 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Rates in Continual Linear Regression via Increasing Regularization
Jun 06, 2025We study realizable continual linear regression under random task orderings, a common setting for developing continual learning theory. In this setup, the worst-case expected loss after $k$ learning iterations admits a lower bound of $\Omega(1/k)$. However, prior work using an unregularized scheme has only established an upper bound of $O(1/k^{1/4})$, leaving a significant gap. Our paper proves that this gap can be narrowed, or even closed, using two frequently used regularization schemes: (1) explicit isotropic $\ell_2$ regularization, and (2) implicit regularization via finite step budgets. We show that these approaches, which are used in practice to mitigate forgetting, reduce to stochastic gradient descent (SGD) on carefully defined surrogate losses. Through this lens, we identify a fixed regularization strength that yields a near-optimal rate of $O(\log k / k)$. Moreover, formalizing and analyzing a generalized variant of SGD for time-varying functions, we derive an increasing regularization strength schedule that provably achieves an optimal rate of $O(1/k)$. This suggests that schedules that increase the regularization coefficient or decrease the number of steps per task are beneficial, at least in the worst case.
Better Rates for Random Task Orderings in Continual Linear Models
Apr 06, 2025


We study the common continual learning setup where an overparameterized model is sequentially fitted to a set of jointly realizable tasks. We analyze the forgetting, i.e., loss on previously seen tasks, after $k$ iterations. For linear models, we prove that fitting a task is equivalent to a single stochastic gradient descent (SGD) step on a modified objective. We develop novel last-iterate SGD upper bounds in the realizable least squares setup, and apply them to derive new results for continual learning. Focusing on random orderings over $T$ tasks, we establish universal forgetting rates, whereas existing rates depend on the problem dimensionality or complexity. Specifically, in continual regression with replacement, we improve the best existing rate from $O((d-r)/k)$ to $O(\min(k^{-1/4}, \sqrt{d-r}/k, \sqrt{Tr}/k))$, where $d$ is the dimensionality and $r$ the average task rank. Furthermore, we establish the first rates for random task orderings without replacement. The obtained rate of $O(\min(T^{-1/4}, (d-r)/T))$ proves for the first time that randomization alone, with no task repetition, can prevent catastrophic forgetting in sufficiently long task sequences. Finally, we prove a similar $O(k^{-1/4})$ universal rate for the forgetting in continual linear classification on separable data. Our universal rates apply for broader projection methods, such as block Kaczmarz and POCS, illuminating their loss convergence under i.i.d and one-pass orderings.
The Dimension Strikes Back with Gradients: Generalization of Gradient Methods in Stochastic Convex Optimization
Jan 22, 2024We study the generalization performance of gradient methods in the fundamental stochastic convex optimization setting, focusing on its dimension dependence. First, for full-batch gradient descent (GD) we give a construction of a learning problem in dimension $d=O(n^2)$, where the canonical version of GD (tuned for optimal performance of the empirical risk) trained with $n$ training examples converges, with constant probability, to an approximate empirical risk minimizer with $\Omega(1)$ population excess risk. Our bound translates to a lower bound of $\Omega (\sqrt{d})$ on the number of training examples required for standard GD to reach a non-trivial test error, answering an open question raised by Feldman (2016) and Amir, Koren, and Livni (2021b) and showing that a non-trivial dimension dependence is unavoidable. Furthermore, for standard one-pass stochastic gradient descent (SGD), we show that an application of the same construction technique provides a similar $\Omega(\sqrt{d})$ lower bound for the sample complexity of SGD to reach a non-trivial empirical error, despite achieving optimal test performance. This again provides an exponential improvement in the dimension dependence compared to previous work (Koren, Livni, Mansour, and Sherman, 2022), resolving an open question left therein.
Rate-Optimal Policy Optimization for Linear Markov Decision Processes
Aug 28, 2023We study regret minimization in online episodic linear Markov Decision Processes, and obtain rate-optimal $\widetilde O (\sqrt K)$ regret where $K$ denotes the number of episodes. Our work is the first to establish the optimal (w.r.t.~$K$) rate of convergence in the stochastic setting with bandit feedback using a policy optimization based approach, and the first to establish the optimal (w.r.t.~$K$) rate in the adversarial setup with full information feedback, for which no algorithm with an optimal rate guarantee is currently known.
Improved Regret for Efficient Online Reinforcement Learning with Linear Function Approximation
Jan 30, 2023We study reinforcement learning with linear function approximation and adversarially changing cost functions, a setup that has mostly been considered under simplifying assumptions such as full information feedback or exploratory conditions.We present a computationally efficient policy optimization algorithm for the challenging general setting of unknown dynamics and bandit feedback, featuring a combination of mirror-descent and least squares policy evaluation in an auxiliary MDP used to compute exploration bonuses.Our algorithm obtains an $\widetilde O(K^{6/7})$ regret bound, improving significantly over previous state-of-the-art of $\widetilde O (K^{14/15})$ in this setting. In addition, we present a version of the same algorithm under the assumption a simulator of the environment is available to the learner (but otherwise no exploratory assumptions are made), and prove it obtains state-of-the-art regret of $\widetilde O (K^{2/3})$.
