 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Strengths and Limitations of Single-Vector Embeddings
Mar 31, 2026Recent work (Weller et al., 2025) introduced a naturalistic dataset called LIMIT and showed empirically that a wide range of popular single-vector embedding models suffer substantial drops in retrieval quality, raising concerns about the reliability of single-vector embeddings for retrieval. Although (Weller et al., 2025) proposed limited dimensionality as the main factor contributing to this, we show that dimensionality alone cannot explain the observed failures. We observe from results in (Alon et al., 2016) that $2k+1$-dimensional vector embeddings suffice for top-$k$ retrieval. This result points to other drivers of poor performance. Controlling for tokenization artifacts and linguistic similarity between attributes yields only modest gains. In contrast, we find that domain shift and misalignment between embedding similarities and the task's underlying notion of relevance are major contributors; finetuning mitigates these effects and can improve recall substantially. Even with finetuning, however, single-vector models remain markedly weaker than multi-vector representations, pointing to fundamental limitations. Moreover, finetuning single-vector models on LIMIT-like datasets leads to catastrophic forgetting (performance on MSMARCO drops by more than 40%), whereas forgetting for multi-vector models is minimal. To better understand the gap between performance of single-vector and multi-vector models, we study the drowning in documents paradox (Reimers \& Gurevych, 2021; Jacob et al., 2025): as the corpus grows, relevant documents are increasingly "drowned out" because embedding similarities behave, in part, like noisy statistical proxies for relevance. Through experiments and mathematical calculations on toy mathematical models, we illustrate why single-vector models are more susceptible to drowning effects compared to multi-vector models.
Chow-Liu Ordering for Long-Context Reasoning in Chain-of-Agents
Mar 10, 2026Sequential multi-agent reasoning frameworks such as Chain-of-Agents (CoA) handle long-context queries by decomposing inputs into chunks and processing them sequentially using LLM-based worker agents that read from and update a bounded shared memory. From a probabilistic perspective, CoA aims to approximate the conditional distribution corresponding to a model capable of jointly reasoning over the entire long context. CoA achieves this through a latent-state factorization in which only bounded summaries of previously processed evidence are passed between agents. The resulting bounded-memory approximation introduces a lossy information bottleneck, making the final evidence state inherently dependent on the order in which chunks are processed. In this work, we study the problem of chunk ordering for long-context reasoning. We use the well-known Chow-Liu trees to learn a dependency structure that prioritizes strongly related chunks. Empirically, we show that a breadth-first traversal of the resulting tree yields chunk orderings that reduce information loss across agents and consistently outperform both default document-chunk ordering and semantic score-based ordering in answer relevance and exact-match accuracy across three long-context benchmarks.
Welfarist Formulations for Diverse Similarity Search
Feb 09, 2026Nearest Neighbor Search (NNS) is a fundamental problem in data structures with wide-ranging applications, such as web search, recommendation systems, and, more recently, retrieval-augmented generations (RAG). In such recent applications, in addition to the relevance (similarity) of the returned neighbors, diversity among the neighbors is a central requirement. In this paper, we develop principled welfare-based formulations in NNS for realizing diversity across attributes. Our formulations are based on welfare functions -- from mathematical economics -- that satisfy central diversity (fairness) and relevance (economic efficiency) axioms. With a particular focus on Nash social welfare, we note that our welfare-based formulations provide objective functions that adaptively balance relevance and diversity in a query-dependent manner. Notably, such a balance was not present in the prior constraint-based approach, which forced a fixed level of diversity and optimized for relevance. In addition, our formulation provides a parametric way to control the trade-off between relevance and diversity, providing practitioners with flexibility to tailor search results to task-specific requirements. We develop efficient nearest neighbor algorithms with provable guarantees for the welfare-based objectives. Notably, our algorithm can be applied on top of any standard ANN method (i.e., use standard ANN method as a subroutine) to efficiently find neighbors that approximately maximize our welfare-based objectives. Experimental results demonstrate that our approach is practical and substantially improves diversity while maintaining high relevance of the retrieved neighbors.
