 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Decentralized Stochastic Convex Optimization over Networks
Jun 03, 2026We study decentralized stochastic smooth convex optimization, where $M$ workers minimize an average objective using local stochastic gradients and neighbor-only communication over a fixed gossip network. A central question in this setting is to determine the largest number of workers that can be used under a total budget of $N$ gradient samples while still preserving the centralized $O(1/\sqrt N)$ statistical rate. We introduce an accelerated decentralized method that preserves this rate for up to $\smash{M\lesssim \sqrtρ\,N^{3/4}}$ workers, where $ρ$ is the spectral gap of the gossip network, improving the best prior maximal scaling of $\smash{M\lesssim ρ\sqrt N}$. The method is based on a one-step-delayed stochastic acceleration scheme that enables workers to interleave minibatching with accelerated gossip while controlling residual disagreement, and its guarantee depends only logarithmically on the optimum-local heterogeneity. We also establish a matching lower bound for linear-span decentralized first-order methods, showing that the method is optimal up to logarithmic factors.
Optimal Rates in Continual Linear Regression via Increasing Regularization
Jun 06, 2025We study realizable continual linear regression under random task orderings, a common setting for developing continual learning theory. In this setup, the worst-case expected loss after $k$ learning iterations admits a lower bound of $\Omega(1/k)$. However, prior work using an unregularized scheme has only established an upper bound of $O(1/k^{1/4})$, leaving a significant gap. Our paper proves that this gap can be narrowed, or even closed, using two frequently used regularization schemes: (1) explicit isotropic $\ell_2$ regularization, and (2) implicit regularization via finite step budgets. We show that these approaches, which are used in practice to mitigate forgetting, reduce to stochastic gradient descent (SGD) on carefully defined surrogate losses. Through this lens, we identify a fixed regularization strength that yields a near-optimal rate of $O(\log k / k)$. Moreover, formalizing and analyzing a generalized variant of SGD for time-varying functions, we derive an increasing regularization strength schedule that provably achieves an optimal rate of $O(1/k)$. This suggests that schedules that increase the regularization coefficient or decrease the number of steps per task are beneficial, at least in the worst case.
Benefits of Learning Rate Annealing for Tuning-Robustness in Stochastic Optimization
Mar 12, 2025


The learning rate in stochastic gradient methods is a critical hyperparameter that is notoriously costly to tune via standard grid search, especially for training modern large-scale models with billions of parameters. We identify a theoretical advantage of learning rate annealing schemes that decay the learning rate to zero at a polynomial rate, such as the widely-used cosine schedule, by demonstrating their increased robustness to initial parameter misspecification due to a coarse grid search. We present an analysis in a stochastic convex optimization setup demonstrating that the convergence rate of stochastic gradient descent with annealed schedules depends sublinearly on the multiplicative misspecification factor $\rho$ (i.e., the grid resolution), achieving a rate of $O(\rho^{1/(2p+1)}/\sqrt{T})$ where $p$ is the degree of polynomial decay and $T$ is the number of steps, in contrast to the $O(\rho/\sqrt{T})$ rate that arises with fixed stepsizes and exhibits a linear dependence on $\rho$. Experiments confirm the increased robustness compared to tuning with a fixed stepsize, that has significant implications for the computational overhead of hyperparameter search in practical training scenarios.
Faster Stochastic Optimization with Arbitrary Delays via Asynchronous Mini-Batching
Aug 14, 2024
We consider the problem of asynchronous stochastic optimization, where an optimization algorithm makes updates based on stale stochastic gradients of the objective that are subject to an arbitrary (possibly adversarial) sequence of delays. We present a procedure which, for any given $q \in (0,1]$, transforms any standard stochastic first-order method to an asynchronous method with convergence guarantee depending on the $q$-quantile delay of the sequence. This approach leads to convergence rates of the form $O(\tau_q/qT+\sigma/\sqrt{qT})$ for non-convex and $O(\tau_q^2/(q T)^2+\sigma/\sqrt{qT})$ for convex smooth problems, where $\tau_q$ is the $q$-quantile delay, generalizing and improving on existing results that depend on the average delay. We further show a method that automatically adapts to all quantiles simultaneously, without any prior knowledge of the delays, achieving convergence rates of the form $O(\inf_{q} \tau_q/qT+\sigma/\sqrt{qT})$ for non-convex and $O(\inf_{q} \tau_q^2/(q T)^2+\sigma/\sqrt{qT})$ for convex smooth problems. Our technique is based on asynchronous mini-batching with a careful batch-size selection and filtering of stale gradients.
