 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Non-Convex to Strongly Convex: Curvature-Adaptive FTPL for Online Optimization
Jun 01, 2026Curvature adaptivity is a classical theme in online optimization: for convex Lipschitz losses, adaptive methods interpolate between the optimal $O(\sqrt{T})$ regret for general convex losses and $O(\log T)$ regret under strong convexity. Recent work has shown that Follow-the-Perturbed-Leader (FTPL) achieves optimal $O(\sqrt{T})$ regret even for online non-convex Lipschitz losses, assuming access to an approximate offline-optimization oracle, but these guarantees do not exploit curvature. We show that FTPL can be made curvature-adaptive in the non-convex setting, without knowing in advance how curvature will accumulate over time. Our algorithm replaces the fixed perturbation scale of standard FTPL with a time-varying scale chosen using only past information. We give a simple follow-the-leader tuning rule for this scale and show that it competes, up to constants, with the best choice in hindsight. The resulting method achieves $O(\sqrt{T})$ regret for arbitrary non-convex Lipschitz losses and improves as cumulative curvature grows; with sufficiently accurate oracle calls, it achieves $O(\log T)$ regret when cumulative curvature grows linearly, which includes the classical strongly convex regime. We complement these upper bounds with matching lower bounds for prescribed cumulative-curvature sequences, already for one-dimensional convex losses, showing that the tradeoff between worst-case non-convex regret and curvature-driven fast rates is intrinsic.
The Optimal Sample Complexity of Multiclass and List Learning
Apr 27, 2026While the optimal sample complexity of binary classification in terms of the VC dimension is well-established, determining the optimal sample complexity of multiclass classification has remained open. The appropriate complexity parameter for multiclass classification is the DS dimension, and despite significant efforts, a gap of $\sqrt{\text{DS}}$ has persisted between the upper and lower bounds on sample complexity. Recent work by Hanneke et al. (2026) shows a novel algebraic characterization of multiclass hypothesis classes in terms of their DS dimension. Building up on this, we show that the maximum hypergraph density of any multiclass hypothesis class is upper-bounded by its DS dimension. This proves a longstanding conjecture of Daniely and Shalev-Shwartz (2014). As a consequence, we determine the optimal dependence of the sample complexity on the DS dimension for multiclass as well as list learning.
The Sample Complexity of Replicable Realizable PAC Learning
Feb 23, 2026In this paper, we consider the problem of replicable realizable PAC learning. We construct a particularly hard learning problem and show a sample complexity lower bound with a close to $(\log|H|)^{3/2}$ dependence on the size of the hypothesis class $H$. Our proof uses several novel techniques and works by defining a particular Cayley graph associated with $H$ and analyzing a suitable random walk on this graph by examining the spectral properties of its adjacency matrix. Furthermore, we show an almost matching upper bound for the lower bound instance, meaning if a stronger lower bound exists, one would have to consider a different instance of the problem.
Agnostic Language Identification and Generation
Jan 30, 2026Recent works on language identification and generation have established tight statistical rates at which these tasks can be achieved. These works typically operate under a strong realizability assumption: that the input data is drawn from an unknown distribution necessarily supported on some language in a given collection. In this work, we relax this assumption of realizability entirely, and impose no restrictions on the distribution of the input data. We propose objectives to study both language identification and generation in this more general "agnostic" setup. Across both problems, we obtain novel interesting characterizations and nearly tight rates.
Learning with Monotone Adversarial Corruptions
Jan 05, 2026We study the extent to which standard machine learning algorithms rely on exchangeability and independence of data by introducing a monotone adversarial corruption model. In this model, an adversary, upon looking at a "clean" i.i.d. dataset, inserts additional "corrupted" points of their choice into the dataset. These added points are constrained to be monotone corruptions, in that they get labeled according to the ground-truth target function. Perhaps surprisingly, we demonstrate that in this setting, all known optimal learning algorithms for binary classification can be made to achieve suboptimal expected error on a new independent test point drawn from the same distribution as the clean dataset. On the other hand, we show that uniform convergence-based algorithms do not degrade in their guarantees. Our results showcase how optimal learning algorithms break down in the face of seemingly helpful monotone corruptions, exposing their overreliance on exchangeability.