COSMIR: Chain Orchestrated Structured Memory for Iterative Reasoning over Long Context
Oct 06, 2025


Reasoning over very long inputs remains difficult for large language models (LLMs). Common workarounds either shrink the input via retrieval (risking missed evidence), enlarge the context window (straining selectivity), or stage multiple agents to read in pieces. In staged pipelines (e.g., Chain of Agents, CoA), free-form summaries passed between agents can discard crucial details and amplify early mistakes. We introduce COSMIR (Chain Orchestrated Structured Memory for Iterative Reasoning), a chain-style framework that replaces ad hoc messages with a structured memory. A Planner agent first turns a user query into concrete, checkable sub-questions. worker agents process chunks via a fixed micro-cycle: Extract, Infer, Refine, writing all updates to the shared memory. A Manager agent then Synthesizes the final answer directly from the memory. This preserves step-wise read-then-reason benefits while changing both the communication medium (structured memory) and the worker procedure (fixed micro-cycle), yielding higher faithfulness, better long-range aggregation, and auditability. On long-context QA from the HELMET suite, COSMIR reduces propagation-stage information loss and improves accuracy over a CoA baseline.
Learning Mixtures of Unknown Causal Interventions
Oct 31, 2024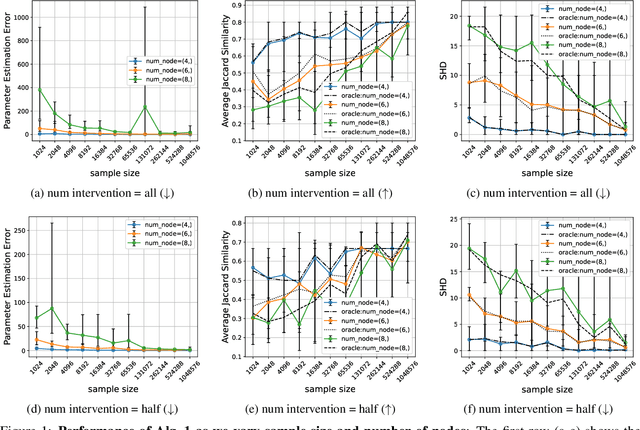
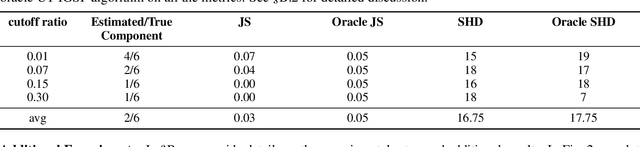
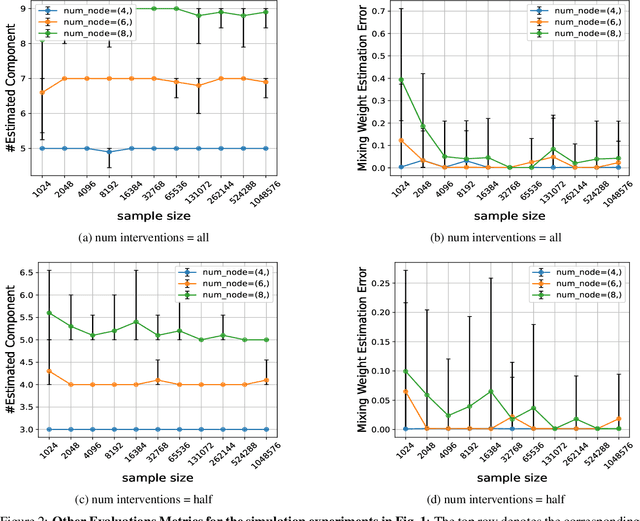
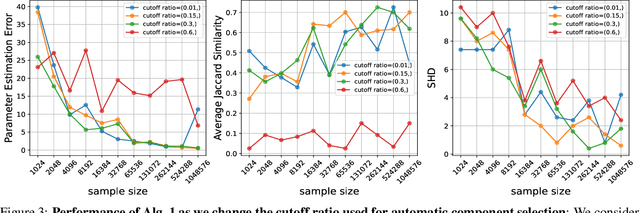
The ability to conduct interventions plays a pivotal role in learning causal relationships among variables, thus facilitating applications across diverse scientific disciplines such as genomics, economics, and machine learning. However, in many instances within these applications, the process of generating interventional data is subject to noise: rather than data being sampled directly from the intended interventional distribution, interventions often yield data sampled from a blend of both intended and unintended interventional distributions. We consider the fundamental challenge of disentangling mixed interventional and observational data within linear Structural Equation Models (SEMs) with Gaussian additive noise without the knowledge of the true causal graph. We demonstrate that conducting interventions, whether do or soft, yields distributions with sufficient diversity and properties conducive to efficiently recovering each component within the mixture. Furthermore, we establish that the sample complexity required to disentangle mixed data inversely correlates with the extent of change induced by an intervention in the equations governing the affected variable values. As a result, the causal graph can be identified up to its interventional Markov Equivalence Class, similar to scenarios where no noise influences the generation of interventional data. We further support our theoretical findings by conducting simulations wherein we perform causal discovery from such mixed data.
