 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning in MDPs with Partially Adversarial Transitions and Losses
Feb 10, 2026We study reinforcement learning in MDPs whose transition function is stochastic at most steps but may behave adversarially at a fixed subset of $Λ$ steps per episode. This model captures environments that are stable except at a few vulnerable points. We introduce \emph{conditioned occupancy measures}, which remain stable across episodes even with adversarial transitions, and use them to design two algorithms. The first handles arbitrary adversarial steps and achieves regret $\tilde{O}(H S^Λ\sqrt{K S A^{Λ+1}})$, where $K$ is the number of episodes, $S$ is the number of state, $A$ is the number of actions and $H$ is the episode's horizon. The second, assuming the adversarial steps are consecutive, improves the dependence on $S$ to $\tilde{O}(H\sqrt{K S^{3} A^{Λ+1}})$. We further give a $K^{2/3}$-regret reduction that removes the need to know which steps are the $Λ$ adversarial steps. We also characterize the regret of adversarial MDPs in the \emph{fully adversarial} setting ($Λ=H-1$) both for full-information and bandit feedback, and provide almost matching upper and lower bounds (slightly strengthen existing lower bounds, and clarify how different feedback structures affect the hardness of learning).
Improved Best-of-Both-Worlds Regret for Bandits with Delayed Feedback
May 30, 2025We study the multi-armed bandit problem with adversarially chosen delays in the Best-of-Both-Worlds (BoBW) framework, which aims to achieve near-optimal performance in both stochastic and adversarial environments. While prior work has made progress toward this goal, existing algorithms suffer from significant gaps to the known lower bounds, especially in the stochastic settings. Our main contribution is a new algorithm that, up to logarithmic factors, matches the known lower bounds in each setting individually. In the adversarial case, our algorithm achieves regret of $\widetilde{O}(\sqrt{KT} + \sqrt{D})$, which is optimal up to logarithmic terms, where $T$ is the number of rounds, $K$ is the number of arms, and $D$ is the cumulative delay. In the stochastic case, we provide a regret bound which scale as $\sum_{i:\Delta_i>0}\left(\log T/\Delta_i\right) + \frac{1}{K}\sum \Delta_i \sigma_{max}$, where $\Delta_i$ is the sub-optimality gap of arm $i$ and $\sigma_{\max}$ is the maximum number of missing observations. To the best of our knowledge, this is the first BoBW algorithm to simultaneously match the lower bounds in both stochastic and adversarial regimes in delayed environment. Moreover, even beyond the BoBW setting, our stochastic regret bound is the first to match the known lower bound under adversarial delays, improving the second term over the best known result by a factor of $K$.
Near-optimal Regret Using Policy Optimization in Online MDPs with Aggregate Bandit Feedback
Feb 06, 2025
We study online finite-horizon Markov Decision Processes with adversarially changing loss and aggregate bandit feedback (a.k.a full-bandit). Under this type of feedback, the agent observes only the total loss incurred over the entire trajectory, rather than the individual losses at each intermediate step within the trajectory. We introduce the first Policy Optimization algorithms for this setting. In the known-dynamics case, we achieve the first \textit{optimal} regret bound of $\tilde \Theta(H^2\sqrt{SAK})$, where $K$ is the number of episodes, $H$ is the episode horizon, $S$ is the number of states, and $A$ is the number of actions. In the unknown dynamics case we establish regret bound of $\tilde O(H^3 S \sqrt{AK})$, significantly improving the best known result by a factor of $H^2 S^5 A^2$.
Individual Regret in Cooperative Stochastic Multi-Armed Bandits
Nov 10, 2024
We study the regret in stochastic Multi-Armed Bandits (MAB) with multiple agents that communicate over an arbitrary connected communication graph. We show a near-optimal individual regret bound of $\tilde{O}(\sqrt{AT/m}+A)$, where $A$ is the number of actions, $T$ the time horizon, and $m$ the number of agents. In particular, assuming a sufficient number of agents, we achieve a regret bound of $\tilde{O}(A)$, which is independent of the sub-optimality gaps and the diameter of the communication graph. To the best of our knowledge, our study is the first to show an individual regret bound in cooperative stochastic MAB that is independent of the graph's diameter and applicable to non-fully-connected communication graphs.
