 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Data Scarcity: A Frequency-Driven Framework for Zero-Shot Forecasting
Nov 24, 2024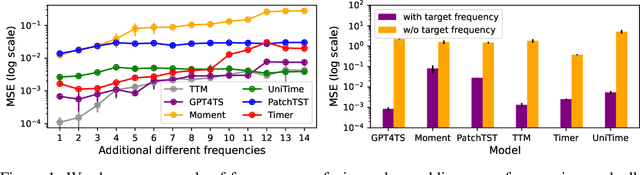
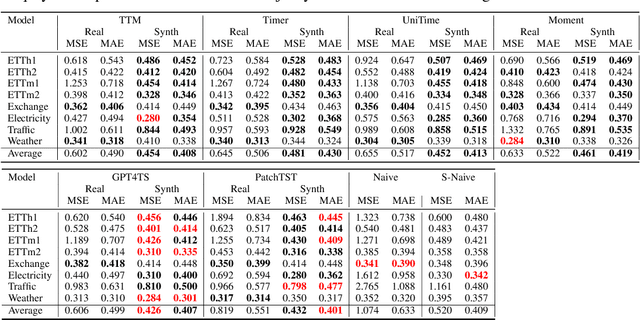
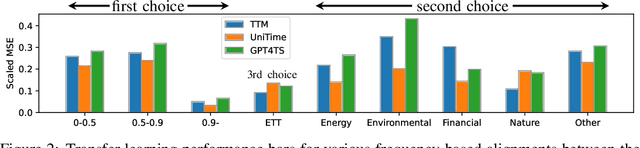
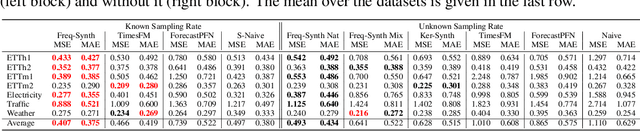
Time series forecasting is critical in numerous real-world applications, requiring accurate predictions of future values based on observed patterns. While traditional forecasting techniques work well in in-domain scenarios with ample data, they struggle when data is scarce or not available at all, motivating the emergence of zero-shot and few-shot learning settings. Recent advancements often leverage large-scale foundation models for such tasks, but these methods require extensive data and compute resources, and their performance may be hindered by ineffective learning from the available training set. This raises a fundamental question: What factors influence effective learning from data in time series forecasting? Toward addressing this, we propose using Fourier analysis to investigate how models learn from synthetic and real-world time series data. Our findings reveal that forecasters commonly suffer from poor learning from data with multiple frequencies and poor generalization to unseen frequencies, which impedes their predictive performance. To alleviate these issues, we present a novel synthetic data generation framework, designed to enhance real data or replace it completely by creating task-specific frequency information, requiring only the sampling rate of the target data. Our approach, Freq-Synth, improves the robustness of both foundation as well as nonfoundation forecast models in zero-shot and few-shot settings, facilitating more reliable time series forecasting under limited data scenarios.
Gradient-Free Neural Network Training on the Edge
Oct 13, 2024



Training neural networks is computationally heavy and energy-intensive. Many methodologies were developed to save computational requirements and energy by reducing the precision of network weights at inference time and introducing techniques such as rounding, stochastic rounding, and quantization. However, most of these techniques still require full gradient precision at training time, which makes training such models prohibitive on edge devices. This work presents a novel technique for training neural networks without needing gradients. This enables a training process where all the weights are one or two bits, without any hidden full precision computations. We show that it is possible to train models without gradient-based optimization techniques by identifying erroneous contributions of each neuron towards the expected classification and flipping the relevant bits using logical operations. We tested our method on several standard datasets and achieved performance comparable to corresponding gradient-based baselines with a fraction of the compute power.
An Axiomatic Approach to Model-Agnostic Concept Explanations
Jan 12, 2024Concept explanation is a popular approach for examining how human-interpretable concepts impact the predictions of a model. However, most existing methods for concept explanations are tailored to specific models. To address this issue, this paper focuses on model-agnostic measures. Specifically, we propose an approach to concept explanations that satisfy three natural axioms: linearity, recursivity, and similarity. We then establish connections with previous concept explanation methods, offering insight into their varying semantic meanings. Experimentally, we demonstrate the utility of the new method by applying it in different scenarios: for model selection, optimizer selection, and model improvement using a kind of prompt editing for zero-shot vision language models.
