 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiGnature: Explicit Motion Diffusion for Stylized Semantic Gesture
Jun 14, 2026While recent advances in co-speech gesture generation have achieved impressive rhythmic synchronization, synthesizing gestures that are both semantically meaningful and faithful to a speaker's unique non-verbal style remains an open challenge. Semantic gestures, such as iconic shapes or deictic pointing, are statistically sparse, making them difficult to learn effectively within standard generative models. We present SiGnature, a framework for Stylized and Semantic Gesture generation that reconciles precise semantic control with high-fidelity style preservation. Unlike prevalent methods that rely on entangled latent representations, SiGnature operates in an explicit joint-rotation space. This design enables our core contribution, Joint Motion Integration (JMI), a training-free inference mechanism capable of injecting any external motion sequence, particularly in-the-wild semantic gestures, directly into the diffusion process. JMI automatically identifies the specific ``active joints'' conveying a semantic action and injects them into the generation, while relying on the diffusion backbone to synthesize the remaining body dynamics, including posture and flow, in accordance with the pre-learned style of the target speaker. This allows for the plug-and-play integration of arbitrary motions, including complex semantic gestures, without retraining or introducing the ``Frankenstein'' artifacts typical of cut-and-paste methods. Extensive experiments and perceptual studies demonstrate that SiGnature offers superior semantic motion control while maintaining smooth and natural co-speech gesture generation and preserving the distinct characteristics of the speaker, thereby outperforming state-of-the-art baselines.
Gefen: Optimized Stochastic Optimizer
Jun 11, 2026AdamW is a default optimizer for modern deep learning, but its first and second moment states add roughly two parameter-sized buffers to training memory. We propose Gefen, a memory-efficient optimizer that automatically shares second-moment estimates across parameter blocks and quantizes the first moment using a learned codebook, thereby reducing AdamW's memory footprint by ~8x while maintaining the same performance, corresponding to a reduction of 6.5 GiB per billion parameters. The method is motivated by a theoretical result showing that large mixed Hessian entries constrain the ratio of squared gradients toward one, suggesting that Hessian-aligned parameters are natural candidates for sharing second-moment statistics. Since computing Hessians is impractical at scale, Gefen infers block structure from the initial squared gradients, requiring no architecture-specific metadata or hyperparameters beyond AdamW defaults. Gefen learns an exact histogram-based dynamic-programming quantization codebook and reuses the same blocks for first-moment scaling. Across diverse experiments, Gefen achieves the lowest peak optimizer memory among the compared AdamW-like methods while maintaining AdamW-level performance. In FSDP and DDP training, the reduced memory footprint enables larger microbatches and improves throughput significantly over AdamW, providing a practical drop-in replacement with lower memory usage that can increase throughput and enable training larger models or using larger batch sizes. We provide the complete Python implementation, including fused CUDA kernels at https://github.com/ndvbd/Gefen
Mirror Descent Beyond Euclidean Stability: An Exponential Separation in Initialization Sensitivity
Jun 09, 2026Mirror Descent (MD) extends Gradient Descent (GD) beyond Euclidean geometry and has recently reappeared as a lens for KL-regularized policy optimization in reinforcement learning and LLM post-training. This raises a basic robustness question, crucial to reproducibility and reliability: how sensitive are MD dynamics to their inputs? We focus on initialization, often itself a pretrained or previously aligned model. Quadratic-regularized MD, including GD and Mahalanobis geometries, is well-known to be stable for convex smooth objectives. We show a sharp contrast: once the regularizer is non-quadratic, MD can be exponentially more sensitive to initialization than GD, even with a well-conditioned regularizer in Euclidean norm. We give a three-dimensional construction with a convex, smooth objective and a strongly convex, smooth, well-conditioned regularizer where an initial $\varepsilon$ perturbation is quickly amplified to $\min\{\text{polylog}^{-1}(1/\varepsilon), \varepsilon e^{Ω(ηT)}\}$ after $T$ iterations of MD with step size $η$. For canonical KL-regularized MD on the simplex, we show that even linear objectives can amplify an initial $\varepsilon$ perturbation exponentially fast in high-dimensional or near-boundary regimes. Finally, we show that adding a Bregman regularization term toward an anchor point can stabilize the dynamics while largely preserving the optimization guarantees, and that the choice of anchor is crucial: anchoring at the initialization only partially mitigates the instability, whereas anchoring at a fixed point yields a more stable mechanism.
