 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLM-Guided Experience Replay
Feb 02, 2026Recent advances in Large Language Models (LLMs) and Vision-Language Models (VLMs) have enabled powerful semantic and multimodal reasoning capabilities, creating new opportunities to enhance sample efficiency, high-level planning, and interpretability in reinforcement learning (RL). While prior work has integrated LLMs and VLMs into various components of RL, the replay buffer, a core component for storing and reusing experiences, remains unexplored. We propose addressing this gap by leveraging VLMs to guide the prioritization of experiences in the replay buffer. Our key idea is to use a frozen, pre-trained VLM (requiring no fine-tuning) as an automated evaluator to identify and prioritize promising sub-trajectories from the agent's experiences. Across scenarios, including game-playing and robotics, spanning both discrete and continuous domains, agents trained with our proposed prioritization method achieve 11-52% higher average success rates and improve sample efficiency by 19-45% compared to previous approaches. https://esharony.me/projects/vlm-rb/
PREGEN: Uncovering Latent Thoughts in Composed Video Retrieval
Jan 20, 2026Composed Video Retrieval (CoVR) aims to retrieve a video based on a query video and a modifying text. Current CoVR methods fail to fully exploit modern Vision-Language Models (VLMs), either using outdated architectures or requiring computationally expensive fine-tuning and slow caption generation. We introduce PREGEN (PRE GENeration extraction), an efficient and powerful CoVR framework that overcomes these limitations. Our approach uniquely pairs a frozen, pre-trained VLM with a lightweight encoding model, eliminating the need for any VLM fine-tuning. We feed the query video and modifying text into the VLM and extract the hidden state of the final token from each layer. A simple encoder is then trained on these pooled representations, creating a semantically rich and compact embedding for retrieval. PREGEN significantly advances the state of the art, surpassing all prior methods on standard CoVR benchmarks with substantial gains in Recall@1 of +27.23 and +69.59. Our method demonstrates robustness across different VLM backbones and exhibits strong zero-shot generalization to more complex textual modifications, highlighting its effectiveness and semantic capabilities.
Towards General Modality Translation with Contrastive and Predictive Latent Diffusion Bridge
Oct 23, 2025

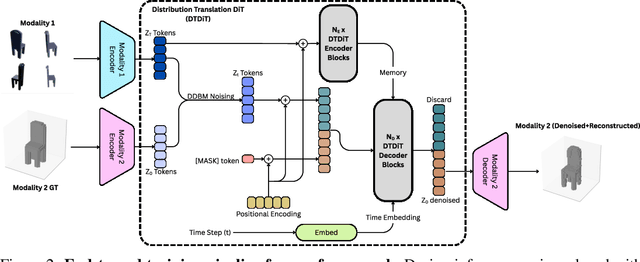

Recent advances in generative modeling have positioned diffusion models as state-of-the-art tools for sampling from complex data distributions. While these models have shown remarkable success across single-modality domains such as images and audio, extending their capabilities to Modality Translation (MT), translating information across different sensory modalities, remains an open challenge. Existing approaches often rely on restrictive assumptions, including shared dimensionality, Gaussian source priors, and modality-specific architectures, which limit their generality and theoretical grounding. In this work, we propose the Latent Denoising Diffusion Bridge Model (LDDBM), a general-purpose framework for modality translation based on a latent-variable extension of Denoising Diffusion Bridge Models. By operating in a shared latent space, our method learns a bridge between arbitrary modalities without requiring aligned dimensions. We introduce a contrastive alignment loss to enforce semantic consistency between paired samples and design a domain-agnostic encoder-decoder architecture tailored for noise prediction in latent space. Additionally, we propose a predictive loss to guide training toward accurate cross-domain translation and explore several training strategies to improve stability. Our approach supports arbitrary modality pairs and performs strongly on diverse MT tasks, including multi-view to 3D shape generation, image super-resolution, and multi-view scene synthesis. Comprehensive experiments and ablations validate the effectiveness of our framework, establishing a new strong baseline in general modality translation. For more information, see our project page: https://sites.google.com/view/lddbm/home.