Regret Minimization and Convergence to Equilibria in General-sum Markov Games
Aug 08, 2022

An abundance of recent impossibility results establish that regret minimization in Markov games with adversarial opponents is both statistically and computationally intractable. Nevertheless, none of these results preclude the possibility of regret minimization under the assumption that all parties adopt the same learning procedure. In this work, we present the first (to our knowledge) algorithm for learning in general-sum Markov games that provides sublinear regret guarantees when executed by all agents. The bounds we obtain are for swap regret, and thus, along the way, imply convergence to a correlated equilibrium. Our algorithm is decentralized, computationally efficient, and does not require any communication between agents. Our key observation is that online learning via policy optimization in Markov games essentially reduces to a form of weighted regret minimization, with unknown weights determined by the path length of the agents' policy sequence. Consequently, controlling the path length leads to weighted regret objectives for which sufficiently adaptive algorithms provide sublinear regret guarantees.
Benign Underfitting of Stochastic Gradient Descent
Mar 01, 2022
We study to what extent may stochastic gradient descent (SGD) be understood as a "conventional" learning rule that achieves generalization performance by obtaining a good fit to training data. We consider the fundamental stochastic convex optimization framework, where (one pass, without-replacement) SGD is classically known to minimize the population risk at rate $O(1/\sqrt n)$, and prove that, surprisingly, there exist problem instances where the SGD solution exhibits both empirical risk and generalization gap of $\Omega(1)$. Consequently, it turns out that SGD is not algorithmically stable in any sense, and its generalization ability cannot be explained by uniform convergence or any other currently known generalization bound technique for that matter (other than that of its classical analysis). We then continue to analyze the closely related with-replacement SGD, for which we show that an analogous phenomenon does not occur and prove that its population risk does in fact converge at the optimal rate. Finally, we interpret our main results in the context of without-replacement SGD for finite-sum convex optimization problems, and derive upper and lower bounds for the multi-epoch regime that significantly improve upon previously known results.
Optimal Rates for Random Order Online Optimization
Jun 29, 2021We study online convex optimization in the random order model, recently proposed by \citet{garber2020online}, where the loss functions may be chosen by an adversary, but are then presented to the online algorithm in a uniformly random order. Focusing on the scenario where the cumulative loss function is (strongly) convex, yet individual loss functions are smooth but might be non-convex, we give algorithms that achieve the optimal bounds and significantly outperform the results of \citet{garber2020online}, completely removing the dimension dependence and improving their scaling with respect to the strong convexity parameter. Our analysis relies on novel connections between algorithmic stability and generalization for sampling without-replacement analogous to those studied in the with-replacement i.i.d.~setting, as well as on a refined average stability analysis of stochastic gradient descent.
Lazy OCO: Online Convex Optimization on a Switching Budget
Feb 07, 2021
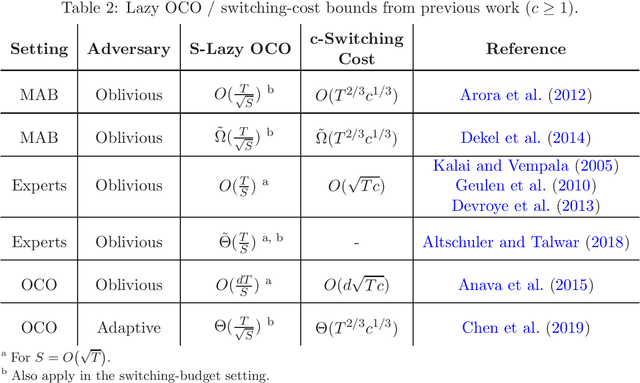
We study a variant of online convex optimization where the player is permitted to switch decisions at most $S$ times in expectation throughout $T$ rounds. Similar problems have been addressed in prior work for the discrete decision set setting, and more recently in the continuous setting but only with an adaptive adversary. In this work, we aim to fill the gap and present computationally efficient algorithms in the more prevalent oblivious setting, establishing a regret bound of $O(T/S)$ for general convex losses and $\widetilde O(T/S^2)$ for strongly convex losses. In addition, for stochastic i.i.d.~losses, we present a simple algorithm that performs $\log T$ switches with only a multiplicative $\log T$ factor overhead in its regret in both the general and strongly convex settings. Finally, we complement our algorithms with lower bounds that match our upper bounds in some of the cases we consider.