 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Free Neural Network Training on the Edge
Oct 13, 2024



Training neural networks is computationally heavy and energy-intensive. Many methodologies were developed to save computational requirements and energy by reducing the precision of network weights at inference time and introducing techniques such as rounding, stochastic rounding, and quantization. However, most of these techniques still require full gradient precision at training time, which makes training such models prohibitive on edge devices. This work presents a novel technique for training neural networks without needing gradients. This enables a training process where all the weights are one or two bits, without any hidden full precision computations. We show that it is possible to train models without gradient-based optimization techniques by identifying erroneous contributions of each neuron towards the expected classification and flipping the relevant bits using logical operations. We tested our method on several standard datasets and achieved performance comparable to corresponding gradient-based baselines with a fraction of the compute power.
Towards Natural Language-Driven Assembly Using Foundation Models
Jun 23, 2024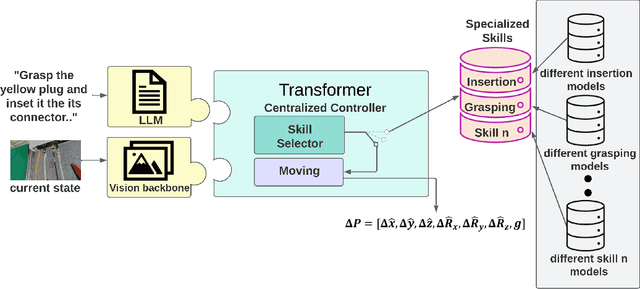
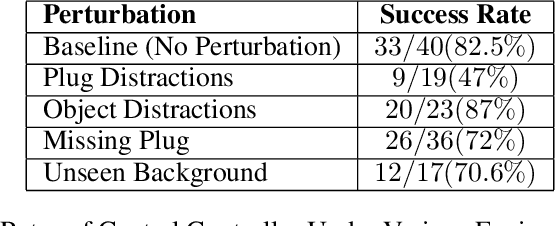
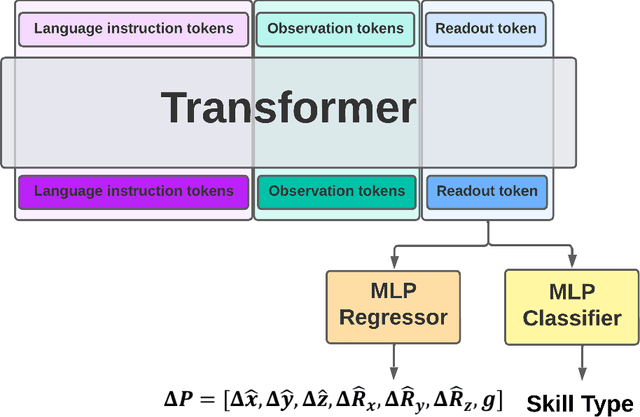

Large Language Models (LLMs) and strong vision models have enabled rapid research and development in the field of Vision-Language-Action models that enable robotic control. The main objective of these methods is to develop a generalist policy that can control robots with various embodiments. However, in industrial robotic applications such as automated assembly and disassembly, some tasks, such as insertion, demand greater accuracy and involve intricate factors like contact engagement, friction handling, and refined motor skills. Implementing these skills using a generalist policy is challenging because these policies might integrate further sensory data, including force or torque measurements, for enhanced precision. In our method, we present a global control policy based on LLMs that can transfer the control policy to a finite set of skills that are specifically trained to perform high-precision tasks through dynamic context switching. The integration of LLMs into this framework underscores their significance in not only interpreting and processing language inputs but also in enriching the control mechanisms for diverse and intricate robotic operations.