Delay as Payoff in MAB
Aug 27, 2024

In this paper, we investigate a variant of the classical stochastic Multi-armed Bandit (MAB) problem, where the payoff received by an agent (either cost or reward) is both delayed, and directly corresponds to the magnitude of the delay. This setting models faithfully many real world scenarios such as the time it takes for a data packet to traverse a network given a choice of route (where delay serves as the agent's cost); or a user's time spent on a web page given a choice of content (where delay serves as the agent's reward). Our main contributions are tight upper and lower bounds for both the cost and reward settings. For the case that delays serve as costs, which we are the first to consider, we prove optimal regret that scales as $\sum_{i:\Delta_i > 0}\frac{\log T}{\Delta_i} + d^*$, where $T$ is the maximal number of steps, $\Delta_i$ are the sub-optimality gaps and $d^*$ is the minimal expected delay amongst arms. For the case that delays serves as rewards, we show optimal regret of $\sum_{i:\Delta_i > 0}\frac{\log T}{\Delta_i} + \bar{d}$, where $\bar d$ is the second maximal expected delay. These improve over the regret in the general delay-dependent payoff setting, which scales as $\sum_{i:\Delta_i > 0}\frac{\log T}{\Delta_i} + D$, where $D$ is the maximum possible delay. Our regret bounds highlight the difference between the cost and reward scenarios, showing that the improvement in the cost scenario is more significant than for the reward. Finally, we accompany our theoretical results with an empirical evaluation.
Towards Natural Language-Driven Assembly Using Foundation Models
Jun 23, 2024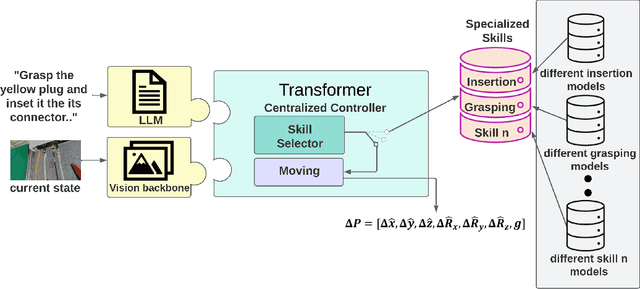
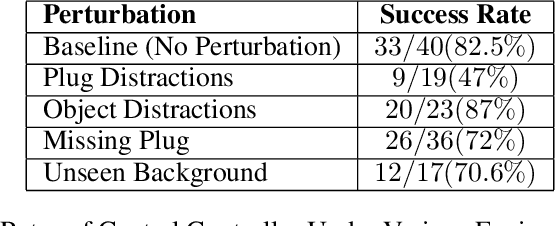
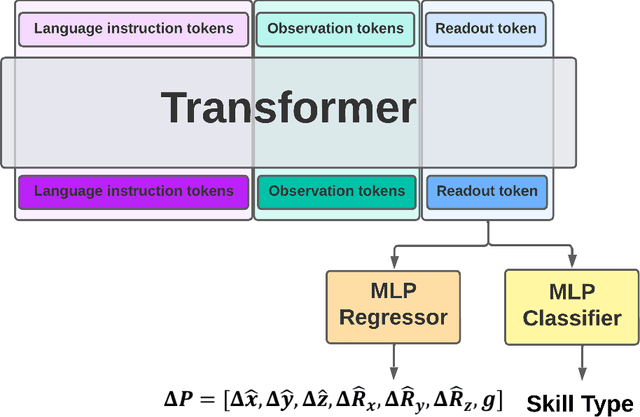

Large Language Models (LLMs) and strong vision models have enabled rapid research and development in the field of Vision-Language-Action models that enable robotic control. The main objective of these methods is to develop a generalist policy that can control robots with various embodiments. However, in industrial robotic applications such as automated assembly and disassembly, some tasks, such as insertion, demand greater accuracy and involve intricate factors like contact engagement, friction handling, and refined motor skills. Implementing these skills using a generalist policy is challenging because these policies might integrate further sensory data, including force or torque measurements, for enhanced precision. In our method, we present a global control policy based on LLMs that can transfer the control policy to a finite set of skills that are specifically trained to perform high-precision tasks through dynamic context switching. The integration of LLMs into this framework underscores their significance in not only interpreting and processing language inputs but also in enriching the control mechanisms for diverse and intricate robotic operations.
A Unified Analysis of Nonstochastic Delayed Feedback for Combinatorial Semi-Bandits, Linear Bandits, and MDPs
May 15, 2023We derive a new analysis of Follow The Regularized Leader (FTRL) for online learning with delayed bandit feedback. By separating the cost of delayed feedback from that of bandit feedback, our analysis allows us to obtain new results in three important settings. On the one hand, we derive the first optimal (up to logarithmic factors) regret bounds for combinatorial semi-bandits with delay and adversarial Markov decision processes with delay (and known transition functions). On the other hand, we use our analysis to derive an efficient algorithm for linear bandits with delay achieving near-optimal regret bounds. Our novel regret decomposition shows that FTRL remains stable across multiple rounds under mild assumptions on the Hessian of the regularizer.