Causal Discovery with Fewer Conditional Independence Tests
Jun 03, 2024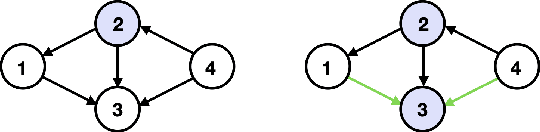


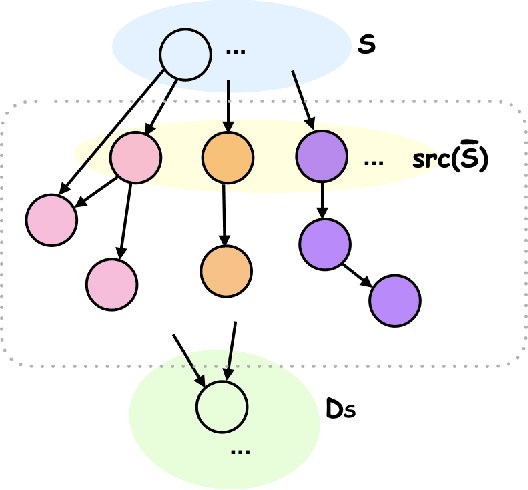
Many questions in science center around the fundamental problem of understanding causal relationships. However, most constraint-based causal discovery algorithms, including the well-celebrated PC algorithm, often incur an exponential number of conditional independence (CI) tests, posing limitations in various applications. Addressing this, our work focuses on characterizing what can be learned about the underlying causal graph with a reduced number of CI tests. We show that it is possible to a learn a coarser representation of the hidden causal graph with a polynomial number of tests. This coarser representation, named Causal Consistent Partition Graph (CCPG), comprises of a partition of the vertices and a directed graph defined over its components. CCPG satisfies consistency of orientations and additional constraints which favor finer partitions. Furthermore, it reduces to the underlying causal graph when the causal graph is identifiable. As a consequence, our results offer the first efficient algorithm for recovering the true causal graph with a polynomial number of tests, in special cases where the causal graph is fully identifiable through observational data and potentially additional interventions.
Quantifying the Gain in Weak-to-Strong Generalization
May 24, 2024
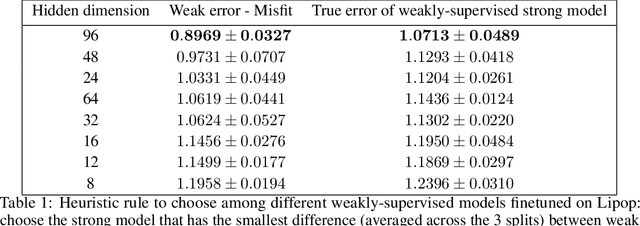


Recent advances in large language models have shown capabilities that are extraordinary and near-superhuman. These models operate with such complexity that reliably evaluating and aligning them proves challenging for humans. This leads to the natural question: can guidance from weak models (like humans) adequately direct the capabilities of strong models? In a recent and somewhat surprising work, Burns et al. (2023) empirically demonstrated that when strong models (like GPT-4) are finetuned using labels generated by weak supervisors (like GPT-2), the strong models outperform their weaker counterparts -- a phenomenon they term weak-to-strong generalization. In this work, we present a theoretical framework for understanding weak-to-strong generalization. Specifically, we show that the improvement in performance achieved by strong models over their weaker counterparts is quantified by the misfit error incurred by the strong model on labels generated by the weaker model. Our theory reveals several curious algorithmic insights. For instance, we can predict the amount by which the strong model will improve over the weak model, and also choose among different weak models to train the strong model, based on its misfit error. We validate our theoretical findings through various empirical assessments.
