds, as a credible way to assess their behavior. Using CLIP embeddings and their difference to a base-model generation, we concisely define a three-part representation: Directions, defining semantic shift; Strength, quantifying the significance of the effect; and Consistency, quantifying how stable the effect is. Using these representations, we develop an efficient retrieval framework that semantically matches textual queries to relevant LoRAs while filtering overly strong or unstable ones, outperforming textual baselines in automated and human evaluations. While retrieval is our primary focus, the same representation also supports analyses linking Strength and Consistency to legal notions of substantiality and volition, key considerations in copyright, positioning CARLoS as a practical system with broader relevance for LoRA analysis.
Low Resource Reconstruction Attacks Through Benign Prompts
Jul 10, 2025The recent advances in generative models such as diffusion models have raised several risks and concerns related to privacy, copyright infringements and data stewardship. To better understand and control the risks, various researchers have created techniques, experiments and attacks that reconstruct images, or part of images, from the training set. While these techniques already establish that data from the training set can be reconstructed, they often rely on high-resources, excess to the training set as well as well-engineered and designed prompts. In this work, we devise a new attack that requires low resources, assumes little to no access to the actual training set, and identifies, seemingly, benign prompts that lead to potentially-risky image reconstruction. This highlights the risk that images might even be reconstructed by an uninformed user and unintentionally. For example, we identified that, with regard to one existing model, the prompt ``blue Unisex T-Shirt'' can generate the face of a real-life human model. Our method builds on an intuition from previous works which leverages domain knowledge and identifies a fundamental vulnerability that stems from the use of scraped data from e-commerce platforms, where templated layouts and images are tied to pattern-like prompts.
Rapid Overfitting of Multi-Pass Stochastic Gradient Descent in Stochastic Convex Optimization
May 13, 2025We study the out-of-sample performance of multi-pass stochastic gradient descent (SGD) in the fundamental stochastic convex optimization (SCO) model. While one-pass SGD is known to achieve an optimal $\Theta(1/\sqrt{n})$ excess population loss given a sample of size $n$, much less is understood about the multi-pass version of the algorithm which is widely used in practice. Somewhat surprisingly, we show that in the general non-smooth case of SCO, just a few epochs of SGD can already hurt its out-of-sample performance significantly and lead to overfitting. In particular, using a step size $\eta = \Theta(1/\sqrt{n})$, which gives the optimal rate after one pass, can lead to population loss as large as $\Omega(1)$ after just one additional pass. More generally, we show that the population loss from the second pass onward is of the order $\Theta(1/(\eta T) + \eta \sqrt{T})$, where $T$ is the total number of steps. These results reveal a certain phase-transition in the out-of-sample behavior of SGD after the first epoch, as well as a sharp separation between the rates of overfitting in the smooth and non-smooth cases of SCO. Additionally, we extend our results to with-replacement SGD, proving that the same asymptotic bounds hold after $O(n \log n)$ steps. Finally, we also prove a lower bound of $\Omega(\eta \sqrt{n})$ on the generalization gap of one-pass SGD in dimension $d = \smash{\widetilde O}(n)$, improving on recent results of Koren et al.(2022) and Schliserman et al.(2024).
On the Dichotomy Between Privacy and Traceability in $\ell_p$ Stochastic Convex Optimization
Feb 24, 2025In this paper, we investigate the necessity of memorization in stochastic convex optimization (SCO) under $\ell_p$ geometries. Informally, we say a learning algorithm memorizes $m$ samples (or is $m$-traceable) if, by analyzing its output, it is possible to identify at least $m$ of its training samples. Our main results uncover a fundamental tradeoff between traceability and excess risk in SCO. For every $p\in [1,\infty)$, we establish the existence of a risk threshold below which any sample-efficient learner must memorize a \em{constant fraction} of its sample. For $p\in [1,2]$, this threshold coincides with best risk of differentially private (DP) algorithms, i.e., above this threshold, there are algorithms that do not memorize even a single sample. This establishes a sharp dichotomy between privacy and traceability for $p \in [1,2]$. For $p \in (2,\infty)$, this threshold instead gives novel lower bounds for DP learning, partially closing an open problem in this setup. En route of proving these results, we introduce a complexity notion we term \em{trace value} of a problem, which unifies privacy lower bounds and traceability results, and prove a sparse variant of the fingerprinting lemma.