Principal-Agent Reward Shaping in MDPs
Dec 30, 2023Principal-agent problems arise when one party acts on behalf of another, leading to conflicts of interest. The economic literature has extensively studied principal-agent problems, and recent work has extended this to more complex scenarios such as Markov Decision Processes (MDPs). In this paper, we further explore this line of research by investigating how reward shaping under budget constraints can improve the principal's utility. We study a two-player Stackelberg game where the principal and the agent have different reward functions, and the agent chooses an MDP policy for both players. The principal offers an additional reward to the agent, and the agent picks their policy selfishly to maximize their reward, which is the sum of the original and the offered reward. Our results establish the NP-hardness of the problem and offer polynomial approximation algorithms for two classes of instances: Stochastic trees and deterministic decision processes with a finite horizon.
A Learning-Theoretic Framework for Certified Auditing of Machine Learning Models
Jun 09, 2022



Responsible use of machine learning requires that models be audited for undesirable properties. However, how to do principled auditing in a general setting has remained ill-understood. In this paper, we propose a formal learning-theoretic framework for auditing. We propose algorithms for auditing linear classifiers for feature sensitivity using label queries as well as different kinds of explanations, and provide performance guarantees. Our results illustrate that while counterfactual explanations can be extremely helpful for auditing, anchor explanations may not be as beneficial in the worst case.
There is no Accuracy-Interpretability Tradeoff in Reinforcement Learning for Mazes
Jun 09, 2022


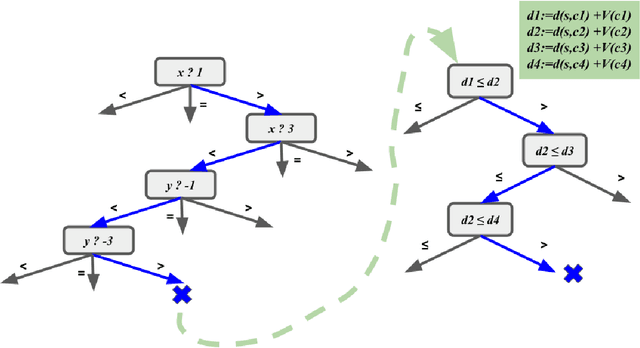
Interpretability is an essential building block for trustworthiness in reinforcement learning systems. However, interpretability might come at the cost of deteriorated performance, leading many researchers to build complex models. Our goal is to analyze the cost of interpretability. We show that in certain cases, one can achieve policy interpretability while maintaining its optimality. We focus on a classical problem from reinforcement learning: mazes with $k$ obstacles in $\mathbb{R}^d$. We prove the existence of a small decision tree with a linear function at each inner node and depth $O(\log k + 2^d)$ that represents an optimal policy. Note that for the interesting case of a constant $d$, we have $O(\log k)$ depth. Thus, in this setting, there is no accuracy-interpretability tradeoff. To prove this result, we use a new "compressing" technique that might be useful in additional settings.
Finding Safe Zones of policies Markov Decision Processes
Feb 23, 2022
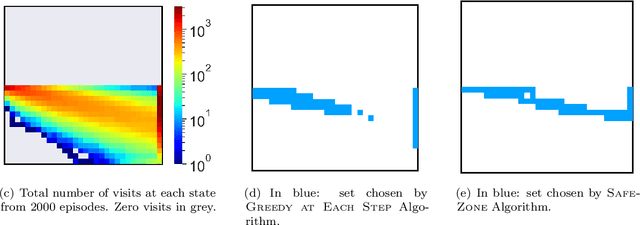
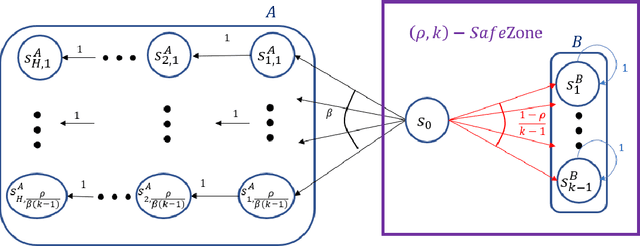
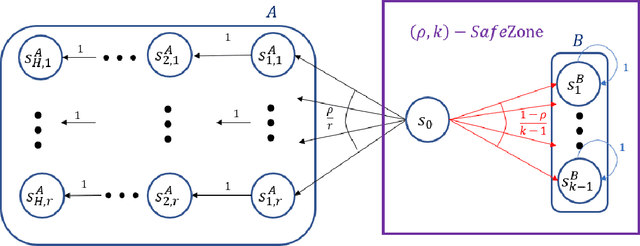
Given a policy, we define a SafeZone as a subset of states, such that most of the policy's trajectories are confined to this subset. The quality of the SafeZone is parameterized by the number of states and the escape probability, i.e., the probability that a random trajectory will leave the subset. SafeZones are especially interesting when they have a small number of states and low escape probability. We study the complexity of finding optimal SafeZones, and show that in general the problem is computationally hard. For this reason we concentrate on computing approximate SafeZones. Our main result is a bi-criteria approximation algorithm which gives a factor of almost $2$ approximation for both the escape probability and SafeZone size, using a polynomial size sample complexity. We conclude the paper with an empirical evaluation of our algorithm.