A Note on High-Probability Analysis of Algorithms with Exponential, Sub-Gaussian, and General Light Tails
Mar 05, 2024This short note describes a simple technique for analyzing probabilistic algorithms that rely on a light-tailed (but not necessarily bounded) source of randomization. We show that the analysis of such an algorithm can be reduced, in a black-box manner and with only a small loss in logarithmic factors, to an analysis of a simpler variant of the same algorithm that uses bounded random variables and often easier to analyze. This approach simultaneously applies to any light-tailed randomization, including exponential, sub-Gaussian, and more general fast-decaying distributions, without needing to appeal to specialized concentration inequalities. Analyses of a generalized Azuma inequality and stochastic optimization with general light-tailed noise are provided to illustrate the technique.
How Free is Parameter-Free Stochastic Optimization?
Feb 05, 2024We study the problem of parameter-free stochastic optimization, inquiring whether, and under what conditions, do fully parameter-free methods exist: these are methods that achieve convergence rates competitive with optimally tuned methods, without requiring significant knowledge of the true problem parameters. Existing parameter-free methods can only be considered ``partially'' parameter-free, as they require some non-trivial knowledge of the true problem parameters, such as a bound on the stochastic gradient norms, a bound on the distance to a minimizer, etc. In the non-convex setting, we demonstrate that a simple hyperparameter search technique results in a fully parameter-free method that outperforms more sophisticated state-of-the-art algorithms. We also provide a similar result in the convex setting with access to noisy function values under mild noise assumptions. Finally, assuming only access to stochastic gradients, we establish a lower bound that renders fully parameter-free stochastic convex optimization infeasible, and provide a method which is (partially) parameter-free up to the limit indicated by our lower bound.
SGD with AdaGrad Stepsizes: Full Adaptivity with High Probability to Unknown Parameters, Unbounded Gradients and Affine Variance
Feb 17, 2023We study Stochastic Gradient Descent with AdaGrad stepsizes: a popular adaptive (self-tuning) method for first-order stochastic optimization. Despite being well studied, existing analyses of this method suffer from various shortcomings: they either assume some knowledge of the problem parameters, impose strong global Lipschitz conditions, or fail to give bounds that hold with high probability. We provide a comprehensive analysis of this basic method without any of these limitations, in both the convex and non-convex (smooth) cases, that additionally supports a general ``affine variance'' noise model and provides sharp rates of convergence in both the low-noise and high-noise~regimes.
Uniform Stability for First-Order Empirical Risk Minimization
Jul 17, 2022We consider the problem of designing uniformly stable first-order optimization algorithms for empirical risk minimization. Uniform stability is often used to obtain generalization error bounds for optimization algorithms, and we are interested in a general approach to achieve it. For Euclidean geometry, we suggest a black-box conversion which given a smooth optimization algorithm, produces a uniformly stable version of the algorithm while maintaining its convergence rate up to logarithmic factors. Using this reduction we obtain a (nearly) optimal algorithm for smooth optimization with convergence rate $\widetilde{O}(1/T^2)$ and uniform stability $O(T^2/n)$, resolving an open problem of Chen et al. (2018); Attia and Koren (2021). For more general geometries, we develop a variant of Mirror Descent for smooth optimization with convergence rate $\widetilde{O}(1/T)$ and uniform stability $O(T/n)$, leaving open the question of devising a general conversion method as in the Euclidean case.
The Instability of Accelerated Gradient Descent
Feb 03, 2021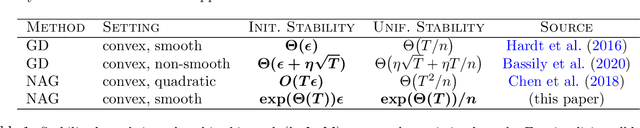
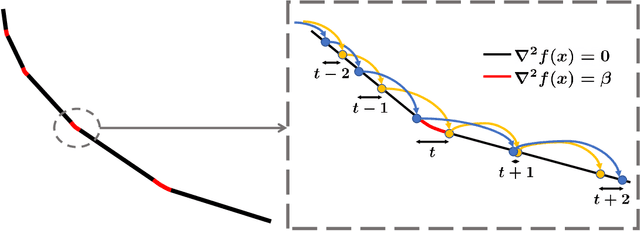
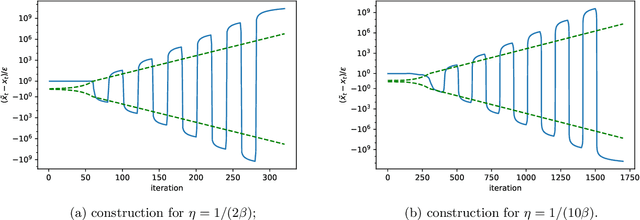
We study the algorithmic stability of Nesterov's accelerated gradient method. For convex quadratic objectives, \citet{chen2018stability} proved that the uniform stability of the method grows quadratically with the number of optimization steps, and conjectured that the same is true for the general convex and smooth case. We disprove this conjecture and show, for two notions of stability, that the stability of Nesterov's accelerated method in fact deteriorates \emph{exponentially fast} with the number of gradient steps. This stands in sharp contrast to the bounds in the quadratic case, but also to known results for non-accelerated gradient methods where stability typically grows linearly with the number of steps.