A Characterization of List Language Identification in the Limit
Nov 06, 2025We study the problem of language identification in the limit, where given a sequence of examples from a target language, the goal of the learner is to output a sequence of guesses for the target language such that all the guesses beyond some finite time are correct. Classical results of Gold showed that language identification in the limit is impossible for essentially any interesting collection of languages. Later, Angluin gave a precise characterization of language collections for which this task is possible. Motivated by recent positive results for the related problem of language generation, we revisit the classic language identification problem in the setting where the learner is given the additional power of producing a list of $k$ guesses at each time step. The goal is to ensure that beyond some finite time, one of the guesses is correct at each time step. We give an exact characterization of collections of languages that can be $k$-list identified in the limit, based on a recursive version of Angluin's characterization (for language identification with a list of size $1$). This further leads to a conceptually appealing characterization: A language collection can be $k$-list identified in the limit if and only if the collection can be decomposed into $k$ collections of languages, each of which can be identified in the limit (with a list of size $1$). We also use our characterization to establish rates for list identification in the statistical setting where the input is drawn as an i.i.d. stream from a distribution supported on some language in the collection. Our results show that if a collection is $k$-list identifiable in the limit, then the collection can be $k$-list identified at an exponential rate, and this is best possible. On the other hand, if a collection is not $k$-list identifiable in the limit, then it cannot be $k$-list identified at any rate that goes to zero.
Lower Bounds for Greedy Teaching Set Constructions
May 06, 2025A fundamental open problem in learning theory is to characterize the best-case teaching dimension $\operatorname{TS}_{\min}$ of a concept class $\mathcal{C}$ with finite VC dimension $d$. Resolving this problem will, in particular, settle the conjectured upper bound on Recursive Teaching Dimension posed by [Simon and Zilles; COLT 2015]. Prior work used a natural greedy algorithm to construct teaching sets recursively, thereby proving upper bounds on $\operatorname{TS}_{\min}$, with the best known bound being $O(d^2)$ [Hu, Wu, Li, and Wang; COLT 2017]. In each iteration, this greedy algorithm chooses to add to the teaching set the $k$ labeled points that restrict the concept class the most. In this work, we prove lower bounds on the performance of this greedy approach for small $k$. Specifically, we show that for $k = 1$, the algorithm does not improve upon the halving-based bound of $O(\log(|\mathcal{C}|))$. Furthermore, for $k = 2$, we complement the upper bound of $O\left(\log(\log(|\mathcal{C}|))\right)$ from [Moran, Shpilka, Wigderson, and Yuhudayoff; FOCS 2015] with a matching lower bound. Most consequentially, our lower bound extends up to $k \le \lceil c d \rceil$ for small constant $c>0$: suggesting that studying higher-order interactions may be necessary to resolve the conjecture that $\operatorname{TS}_{\min} = O(d)$.
Proofs as Explanations: Short Certificates for Reliable Predictions
Apr 11, 2025We consider a model for explainable AI in which an explanation for a prediction $h(x)=y$ consists of a subset $S'$ of the training data (if it exists) such that all classifiers $h' \in H$ that make at most $b$ mistakes on $S'$ predict $h'(x)=y$. Such a set $S'$ serves as a proof that $x$ indeed has label $y$ under the assumption that (1) the target function $h^\star$ belongs to $H$, and (2) the set $S$ contains at most $b$ corrupted points. For example, if $b=0$ and $H$ is the family of linear classifiers in $\mathbb{R}^d$, and if $x$ lies inside the convex hull of the positive data points in $S$ (and hence every consistent linear classifier labels $x$ as positive), then Carath\'eodory's theorem states that $x$ lies inside the convex hull of $d+1$ of those points. So, a set $S'$ of size $d+1$ could be released as an explanation for a positive prediction, and would serve as a short proof of correctness of the prediction under the assumption of realizability. In this work, we consider this problem more generally, for general hypothesis classes $H$ and general values $b\geq 0$. We define the notion of the robust hollow star number of $H$ (which generalizes the standard hollow star number), and show that it precisely characterizes the worst-case size of the smallest certificate achievable, and analyze its size for natural classes. We also consider worst-case distributional bounds on certificate size, as well as distribution-dependent bounds that we show tightly control the sample size needed to get a certificate for any given test example. In particular, we define a notion of the certificate coefficient $\varepsilon_x$ of an example $x$ with respect to a data distribution $D$ and target function $h^\star$, and prove matching upper and lower bounds on sample size as a function of $\varepsilon_x$, $b$, and the VC dimension $d$ of $H$.