Not Every Image is Worth a Thousand Words: Quantifying Originality in Stable Diffusion
Aug 15, 2024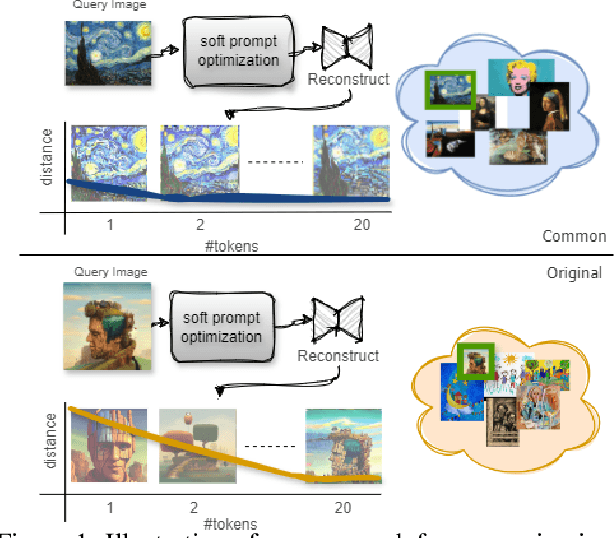



This work addresses the challenge of quantifying originality in text-to-image (T2I) generative diffusion models, with a focus on copyright originality. We begin by evaluating T2I models' ability to innovate and generalize through controlled experiments, revealing that stable diffusion models can effectively recreate unseen elements with sufficiently diverse training data. Then, our key insight is that concepts and combinations of image elements the model is familiar with, and saw more during training, are more concisly represented in the model's latent space. We hence propose a method that leverages textual inversion to measure the originality of an image based on the number of tokens required for its reconstruction by the model. Our approach is inspired by legal definitions of originality and aims to assess whether a model can produce original content without relying on specific prompts or having the training data of the model. We demonstrate our method using both a pre-trained stable diffusion model and a synthetic dataset, showing a correlation between the number of tokens and image originality. This work contributes to the understanding of originality in generative models and has implications for copyright infringement cases.
Credit Attribution and Stable Compression
Jun 22, 2024
Credit attribution is crucial across various fields. In academic research, proper citation acknowledges prior work and establishes original contributions. Similarly, in generative models, such as those trained on existing artworks or music, it is important to ensure that any generated content influenced by these works appropriately credits the original creators. We study credit attribution by machine learning algorithms. We propose new definitions--relaxations of Differential Privacy--that weaken the stability guarantees for a designated subset of $k$ datapoints. These $k$ datapoints can be used non-stably with permission from their owners, potentially in exchange for compensation. Meanwhile, the remaining datapoints are guaranteed to have no significant influence on the algorithm's output. Our framework extends well-studied notions of stability, including Differential Privacy ($k = 0$), differentially private learning with public data (where the $k$ public datapoints are fixed in advance), and stable sample compression (where the $k$ datapoints are selected adaptively by the algorithm). We examine the expressive power of these stability notions within the PAC learning framework, provide a comprehensive characterization of learnability for algorithms adhering to these principles, and propose directions and questions for future research.
The Sample Complexity of Gradient Descent in Stochastic Convex Optimization
Apr 11, 2024We analyze the sample complexity of full-batch Gradient Descent (GD) in the setup of non-smooth Stochastic Convex Optimization. We show that the generalization error of GD, with common choice of hyper-parameters, can be $\tilde \Theta(d/m + 1/\sqrt{m})$, where $d$ is the dimension and $m$ is the sample size. This matches the sample complexity of \emph{worst-case} empirical risk minimizers. That means that, in contrast with other algorithms, GD has no advantage over naive ERMs. Our bound follows from a new generalization bound that depends on both the dimension as well as the learning rate and number of iterations. Our bound also shows that, for general hyper-parameters, when the dimension is strictly larger than number of samples, $T=\Omega(1/\epsilon^4)$ iterations are necessary to avoid overfitting. This resolves an open problem by Schlisserman et al.23 and Amir er Al.21, and improves over previous lower bounds that demonstrated that the sample size must be at least square root of the dimension.