Beyond Data Scarcity: A Frequency-Driven Framework for Zero-Shot Forecasting
Nov 24, 2024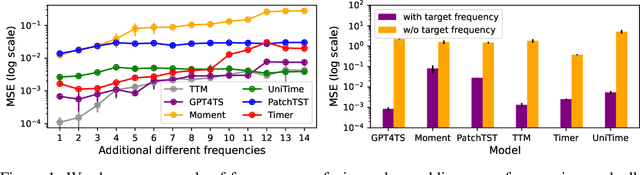
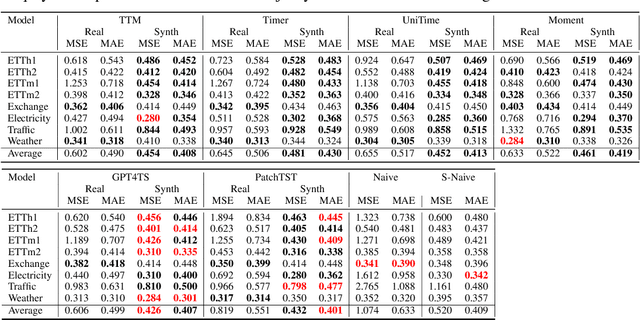
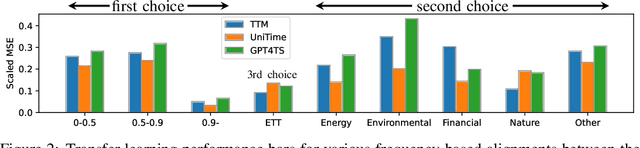
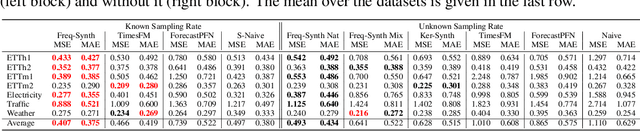
Time series forecasting is critical in numerous real-world applications, requiring accurate predictions of future values based on observed patterns. While traditional forecasting techniques work well in in-domain scenarios with ample data, they struggle when data is scarce or not available at all, motivating the emergence of zero-shot and few-shot learning settings. Recent advancements often leverage large-scale foundation models for such tasks, but these methods require extensive data and compute resources, and their performance may be hindered by ineffective learning from the available training set. This raises a fundamental question: What factors influence effective learning from data in time series forecasting? Toward addressing this, we propose using Fourier analysis to investigate how models learn from synthetic and real-world time series data. Our findings reveal that forecasters commonly suffer from poor learning from data with multiple frequencies and poor generalization to unseen frequencies, which impedes their predictive performance. To alleviate these issues, we present a novel synthetic data generation framework, designed to enhance real data or replace it completely by creating task-specific frequency information, requiring only the sampling rate of the target data. Our approach, Freq-Synth, improves the robustness of both foundation as well as nonfoundation forecast models in zero-shot and few-shot settings, facilitating more reliable time series forecasting under limited data scenarios.
Gradient-Free Neural Network Training on the Edge
Oct 13, 2024



Training neural networks is computationally heavy and energy-intensive. Many methodologies were developed to save computational requirements and energy by reducing the precision of network weights at inference time and introducing techniques such as rounding, stochastic rounding, and quantization. However, most of these techniques still require full gradient precision at training time, which makes training such models prohibitive on edge devices. This work presents a novel technique for training neural networks without needing gradients. This enables a training process where all the weights are one or two bits, without any hidden full precision computations. We show that it is possible to train models without gradient-based optimization techniques by identifying erroneous contributions of each neuron towards the expected classification and flipping the relevant bits using logical operations. We tested our method on several standard datasets and achieved performance comparable to corresponding gradient-based baselines with a fraction of the compute power.