DUQIM-Net: Probabilistic Object Hierarchy Representation for Multi-View Manipulation
Jul 19, 2022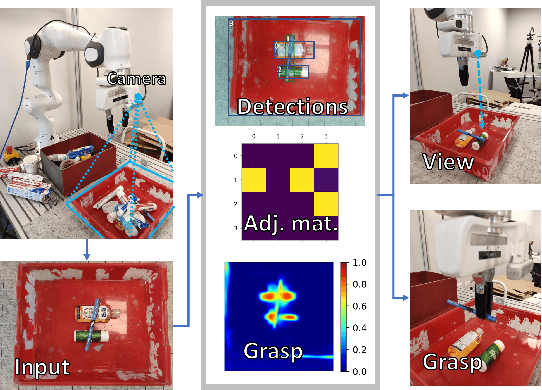
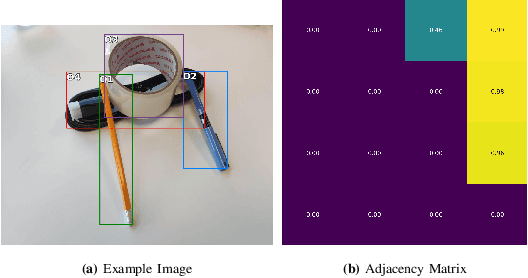
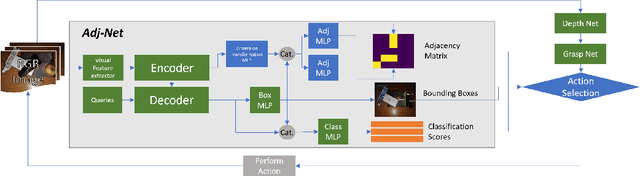
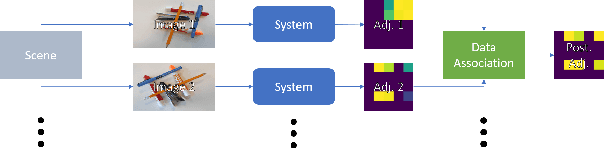
Object manipulation in cluttered scenes is a difficult and important problem in robotics. To efficiently manipulate objects, it is crucial to understand their surroundings, especially in cases where multiple objects are stacked one on top of the other, preventing effective grasping. We here present DUQIM-Net, a decision-making approach for object manipulation in a setting of stacked objects. In DUQIM-Net, the hierarchical stacking relationship is assessed using Adj-Net, a model that leverages existing Transformer Encoder-Decoder object detectors by adding an adjacency head. The output of this head probabilistically infers the underlying hierarchical structure of the objects in the scene. We utilize the properties of the adjacency matrix in DUQIM-Net to perform decision making and assist with object-grasping tasks. Our experimental results show that Adj-Net surpasses the state-of-the-art in object-relationship inference on the Visual Manipulation Relationship Dataset (VMRD), and that DUQIM-Net outperforms comparable approaches in bin clearing tasks.
InsertionNet 2.0: Minimal Contact Multi-Step Insertion Using Multimodal Multiview Sensory Input
Mar 02, 2022
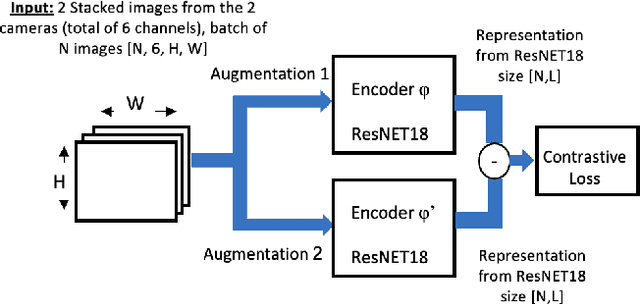
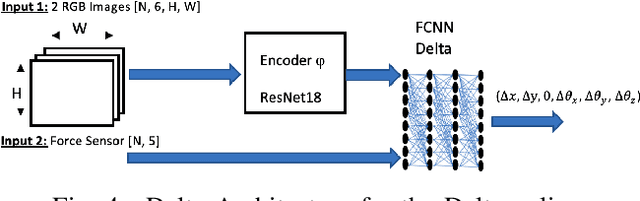

We address the problem of devising the means for a robot to rapidly and safely learn insertion skills with just a few human interventions and without hand-crafted rewards or demonstrations. Our InsertionNet version 2.0 provides an improved technique to robustly cope with a wide range of use-cases featuring different shapes, colors, initial poses, etc. In particular, we present a regression-based method based on multimodal input from stereo perception and force, augmented with contrastive learning for the efficient learning of valuable features. In addition, we introduce a one-shot learning technique for insertion, which relies on a relation network scheme to better exploit the collected data and to support multi-step insertion tasks. Our method improves on the results obtained with the original InsertionNet, achieving an almost perfect score (above 97.5$\%$ on 200 trials) in 16 real-life insertion tasks while minimizing the execution time and contact during insertion. We further demonstrate our method's ability to tackle a real-life 3-step insertion task and perfectly solve an unseen insertion task without learning.