Near-Optimal Decentralized Stochastic Convex Optimization over Networks
Jun 03, 2026We study decentralized stochastic smooth convex optimization, where $M$ workers minimize an average objective using local stochastic gradients and neighbor-only communication over a fixed gossip network. A central question in this setting is to determine the largest number of workers that can be used under a total budget of $N$ gradient samples while still preserving the centralized $O(1/\sqrt N)$ statistical rate. We introduce an accelerated decentralized method that preserves this rate for up to $\smash{M\lesssim \sqrtρ\,N^{3/4}}$ workers, where $ρ$ is the spectral gap of the gossip network, improving the best prior maximal scaling of $\smash{M\lesssim ρ\sqrt N}$. The method is based on a one-step-delayed stochastic acceleration scheme that enables workers to interleave minibatching with accelerated gossip while controlling residual disagreement, and its guarantee depends only logarithmically on the optimum-local heterogeneity. We also establish a matching lower bound for linear-span decentralized first-order methods, showing that the method is optimal up to logarithmic factors.
The Sample Complexity of Multiclass and Sparse Contextual Bandits
May 28, 2026We study contextual bandits in the stochastic i.i.d.\ setting, where a learner observes contexts drawn from an unknown distribution, selects actions from a finite set $A$, and aims to identify an approximately optimal policy from a given class based on bandit feedback. Motivated by bandit multiclass classification with zero-one rewards, we focus on the \emph{$s$-sparse} setting in which, for every context, the reward vector has $L_1$-norm at most $s \ll |A|$. Our main result is the design of algorithms that, with high probability, output an $ε$-optimal policy compared to policy class $Π$ using $\tilde{O} ((s/ε^2 + |A|/ε)\log |Π|/δ)$ samples. We extend this bound to general Natarajan classes and complement it with a matching lower bound (up to logarithmic factors), thereby closing a substantial gap left by prior work (Erez et al., 2024, 2025), which incurred an additional $Θ(|A|^9)$ dependence. We obtain these results via two complementary approaches. First, we analyze contextual bandits through the lens of contextual decision making with structured observations, designing an exploration-by-optimization algorithm whose sample complexity is governed by the \emph{decision-estimation coefficient} (DEC; Foster et al., 2021, 2022). We show that, with $s$-sparse rewards, the induced model class admits a sharp DEC bound that scales with $s$ and directly yields the optimal rate. Since this approach is largely information-theoretic and involves solving complex min-max optimization problems, we also develop a second, more specialized algorithmic method based on a low-variance exploration technique. This approach leads to concrete, tractable algorithms and naturally extends to contextual combinatorial semi-bandits, leading to improved sample complexity guarantees for bandit multiclass list classification.
Statistical Learning from Attribution Sets
Feb 06, 2026We address the problem of training conversion prediction models in advertising domains under privacy constraints, where direct links between ad clicks and conversions are unavailable. Motivated by privacy-preserving browser APIs and the deprecation of third-party cookies, we study a setting where the learner observes a sequence of clicks and a sequence of conversions, but can only link a conversion to a set of candidate clicks (an attribution set) rather than a unique source. We formalize this as learning from attribution sets generated by an oblivious adversary equipped with a prior distribution over the candidates. Despite the lack of explicit labels, we construct an unbiased estimator of the population loss from these coarse signals via a novel approach. Leveraging this estimator, we show that Empirical Risk Minimization achieves generalization guarantees that scale with the informativeness of the prior and is also robust against estimation errors in the prior, despite complex dependencies among attribution sets. Simple empirical evaluations on standard datasets suggest our unbiased approach significantly outperforms common industry heuristics, particularly in regimes where attribution sets are large or overlapping.
Sample Complexity of Agnostic Multiclass Classification: Natarajan Dimension Strikes Back
Nov 16, 2025The fundamental theorem of statistical learning states that binary PAC learning is governed by a single parameter -- the Vapnik-Chervonenkis (VC) dimension -- which determines both learnability and sample complexity. Extending this to multiclass classification has long been challenging, since Natarajan's work in the late 80s proposing the Natarajan dimension (Nat) as a natural analogue of VC. Daniely and Shalev-Shwartz (2014) introduced the DS dimension, later shown by Brukhim et al. (2022) to characterize multiclass learnability. Brukhim et al. also showed that Nat and DS can diverge arbitrarily, suggesting that multiclass learning is governed by DS rather than Nat. We show that agnostic multiclass PAC sample complexity is in fact governed by two distinct dimensions. Specifically, we prove nearly tight agnostic sample complexity bounds that, up to log factors, take the form $\frac{DS^{1.5}}ε + \frac{Nat}{ε^2}$ where $ε$ is the excess risk. This bound is tight up to a $\sqrt{DS}$ factor in the first term, nearly matching known $Nat/ε^2$ and $DS/ε$ lower bounds. The first term reflects the DS-controlled regime, while the second shows that the Natarajan dimension still dictates asymptotic behavior for small $ε$. Thus, unlike binary or online classification -- where a single dimension (VC or Littlestone) controls both phenomena -- multiclass learning inherently involves two structural parameters. Our technical approach departs from traditional agnostic learning methods based on uniform convergence or reductions to realizable cases. A key ingredient is a novel online procedure based on a self-adaptive multiplicative-weights algorithm performing a label-space reduction, which may be of independent interest.