Decentralized and Asymmetric Multi-Agent Learning in Construction Sites
Sep 16, 2024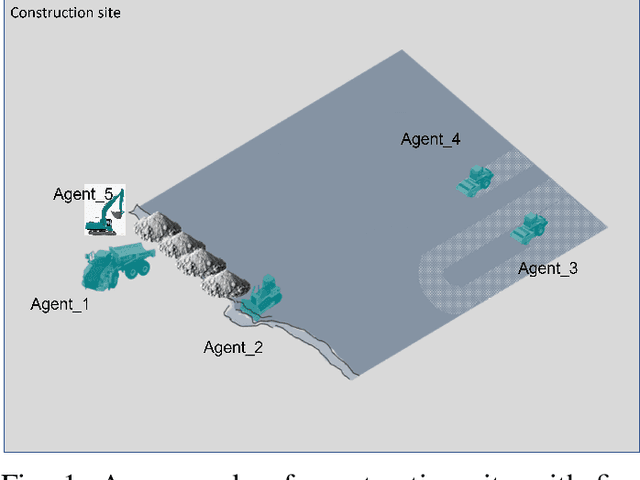
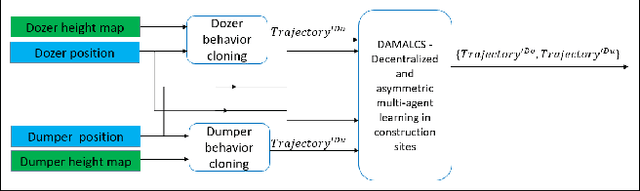
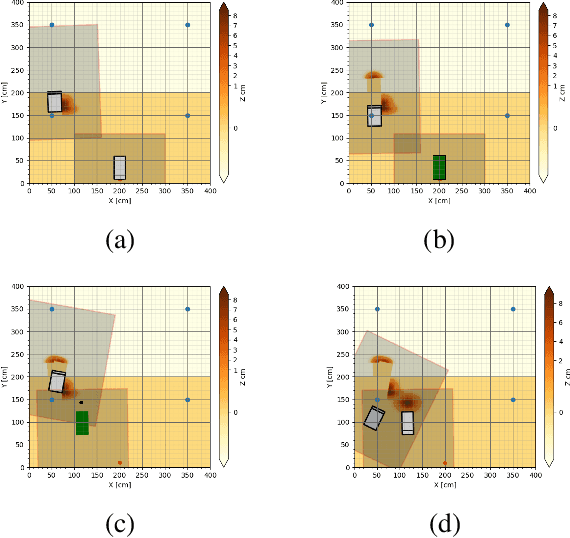
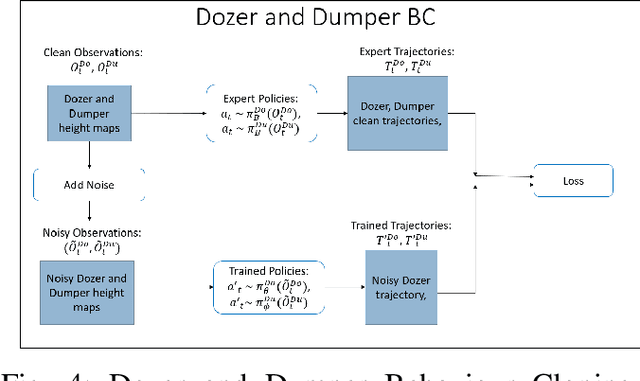
Multi-agent collaboration involves multiple participants working together in a shared environment to achieve a common goal. These agents share information, divide tasks, and synchronize their actions. Key aspects of multi agent collaboration include coordination, communication, task allocation, cooperation, adaptation, and decentralization. On construction sites, surface grading is the process of leveling sand piles to increase a specific area's height. In this scenario, a bulldozer grades while a dumper allocates sand piles. Our work aims to utilize a multi-agent approach to enable these vehicles to collaborate effectively. To this end, we propose a decentralized and asymmetric multi-agent learning approach for construction sites (DAMALCS). We formulate DAMALCS to reduce expected collisions for operating vehicles. Therefore, we develop two heuristic experts capable of achieving their joint goal optimally by applying an innovative prioritization method. In this approach, the bulldozer's movements take precedence over the dumper's operations, enabling the bulldozer to clear the path for the dumper and ensure continuous operation of both vehicles. Since heuristics alone are insufficient in real-world scenarios, we utilize them to train AI agents, which proves to be highly effective. We simultaneously train the bulldozer and dumper agents to operate within the same environment, aiming to avoid collisions and optimize performance in terms of time efficiency and sand volume handling. Our trained agents and heuristics are evaluated in both simulation and real-world lab experiments, testing them under various conditions, such as visual noise and localization errors. The results demonstrate that our approach significantly reduces collision rates for these vehicles.
