 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Similarities Are Created Equal: Leveraging Data-Driven Biases to Inform GenAI Copyright Disputes
Paper and Code
Mar 26, 2024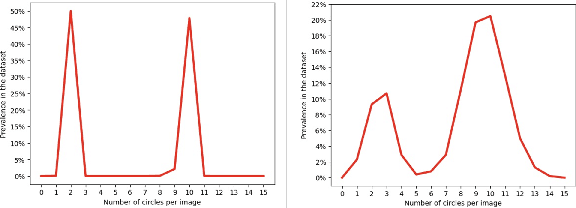
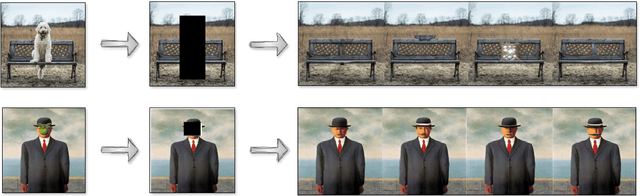
The advent of Generative Artificial Intelligence (GenAI) models, including GitHub Copilot, OpenAI GPT, and Stable Diffusion, has revolutionized content creation, enabling non-professionals to produce high-quality content across various domains. This transformative technology has led to a surge of synthetic content and sparked legal disputes over copyright infringement. To address these challenges, this paper introduces a novel approach that leverages the learning capacity of GenAI models for copyright legal analysis, demonstrated with GPT2 and Stable Diffusion models. Copyright law distinguishes between original expressions and generic ones (Sc\`enes \`a faire), protecting the former and permitting reproduction of the latter. However, this distinction has historically been challenging to make consistently, leading to over-protection of copyrighted works. GenAI offers an unprecedented opportunity to enhance this legal analysis by revealing shared patterns in preexisting works. We propose a data-driven approach to identify the genericity of works created by GenAI, employing "data-driven bias" to assess the genericity of expressive compositions. This approach aids in copyright scope determination by utilizing the capabilities of GenAI to identify and prioritize expressive elements and rank them according to their frequency in the model's dataset. The potential implications of measuring expressive genericity for copyright law are profound. Such scoring could assist courts in determining copyright scope during litigation, inform the registration practices of Copyright Offices, allowing registration of only highly original synthetic works, and help copyright owners signal the value of their works and facilitate fairer licensing deals. More generally, this approach offers valuable insights to policymakers grappling with adapting copyright law to the challenges posed by the era of GenAI.