Framework for Evaluating Faithfulness of Local Explanations
Feb 01, 2022
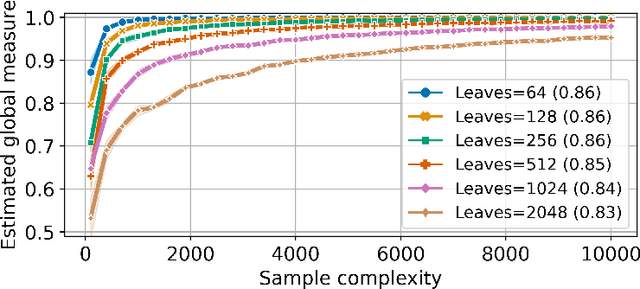
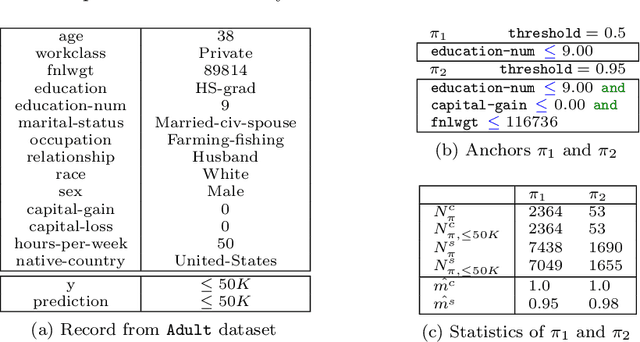
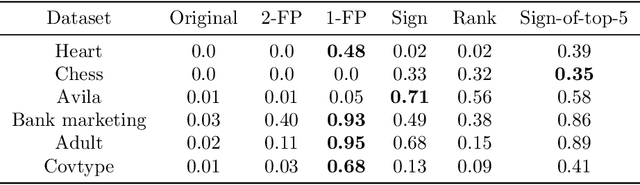
We study the faithfulness of an explanation system to the underlying prediction model. We show that this can be captured by two properties, consistency and sufficiency, and introduce quantitative measures of the extent to which these hold. Interestingly, these measures depend on the test-time data distribution. For a variety of existing explanation systems, such as anchors, we analytically study these quantities. We also provide estimators and sample complexity bounds for empirically determining the faithfulness of black-box explanation systems. Finally, we experimentally validate the new properties and estimators.