Relating Misfit to Gain in Weak-to-Strong Generalization Beyond the Squared Loss
Jan 31, 2025
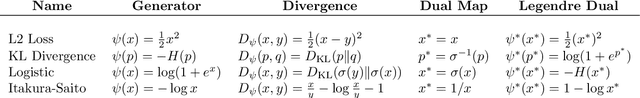
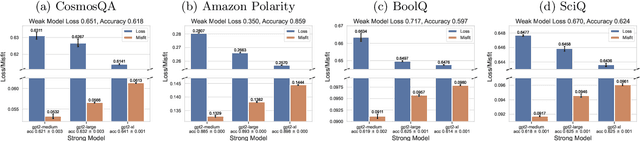
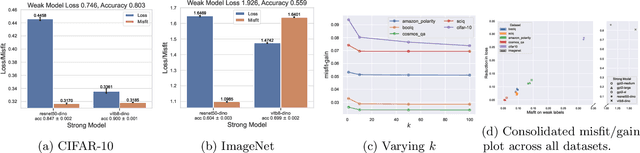
The paradigm of weak-to-strong generalization constitutes the training of a strong AI model on data labeled by a weak AI model, with the goal that the strong model nevertheless outperforms its weak supervisor on the target task of interest. For the setting of real-valued regression with the squared loss, recent work quantitatively characterizes the gain in performance of the strong model over the weak model in terms of the misfit between the strong and weak model. We generalize such a characterization to learning tasks whose loss functions correspond to arbitrary Bregman divergences when the strong class is convex. This extends the misfit-based characterization of performance gain in weak-to-strong generalization to classification tasks, as the cross-entropy loss can be expressed in terms of a Bregman divergence. In most practical scenarios, however, the strong model class may not be convex. We therefore weaken this assumption and study weak-to-strong generalization for convex combinations of $k$ strong models in the strong class, in the concrete setting of classification. This allows us to obtain a similar misfit-based characterization of performance gain, upto an additional error term that vanishes as $k$ gets large. Our theoretical findings are supported by thorough experiments on synthetic as well as real-world datasets.
Exploring Facets of Language Generation in the Limit
Nov 22, 2024The recent work of Kleinberg and Mullainathan [KM24] provides a concrete model for language generation in the limit: given a sequence of examples from an unknown target language, the goal is to generate new examples from the target language such that no incorrect examples are generated beyond some point. In sharp contrast to strong negative results for the closely related problem of language identification, they establish positive results for language generation in the limit for all countable collections of languages. Follow-up work by Raman and Tewari [RT24] studies bounds on the number of distinct inputs required by an algorithm before correct language generation is achieved -- namely, whether this is a constant for all languages in the collection (uniform generation) or a language-dependent constant (non-uniform generation). We show that every countable language collection has a generator which has the stronger property of non-uniform generation in the limit. However, while the generation algorithm of [KM24] can be implemented using membership queries, we show that any algorithm cannot non-uniformly generate even for collections of just two languages, using only membership queries. We also formalize the tension between validity and breadth in the generation algorithm of [KM24] by introducing a definition of exhaustive generation, and show a strong negative result for exhaustive generation. Our result shows that a tradeoff between validity and breadth is inherent for generation in the limit. Finally, inspired by algorithms that can choose to obtain feedback, we consider a model of uniform generation with feedback, completely characterizing language collections for which such uniform generation with feedback is possible in terms of a complexity measure of the collection.