Flat Minima and Generalization: Insights from Stochastic Convex Optimization
Nov 05, 2025Understanding the generalization behavior of learning algorithms is a central goal of learning theory. A recently emerging explanation is that learning algorithms are successful in practice because they converge to flat minima, which have been consistently associated with improved generalization performance. In this work, we study the link between flat minima and generalization in the canonical setting of stochastic convex optimization with a non-negative, $\beta$-smooth objective. Our first finding is that, even in this fundamental and well-studied setting, flat empirical minima may incur trivial $\Omega(1)$ population risk while sharp minima generalizes optimally. Then, we show that this poor generalization behavior extends to two natural ''sharpness-aware'' algorithms originally proposed by Foret et al. (2021), designed to bias optimization toward flat solutions: Sharpness-Aware Gradient Descent (SA-GD) and Sharpness-Aware Minimization (SAM). For SA-GD, which performs gradient steps on the maximal loss in a predefined neighborhood, we prove that while it successfully converges to a flat minimum at a fast rate, the population risk of the solution can still be as large as $\Omega(1)$, indicating that even flat minima found algorithmically using a sharpness-aware gradient method might generalize poorly. For SAM, a computationally efficient approximation of SA-GD based on normalized ascent steps, we show that although it minimizes the empirical loss, it may converge to a sharp minimum and also incur population risk $\Omega(1)$. Finally, we establish population risk upper bounds for both SA-GD and SAM using algorithmic stability techniques.
Optimal Learning from Label Proportions with General Loss Functions
Sep 18, 2025


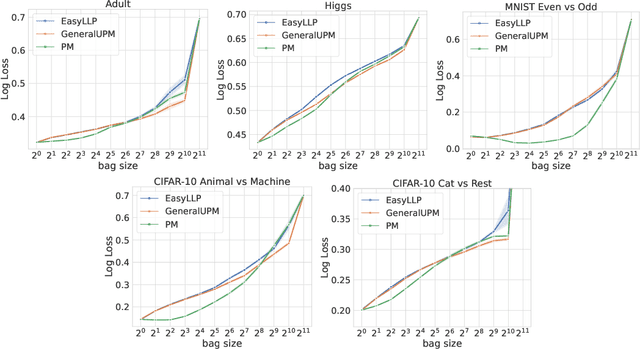
Motivated by problems in online advertising, we address the task of Learning from Label Proportions (LLP). In this partially-supervised setting, training data consists of groups of examples, termed bags, for which we only observe the average label value. The main goal, however, remains the design of a predictor for the labels of individual examples. We introduce a novel and versatile low-variance de-biasing methodology to learn from aggregate label information, significantly advancing the state of the art in LLP. Our approach exhibits remarkable flexibility, seamlessly accommodating a broad spectrum of practically relevant loss functions across both binary and multi-class classification settings. By carefully combining our estimators with standard techniques, we substantially improve sample complexity guarantees for a large class of losses of practical relevance. We also empirically validate the efficacy of our proposed approach across a diverse array of benchmark datasets, demonstrating compelling empirical advantages over standard baselines.
Optimal Rates in Continual Linear Regression via Increasing Regularization
Jun 06, 2025We study realizable continual linear regression under random task orderings, a common setting for developing continual learning theory. In this setup, the worst-case expected loss after $k$ learning iterations admits a lower bound of $\Omega(1/k)$. However, prior work using an unregularized scheme has only established an upper bound of $O(1/k^{1/4})$, leaving a significant gap. Our paper proves that this gap can be narrowed, or even closed, using two frequently used regularization schemes: (1) explicit isotropic $\ell_2$ regularization, and (2) implicit regularization via finite step budgets. We show that these approaches, which are used in practice to mitigate forgetting, reduce to stochastic gradient descent (SGD) on carefully defined surrogate losses. Through this lens, we identify a fixed regularization strength that yields a near-optimal rate of $O(\log k / k)$. Moreover, formalizing and analyzing a generalized variant of SGD for time-varying functions, we derive an increasing regularization strength schedule that provably achieves an optimal rate of $O(1/k)$. This suggests that schedules that increase the regularization coefficient or decrease the number of steps per task are beneficial, at least in the worst case.