Delay-Adapted Policy Optimization and Improved Regret for Adversarial MDP with Delayed Bandit Feedback
May 13, 2023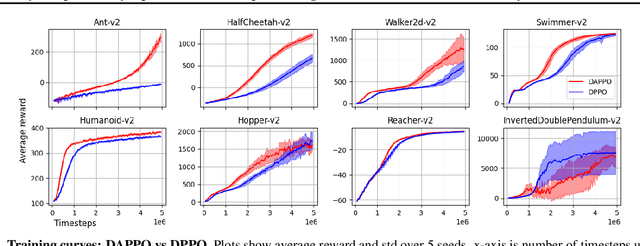
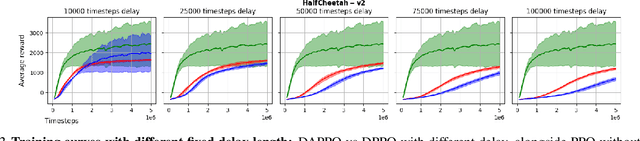

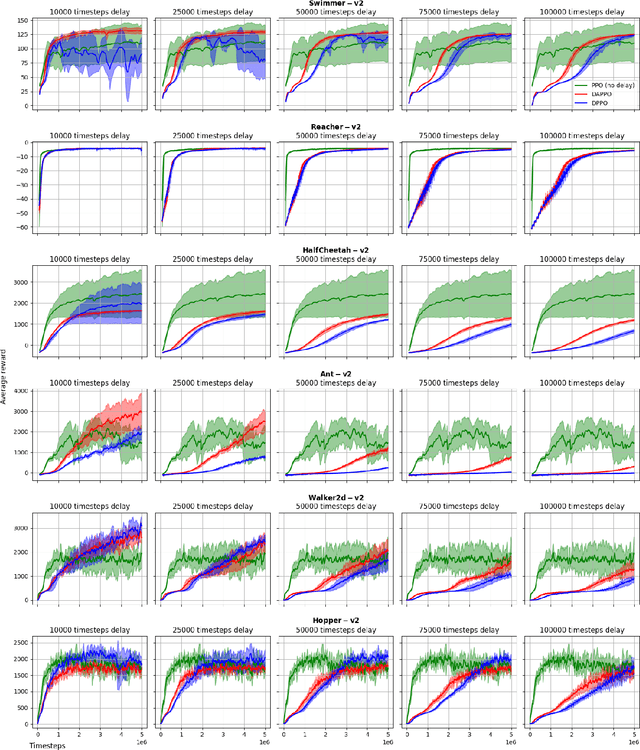
Policy Optimization (PO) is one of the most popular methods in Reinforcement Learning (RL). Thus, theoretical guarantees for PO algorithms have become especially important to the RL community. In this paper, we study PO in adversarial MDPs with a challenge that arises in almost every real-world application -- \textit{delayed bandit feedback}. We give the first near-optimal regret bounds for PO in tabular MDPs, and may even surpass state-of-the-art (which uses less efficient methods). Our novel Delay-Adapted PO (DAPO) is easy to implement and to generalize, allowing us to extend our algorithm to: (i) infinite state space under the assumption of linear $Q$-function, proving the first regret bounds for delayed feedback with function approximation. (ii) deep RL, demonstrating its effectiveness in experiments on MuJoCo domains.
Regret Minimization and Convergence to Equilibria in General-sum Markov Games
Aug 08, 2022

An abundance of recent impossibility results establish that regret minimization in Markov games with adversarial opponents is both statistically and computationally intractable. Nevertheless, none of these results preclude the possibility of regret minimization under the assumption that all parties adopt the same learning procedure. In this work, we present the first (to our knowledge) algorithm for learning in general-sum Markov games that provides sublinear regret guarantees when executed by all agents. The bounds we obtain are for swap regret, and thus, along the way, imply convergence to a correlated equilibrium. Our algorithm is decentralized, computationally efficient, and does not require any communication between agents. Our key observation is that online learning via policy optimization in Markov games essentially reduces to a form of weighted regret minimization, with unknown weights determined by the path length of the agents' policy sequence. Consequently, controlling the path length leads to weighted regret objectives for which sufficiently adaptive algorithms provide sublinear regret guarantees.
Near-Optimal Regret for Adversarial MDP with Delayed Bandit Feedback
Jan 31, 2022The standard assumption in reinforcement learning (RL) is that agents observe feedback for their actions immediately. However, in practice feedback is often observed in delay. This paper studies online learning in episodic Markov decision process (MDP) with unknown transitions, adversarially changing costs, and unrestricted delayed bandit feedback. More precisely, the feedback for the agent in episode $k$ is revealed only in the end of episode $k + d^k$, where the delay $d^k$ can be changing over episodes and chosen by an oblivious adversary. We present the first algorithms that achieve near-optimal $\sqrt{K + D}$ regret, where $K$ is the number of episodes and $D = \sum_{k=1}^K d^k$ is the total delay, significantly improving upon the best known regret bound of $(K + D)^{2/3}$.