Robot Instance Segmentation with Few Annotations for Grasping
Jul 01, 2024The ability of robots to manipulate objects relies heavily on their aptitude for visual perception. In domains characterized by cluttered scenes and high object variability, most methods call for vast labeled datasets, laboriously hand-annotated, with the aim of training capable models. Once deployed, the challenge of generalizing to unfamiliar objects implies that the model must evolve alongside its domain. To address this, we propose a novel framework that combines Semi-Supervised Learning (SSL) with Learning Through Interaction (LTI), allowing a model to learn by observing scene alterations and leverage visual consistency despite temporal gaps without requiring curated data of interaction sequences. As a result, our approach exploits partially annotated data through self-supervision and incorporates temporal context using pseudo-sequences generated from unlabeled still images. We validate our method on two common benchmarks, ARMBench mix-object-tote and OCID, where it achieves state-of-the-art performance. Notably, on ARMBench, we attain an $\text{AP}_{50}$ of $86.37$, almost a $20\%$ improvement over existing work, and obtain remarkable results in scenarios with extremely low annotation, achieving an $\text{AP}_{50}$ score of $84.89$ with just $1 \%$ of annotated data compared to $72$ presented in ARMBench on the fully annotated counterpart.
Towards Natural Language-Driven Assembly Using Foundation Models
Jun 23, 2024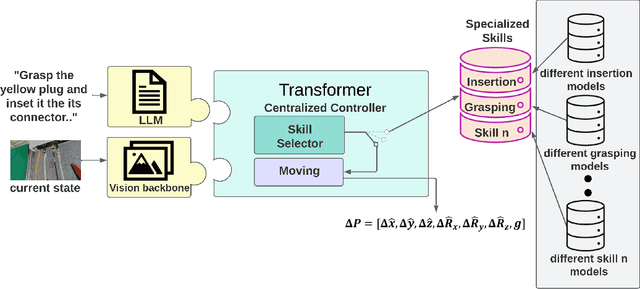
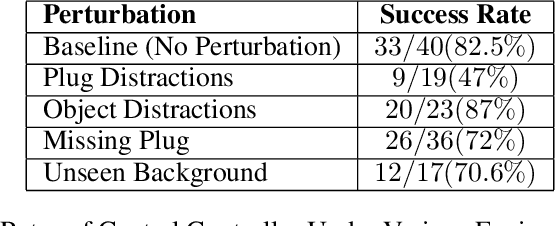
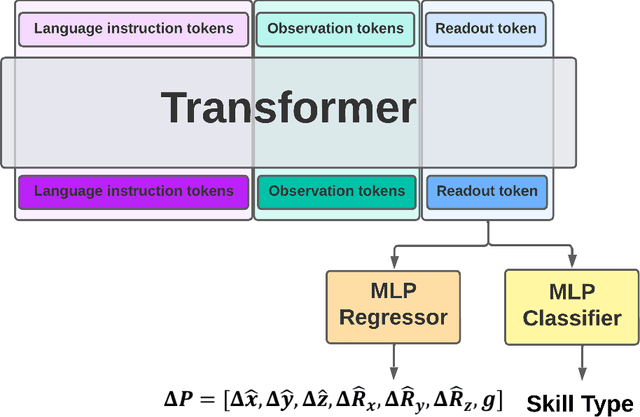

Large Language Models (LLMs) and strong vision models have enabled rapid research and development in the field of Vision-Language-Action models that enable robotic control. The main objective of these methods is to develop a generalist policy that can control robots with various embodiments. However, in industrial robotic applications such as automated assembly and disassembly, some tasks, such as insertion, demand greater accuracy and involve intricate factors like contact engagement, friction handling, and refined motor skills. Implementing these skills using a generalist policy is challenging because these policies might integrate further sensory data, including force or torque measurements, for enhanced precision. In our method, we present a global control policy based on LLMs that can transfer the control policy to a finite set of skills that are specifically trained to perform high-precision tasks through dynamic context switching. The integration of LLMs into this framework underscores their significance in not only interpreting and processing language inputs but also in enriching the control mechanisms for diverse and intricate robotic operations.
