 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity estimation for Hellinger via minimum-distance estimators: mixtures of Gaussians, log-concave, and more
Jun 09, 2026We study the task of density estimation, where we hope to accurately estimate a probability density from $n$ samples. A textbook method for density estimation in total variation distance is the minimum-distance estimator approach, where we conclude both the algorithm and the analysis merely from bounding the VC dimension of a particular concept class (the so-called Yatracos class). While this technique has originally yielded sharp guarantees primarily for total variation distance, in this work we extend the minimum-distance estimator approach for learning within Hellinger distance. Our main observation is that we may produce an analogous recipe for Hellinger (where we only require bounding the VC dimension of a related concept class) by drawing connections to recent results yielding reverse data processing inequalities. This recipe is flexible enough to accommodate fast algorithms originally designed for total variation distance; by modifying the approach of Acharya et al. (2017) we conclude the first near-linear time algorithm for learning classes including univariate mixtures of log-concave densities and mixtures of Gaussians (with arbitrary variances), with near-optimal sample complexity.
Ratio Covers of Convex Sets and Optimal Mixture Density Estimation
Feb 18, 2026We study density estimation in Kullback-Leibler divergence: given an i.i.d. sample from an unknown density $p$, the goal is to construct an estimator $\widehat p$ such that $\mathrm{KL}(p,\widehat p)$ is small with high probability. We consider two settings involving a finite dictionary of $M$ densities: (i) model aggregation, where $p$ belongs to the dictionary, and (ii) convex aggregation (mixture density estimation), where $p$ is a mixture of densities from the dictionary. Crucially, we make no assumption on the base densities: their ratios may be unbounded and their supports may differ. For both problems, we identify the best possible high-probability guarantees in terms of the dictionary size, sample size, and confidence level. These optimal rates are higher than those achievable when density ratios are bounded by absolute constants; for mixture density estimation, they match existing lower bounds in the special case of discrete distributions. Our analysis of the mixture case hinges on two new covering results. First, we provide a sharp, distribution-free upper bound on the local Hellinger entropy of the class of mixtures of $M$ distributions. Second, we prove an optimal ratio covering theorem for convex sets: for every convex compact set $K\subset \mathbb{R}_+^d$, there exists a subset $A\subset K$ with at most $2^{8d}$ elements such that each element of $K$ is coordinate-wise dominated by an element of $A$ up to a universal constant factor. This geometric result is of independent interest; notably, it yields new cardinality estimates for $\varepsilon$-approximate Pareto sets in multi-objective optimization when the attainable set of objective vectors is convex.
Lower Bounds for Greedy Teaching Set Constructions
May 06, 2025A fundamental open problem in learning theory is to characterize the best-case teaching dimension $\operatorname{TS}_{\min}$ of a concept class $\mathcal{C}$ with finite VC dimension $d$. Resolving this problem will, in particular, settle the conjectured upper bound on Recursive Teaching Dimension posed by [Simon and Zilles; COLT 2015]. Prior work used a natural greedy algorithm to construct teaching sets recursively, thereby proving upper bounds on $\operatorname{TS}_{\min}$, with the best known bound being $O(d^2)$ [Hu, Wu, Li, and Wang; COLT 2017]. In each iteration, this greedy algorithm chooses to add to the teaching set the $k$ labeled points that restrict the concept class the most. In this work, we prove lower bounds on the performance of this greedy approach for small $k$. Specifically, we show that for $k = 1$, the algorithm does not improve upon the halving-based bound of $O(\log(|\mathcal{C}|))$. Furthermore, for $k = 2$, we complement the upper bound of $O\left(\log(\log(|\mathcal{C}|))\right)$ from [Moran, Shpilka, Wigderson, and Yuhudayoff; FOCS 2015] with a matching lower bound. Most consequentially, our lower bound extends up to $k \le \lceil c d \rceil$ for small constant $c>0$: suggesting that studying higher-order interactions may be necessary to resolve the conjecture that $\operatorname{TS}_{\min} = O(d)$.