Membership Testing in Markov Equivalence Classes via Independence Query Oracles
Mar 09, 2024Understanding causal relationships between variables is a fundamental problem with broad impact in numerous scientific fields. While extensive research has been dedicated to learning causal graphs from data, its complementary concept of testing causal relationships has remained largely unexplored. While learning involves the task of recovering the Markov equivalence class (MEC) of the underlying causal graph from observational data, the testing counterpart addresses the following critical question: Given a specific MEC and observational data from some causal graph, can we determine if the data-generating causal graph belongs to the given MEC? We explore constraint-based testing methods by establishing bounds on the required number of conditional independence tests. Our bounds are in terms of the size of the maximum undirected clique ($s$) of the given MEC. In the worst case, we show a lower bound of $\exp(\Omega(s))$ independence tests. We then give an algorithm that resolves the task with $\exp(O(s))$ tests, matching our lower bound. Compared to the learning problem, where algorithms often use a number of independence tests that is exponential in the maximum in-degree, this shows that testing is relatively easier. In particular, it requires exponentially less independence tests in graphs featuring high in-degrees and small clique sizes. Additionally, using the DAG associahedron, we provide a geometric interpretation of testing versus learning and discuss how our testing result can aid learning.
Causal Discovery under Off-Target Interventions
Feb 13, 2024



Causal graph discovery is a significant problem with applications across various disciplines. However, with observational data alone, the underlying causal graph can only be recovered up to its Markov equivalence class, and further assumptions or interventions are necessary to narrow down the true graph. This work addresses the causal discovery problem under the setting of stochastic interventions with the natural goal of minimizing the number of interventions performed. We propose the following stochastic intervention model which subsumes existing adaptive noiseless interventions in the literature while capturing scenarios such as fat-hand interventions and CRISPR gene knockouts: any intervention attempt results in an actual intervention on a random subset of vertices, drawn from a distribution dependent on attempted action. Under this model, we study the two fundamental problems in causal discovery of verification and search and provide approximation algorithms with polylogarithmic competitive ratios and provide some preliminary experimental results.
Testing with Non-identically Distributed Samples
Nov 19, 2023
We examine the extent to which sublinear-sample property testing and estimation applies to settings where samples are independently but not identically distributed. Specifically, we consider the following distributional property testing framework: Suppose there is a set of distributions over a discrete support of size $k$, $\textbf{p}_1, \textbf{p}_2,\ldots,\textbf{p}_T$, and we obtain $c$ independent draws from each distribution. Suppose the goal is to learn or test a property of the average distribution, $\textbf{p}_{\mathrm{avg}}$. This setup models a number of important practical settings where the individual distributions correspond to heterogeneous entities -- either individuals, chronologically distinct time periods, spatially separated data sources, etc. From a learning standpoint, even with $c=1$ samples from each distribution, $\Theta(k/\varepsilon^2)$ samples are necessary and sufficient to learn $\textbf{p}_{\mathrm{avg}}$ to within error $\varepsilon$ in TV distance. To test uniformity or identity -- distinguishing the case that $\textbf{p}_{\mathrm{avg}}$ is equal to some reference distribution, versus has $\ell_1$ distance at least $\varepsilon$ from the reference distribution, we show that a linear number of samples in $k$ is necessary given $c=1$ samples from each distribution. In contrast, for $c \ge 2$, we recover the usual sublinear sample testing of the i.i.d. setting: we show that $O(\sqrt{k}/\varepsilon^2 + 1/\varepsilon^4)$ samples are sufficient, matching the optimal sample complexity in the i.i.d. case in the regime where $\varepsilon \ge k^{-1/4}$. Additionally, we show that in the $c=2$ case, there is a constant $\rho > 0$ such that even in the linear regime with $\rho k$ samples, no tester that considers the multiset of samples (ignoring which samples were drawn from the same $\textbf{p}_i$) can perform uniformity testing.