Radar Spectra-Language Model for Automotive Scene Parsing
Jun 04, 2024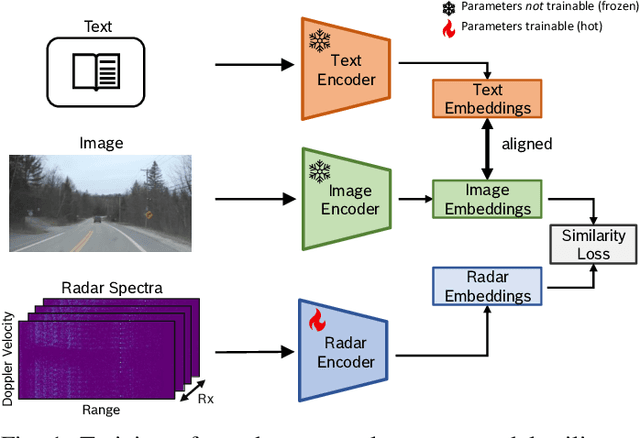



Radar sensors are low cost, long-range, and weather-resilient. Therefore, they are widely used for driver assistance functions, and are expected to be crucial for the success of autonomous driving in the future. In many perception tasks only pre-processed radar point clouds are considered. In contrast, radar spectra are a raw form of radar measurements and contain more information than radar point clouds. However, radar spectra are rather difficult to interpret. In this work, we aim to explore the semantic information contained in spectra in the context of automated driving, thereby moving towards better interpretability of radar spectra. To this end, we create a radar spectra-language model, allowing us to query radar spectra measurements for the presence of scene elements using free text. We overcome the scarcity of radar spectra data by matching the embedding space of an existing vision-language model (VLM). Finally, we explore the benefit of the learned representation for scene parsing, and obtain improvements in free space segmentation and object detection merely by injecting the spectra embedding into a baseline model.
ISCUTE: Instance Segmentation of Cables Using Text Embedding
Feb 27, 2024In the field of robotics and automation, conventional object recognition and instance segmentation methods face a formidable challenge when it comes to perceiving Deformable Linear Objects (DLOs) like wires, cables, and flexible tubes. This challenge arises primarily from the lack of distinct attributes such as shape, color, and texture, which calls for tailored solutions to achieve precise identification. In this work, we propose a foundation model-based DLO instance segmentation technique that is text-promptable and user-friendly. Specifically, our approach combines the text-conditioned semantic segmentation capabilities of CLIPSeg model with the zero-shot generalization capabilities of Segment Anything Model (SAM). We show that our method exceeds SOTA performance on DLO instance segmentation, achieving a mIoU of $91.21\%$. We also introduce a rich and diverse DLO-specific dataset for instance segmentation.