Attainability of Two-Point Testing Rates for Finite-Sample Location Estimation
Feb 09, 2025


LeCam's two-point testing method yields perhaps the simplest lower bound for estimating the mean of a distribution: roughly, if it is impossible to well-distinguish a distribution centered at $\mu$ from the same distribution centered at $\mu+\Delta$, then it is impossible to estimate the mean by better than $\Delta/2$. It is setting-dependent whether or not a nearly matching upper bound is attainable. We study the conditions under which the two-point testing lower bound can be attained for univariate mean estimation; both in the setting of location estimation (where the distribution is known up to translation) and adaptive location estimation (unknown distribution). Roughly, we will say an estimate nearly attains the two-point testing lower bound if it incurs error that is at most polylogarithmically larger than the Hellinger modulus of continuity for $\tilde{\Omega}(n)$ samples. Adaptive location estimation is particularly interesting as some distributions admit much better guarantees than sub-Gaussian rates (e.g. $\operatorname{Unif}(\mu-1,\mu+1)$ permits error $\Theta(\frac{1}{n})$, while the sub-Gaussian rate is $\Theta(\frac{1}{\sqrt{n}})$), yet it is not obvious whether these rates may be adaptively attained by one unified approach. Our main result designs an algorithm that nearly attains the two-point testing rate for mixtures of symmetric, log-concave distributions with a common mean. Moreover, this algorithm runs in near-linear time and is parameter-free. In contrast, we show the two-point testing rate is not nearly attainable even for symmetric, unimodal distributions. We complement this with results for location estimation, showing the two-point testing rate is nearly attainable for unimodal distributions, but unattainable for symmetric distributions.
Near-Optimal Mean Estimation with Unknown, Heteroskedastic Variances
Dec 05, 2023
Given data drawn from a collection of Gaussian variables with a common mean but different and unknown variances, what is the best algorithm for estimating their common mean? We present an intuitive and efficient algorithm for this task. As different closed-form guarantees can be hard to compare, the Subset-of-Signals model serves as a benchmark for heteroskedastic mean estimation: given $n$ Gaussian variables with an unknown subset of $m$ variables having variance bounded by 1, what is the optimal estimation error as a function of $n$ and $m$? Our algorithm resolves this open question up to logarithmic factors, improving upon the previous best known estimation error by polynomial factors when $m = n^c$ for all $0<c<1$. Of particular note, we obtain error $o(1)$ with $m = \tilde{O}(n^{1/4})$ variance-bounded samples, whereas previous work required $m = \tilde{\Omega}(n^{1/2})$. Finally, we show that in the multi-dimensional setting, even for $d=2$, our techniques enable rates comparable to knowing the variance of each sample.
Entropic Causal Inference: Identifiability and Finite Sample Results
Jan 10, 2021
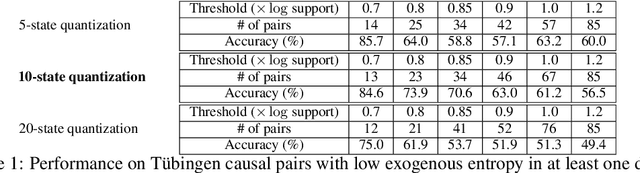
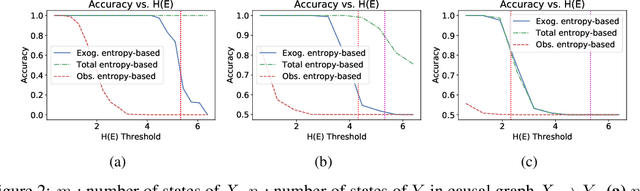
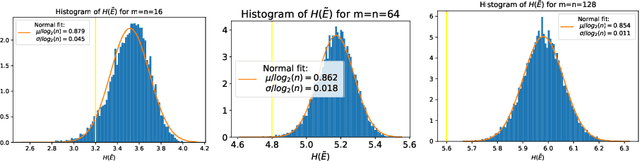
Entropic causal inference is a framework for inferring the causal direction between two categorical variables from observational data. The central assumption is that the amount of unobserved randomness in the system is not too large. This unobserved randomness is measured by the entropy of the exogenous variable in the underlying structural causal model, which governs the causal relation between the observed variables. Kocaoglu et al. conjectured that the causal direction is identifiable when the entropy of the exogenous variable is not too large. In this paper, we prove a variant of their conjecture. Namely, we show that for almost all causal models where the exogenous variable has entropy that does not scale with the number of states of the observed variables, the causal direction is identifiable from observational data. We also consider the minimum entropy coupling-based algorithmic approach presented by Kocaoglu et al., and for the first time demonstrate algorithmic identifiability guarantees using a finite number of samples. We conduct extensive experiments to evaluate the robustness of the method to relaxing some of the assumptions in our theory and demonstrate that both the constant-entropy exogenous variable and the no latent confounder assumptions can be relaxed in practice. We also empirically characterize the number of observational samples needed for causal identification. Finally, we apply the algorithm on Tuebingen cause-effect pairs dataset.