 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper-Linear: A Lightweight Pretrained Mixture of Linear Experts for Time Series Forecasting
Sep 18, 2025Time series forecasting (TSF) is critical in domains like energy, finance, healthcare, and logistics, requiring models that generalize across diverse datasets. Large pre-trained models such as Chronos and Time-MoE show strong zero-shot (ZS) performance but suffer from high computational costs. In this work, We introduce Super-Linear, a lightweight and scalable mixture-of-experts (MoE) model for general forecasting. It replaces deep architectures with simple frequency-specialized linear experts, trained on resampled data across multiple frequency regimes. A lightweight spectral gating mechanism dynamically selects relevant experts, enabling efficient, accurate forecasting. Despite its simplicity, Super-Linear matches state-of-the-art performance while offering superior efficiency, robustness to various sampling rates, and enhanced interpretability. The implementation of Super-Linear is available at \href{https://github.com/azencot-group/SuperLinear}{https://github.com/azencot-group/SuperLinear}
A Multi-Task Learning Approach to Linear Multivariate Forecasting
Feb 05, 2025



Accurate forecasting of multivariate time series data is important in many engineering and scientific applications. Recent state-of-the-art works ignore the inter-relations between variates, using their model on each variate independently. This raises several research questions related to proper modeling of multivariate data. In this work, we propose to view multivariate forecasting as a multi-task learning problem, facilitating the analysis of forecasting by considering the angle between task gradients and their balance. To do so, we analyze linear models to characterize the behavior of tasks. Our analysis suggests that tasks can be defined by grouping similar variates together, which we achieve via a simple clustering that depends on correlation-based similarities. Moreover, to balance tasks, we scale gradients with respect to their prediction error. Then, each task is solved with a linear model within our MTLinear framework. We evaluate our approach on challenging benchmarks in comparison to strong baselines, and we show it obtains on-par or better results on multivariate forecasting problems. The implementation is available at: https://github.com/azencot-group/MTLinear
Beyond Data Scarcity: A Frequency-Driven Framework for Zero-Shot Forecasting
Nov 24, 2024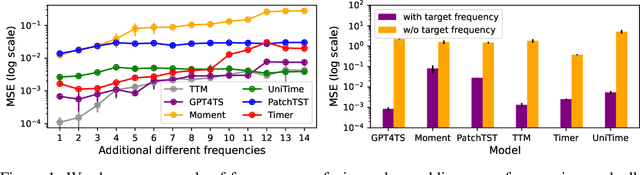
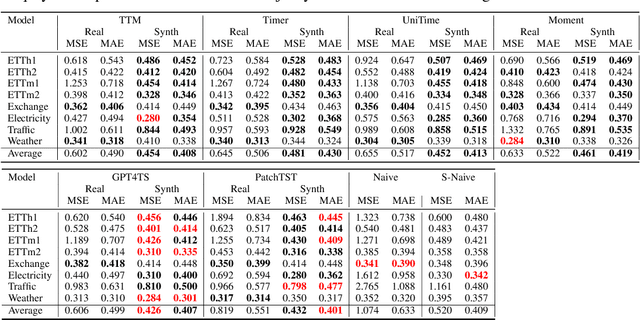
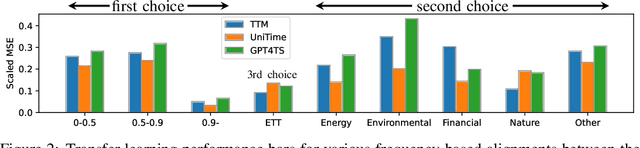
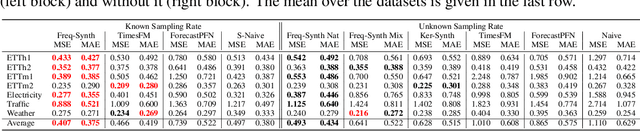
Time series forecasting is critical in numerous real-world applications, requiring accurate predictions of future values based on observed patterns. While traditional forecasting techniques work well in in-domain scenarios with ample data, they struggle when data is scarce or not available at all, motivating the emergence of zero-shot and few-shot learning settings. Recent advancements often leverage large-scale foundation models for such tasks, but these methods require extensive data and compute resources, and their performance may be hindered by ineffective learning from the available training set. This raises a fundamental question: What factors influence effective learning from data in time series forecasting? Toward addressing this, we propose using Fourier analysis to investigate how models learn from synthetic and real-world time series data. Our findings reveal that forecasters commonly suffer from poor learning from data with multiple frequencies and poor generalization to unseen frequencies, which impedes their predictive performance. To alleviate these issues, we present a novel synthetic data generation framework, designed to enhance real data or replace it completely by creating task-specific frequency information, requiring only the sampling rate of the target data. Our approach, Freq-Synth, improves the robustness of both foundation as well as nonfoundation forecast models in zero-shot and few-shot settings, facilitating more reliable time series forecasting under limited data scenarios.
Data Augmentation Policy Search for Long-Term Forecasting
May 01, 2024Data augmentation serves as a popular regularization technique to combat overfitting challenges in neural networks. While automatic augmentation has demonstrated success in image classification tasks, its application to time-series problems, particularly in long-term forecasting, has received comparatively less attention. To address this gap, we introduce a time-series automatic augmentation approach named TSAA, which is both efficient and easy to implement. The solution involves tackling the associated bilevel optimization problem through a two-step process: initially training a non-augmented model for a limited number of epochs, followed by an iterative split procedure. During this iterative process, we alternate between identifying a robust augmentation policy through Bayesian optimization and refining the model while discarding suboptimal runs. Extensive evaluations on challenging univariate and multivariate forecasting benchmark problems demonstrate that TSAA consistently outperforms several robust baselines, suggesting its potential integration into prediction pipelines.