Connecting Interpretability and Robustness in Decision Trees through Separation
Feb 14, 2021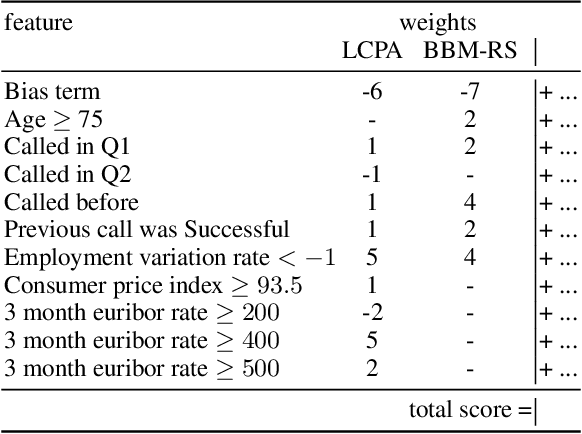
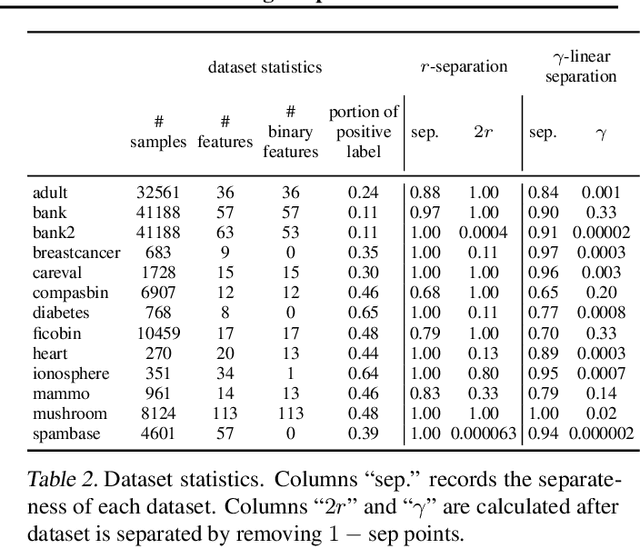
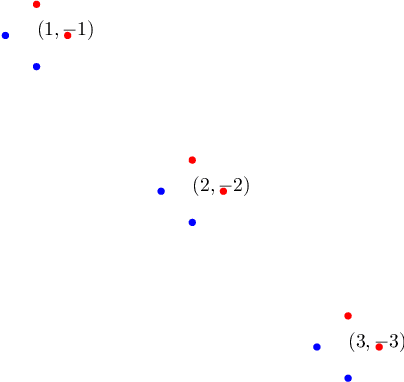
Recent research has recognized interpretability and robustness as essential properties of trustworthy classification. Curiously, a connection between robustness and interpretability was empirically observed, but the theoretical reasoning behind it remained elusive. In this paper, we rigorously investigate this connection. Specifically, we focus on interpretation using decision trees and robustness to $l_{\infty}$-perturbation. Previous works defined the notion of $r$-separation as a sufficient condition for robustness. We prove upper and lower bounds on the tree size in case the data is $r$-separated. We then show that a tighter bound on the size is possible when the data is linearly separated. We provide the first algorithm with provable guarantees both on robustness, interpretability, and accuracy in the context of decision trees. Experiments confirm that our algorithm yields classifiers that are both interpretable and robust and have high accuracy. The code for the experiments is available at https://github.com/yangarbiter/interpretable-robust-trees .
Bounded Memory Active Learning through Enriched Queries
Feb 09, 2021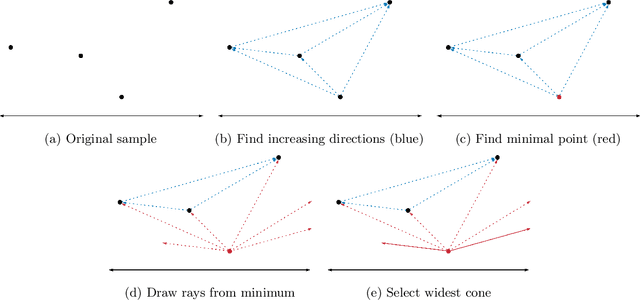
The explosive growth of easily-accessible unlabeled data has lead to growing interest in active learning, a paradigm in which data-hungry learning algorithms adaptively select informative examples in order to lower prohibitively expensive labeling costs. Unfortunately, in standard worst-case models of learning, the active setting often provides no improvement over non-adaptive algorithms. To combat this, a series of recent works have considered a model in which the learner may ask enriched queries beyond labels. While such models have seen success in drastically lowering label costs, they tend to come at the expense of requiring large amounts of memory. In this work, we study what families of classifiers can be learned in bounded memory. To this end, we introduce a novel streaming-variant of enriched-query active learning along with a natural combinatorial parameter called lossless sample compression that is sufficient for learning not only with bounded memory, but in a query-optimal and computationally efficient manner as well. Finally, we give three fundamental examples of classifier families with small, easy to compute lossless compression schemes when given access to basic enriched queries: axis-aligned rectangles, decision trees, and halfspaces in two dimensions.