 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropic Causal Inference: Identifiability and Finite Sample Results
Jan 10, 2021
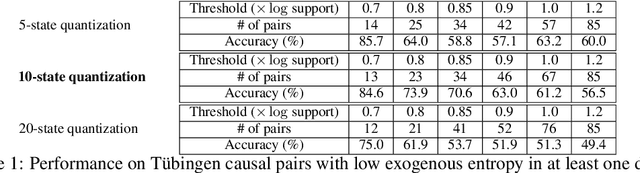
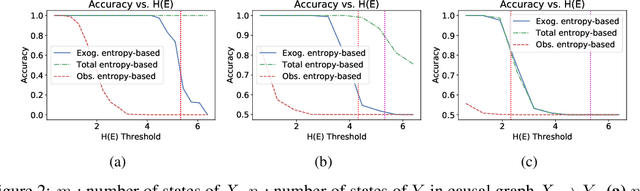
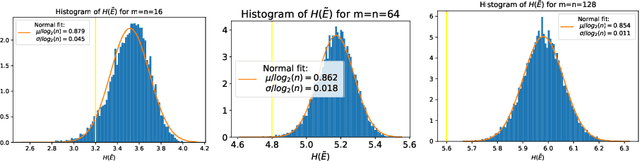
Entropic causal inference is a framework for inferring the causal direction between two categorical variables from observational data. The central assumption is that the amount of unobserved randomness in the system is not too large. This unobserved randomness is measured by the entropy of the exogenous variable in the underlying structural causal model, which governs the causal relation between the observed variables. Kocaoglu et al. conjectured that the causal direction is identifiable when the entropy of the exogenous variable is not too large. In this paper, we prove a variant of their conjecture. Namely, we show that for almost all causal models where the exogenous variable has entropy that does not scale with the number of states of the observed variables, the causal direction is identifiable from observational data. We also consider the minimum entropy coupling-based algorithmic approach presented by Kocaoglu et al., and for the first time demonstrate algorithmic identifiability guarantees using a finite number of samples. We conduct extensive experiments to evaluate the robustness of the method to relaxing some of the assumptions in our theory and demonstrate that both the constant-entropy exogenous variable and the no latent confounder assumptions can be relaxed in practice. We also empirically characterize the number of observational samples needed for causal identification. Finally, we apply the algorithm on Tuebingen cause-effect pairs dataset.
Active Structure Learning of Causal DAGs via Directed Clique Tree
Nov 01, 2020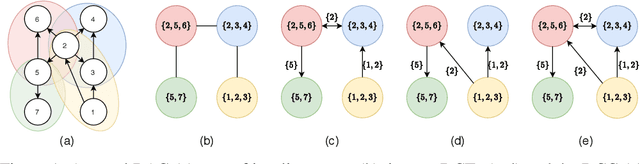
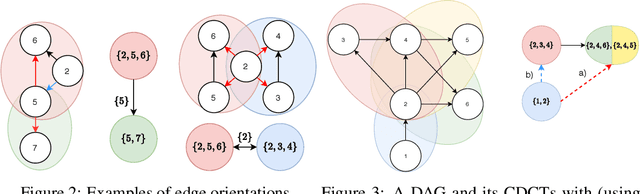


A growing body of work has begun to study intervention design for efficient structure learning of causal directed acyclic graphs (DAGs). A typical setting is a causally sufficient setting, i.e. a system with no latent confounders, selection bias, or feedback, when the essential graph of the observational equivalence class (EC) is given as an input and interventions are assumed to be noiseless. Most existing works focus on worst-case or average-case lower bounds for the number of interventions required to orient a DAG. These worst-case lower bounds only establish that the largest clique in the essential graph could make it difficult to learn the true DAG. In this work, we develop a universal lower bound for single-node interventions that establishes that the largest clique is always a fundamental impediment to structure learning. Specifically, we present a decomposition of a DAG into independently orientable components through directed clique trees and use it to prove that the number of single-node interventions necessary to orient any DAG in an EC is at least the sum of half the size of the largest cliques in each chain component of the essential graph. Moreover, we present a two-phase intervention design algorithm that, under certain conditions on the chordal skeleton, matches the optimal number of interventions up to a multiplicative logarithmic factor in the number of maximal cliques. We show via synthetic experiments that our algorithm can scale to much larger graphs than most of the related work and achieves better worst-case performance than other scalable approaches. A code base to recreate these results can be found at https://github.com/csquires/dct-policy
Size of Interventional Markov Equivalence Classes in Random DAG Models
Mar 05, 2019



Directed acyclic graph (DAG) models are popular for capturing causal relationships. From observational and interventional data, a DAG model can only be determined up to its \emph{interventional Markov equivalence class} (I-MEC). We investigate the size of MECs for random DAG models generated by uniformly sampling and ordering an Erd\H{o}s-R\'{e}nyi graph. For constant density, we show that the expected $\log$ observational MEC size asymptotically (in the number of vertices) approaches a constant. We characterize I-MEC size in a similar fashion in the above settings with high precision. We show that the asymptotic expected number of interventions required to fully identify a DAG is a constant. These results are obtained by exploiting Meek rules and coupling arguments to provide sharp upper and lower bounds on the asymptotic quantities, which are then calculated numerically up to high precision. Our results have important consequences for experimental design of interventions and the development of algorithms for causal inference.