Epistemic Uncertainty Aware Semantic Localization and Mapping for Inference and Belief Space Planning
May 26, 2021
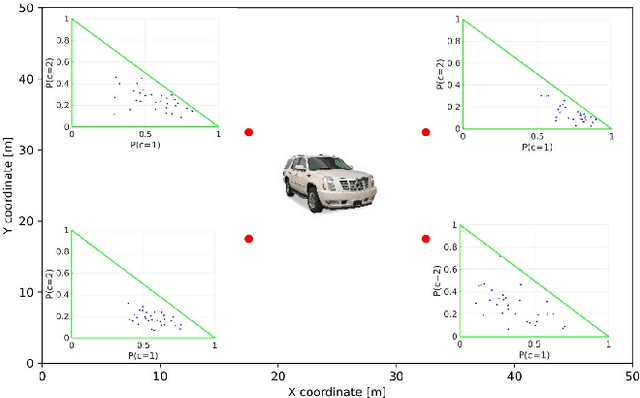
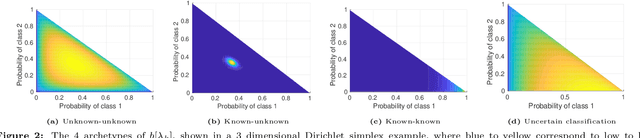
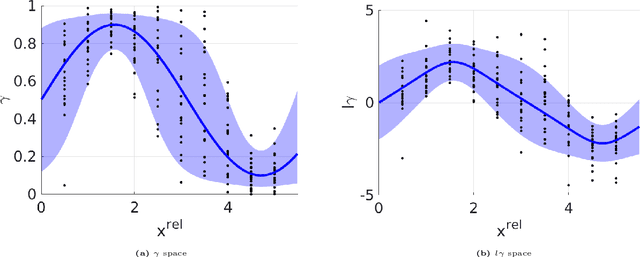
We investigate the problem of autonomous object classification and semantic SLAM, which in general exhibits a tight coupling between classification, metric SLAM and planning under uncertainty. We contribute a unified framework for inference and belief space planning (BSP) that addresses prominent sources of uncertainty in this context: classification aliasing (classier cannot distinguish between candidate classes from certain viewpoints), classifier epistemic uncertainty (classifier receives data "far" from its training set), and localization uncertainty (camera and object poses are uncertain). Specifically, we develop two methods for maintaining a joint distribution over robot and object poses, and over posterior class probability vector that considers epistemic uncertainty in a Bayesian fashion. The first approach is Multi-Hybrid (MH), where multiple hybrid beliefs over poses and classes are maintained to approximate the joint belief over poses and posterior class probability. The second approach is Joint Lambda Pose (JLP), where the joint belief is maintained directly using a novel JLP factor. Furthermore, we extend both methods to BSP, planning while reasoning about future posterior epistemic uncertainty indirectly, or directly via a novel information-theoretic reward function. Both inference methods utilize a novel viewpoint-dependent classifier uncertainty model that leverages the coupling between poses and classification scores and predicts the epistemic uncertainty from certain viewpoints. In addition, this model is used to generate predicted measurements during planning. To the best of our knowledge, this is the first work that reasons about classifier epistemic uncertainty within semantic SLAM and BSP.
Distributed Consistent Multi-Robot Semantic Localization and Mapping
Jul 06, 2020


We present an approach for multi-robot consistent distributed localization and semantic mapping in an unknown environment, considering scenarios with classification ambiguity, where objects' visual appearance generally varies with viewpoint. Our approach addresses such a setting by maintaining a distributed posterior hybrid belief over continuous localization and discrete classification variables. In particular, we utilize a viewpoint-dependent classifier model to leverage the coupling between semantics and geometry. Moreover, our approach yields a consistent estimation of both continuous and discrete variables, with the latter being addressed for the first time, to the best of our knowledge. We evaluate the performance of our approach in a multi-robot semantic SLAM simulation and in a real-world experiment, demonstrating an increase in both classification and localization accuracy compared to maintaining a hybrid belief using local information only.
* 28 pages, 73 figures, for an associated video, see https://youtu.be/jATog1snfwc