 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards General Modality Translation with Contrastive and Predictive Latent Diffusion Bridge
Oct 23, 2025

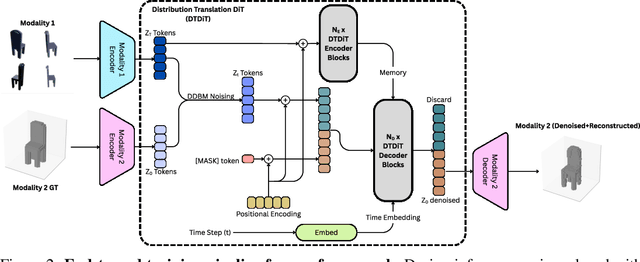

Recent advances in generative modeling have positioned diffusion models as state-of-the-art tools for sampling from complex data distributions. While these models have shown remarkable success across single-modality domains such as images and audio, extending their capabilities to Modality Translation (MT), translating information across different sensory modalities, remains an open challenge. Existing approaches often rely on restrictive assumptions, including shared dimensionality, Gaussian source priors, and modality-specific architectures, which limit their generality and theoretical grounding. In this work, we propose the Latent Denoising Diffusion Bridge Model (LDDBM), a general-purpose framework for modality translation based on a latent-variable extension of Denoising Diffusion Bridge Models. By operating in a shared latent space, our method learns a bridge between arbitrary modalities without requiring aligned dimensions. We introduce a contrastive alignment loss to enforce semantic consistency between paired samples and design a domain-agnostic encoder-decoder architecture tailored for noise prediction in latent space. Additionally, we propose a predictive loss to guide training toward accurate cross-domain translation and explore several training strategies to improve stability. Our approach supports arbitrary modality pairs and performs strongly on diverse MT tasks, including multi-view to 3D shape generation, image super-resolution, and multi-view scene synthesis. Comprehensive experiments and ablations validate the effectiveness of our framework, establishing a new strong baseline in general modality translation. For more information, see our project page: https://sites.google.com/view/lddbm/home.
Entropy-Based Uncertainty Modeling for Trajectory Prediction in Autonomous Driving
Oct 02, 2024



In autonomous driving, accurate motion prediction is essential for safe and efficient motion planning. To ensure safety, planners must rely on reliable uncertainty information about the predicted future behavior of surrounding agents, yet this aspect has received limited attention. This paper addresses the so-far neglected problem of uncertainty modeling in trajectory prediction. We adopt a holistic approach that focuses on uncertainty quantification, decomposition, and the influence of model composition. Our method is based on a theoretically grounded information-theoretic approach to measure uncertainty, allowing us to decompose total uncertainty into its aleatoric and epistemic components. We conduct extensive experiments on the nuScenes dataset to assess how different model architectures and configurations affect uncertainty quantification and model robustness.
Motion Forecasting via Model-Based Risk Minimization
Sep 16, 2024Forecasting the future trajectories of surrounding agents is crucial for autonomous vehicles to ensure safe, efficient, and comfortable route planning. While model ensembling has improved prediction accuracy in various fields, its application in trajectory prediction is limited due to the multi-modal nature of predictions. In this paper, we propose a novel sampling method applicable to trajectory prediction based on the predictions of multiple models. We first show that conventional sampling based on predicted probabilities can degrade performance due to missing alignment between models. To address this problem, we introduce a new method that generates optimal trajectories from a set of neural networks, framing it as a risk minimization problem with a variable loss function. By using state-of-the-art models as base learners, our approach constructs diverse and effective ensembles for optimal trajectory sampling. Extensive experiments on the nuScenes prediction dataset demonstrate that our method surpasses current state-of-the-art techniques, achieving top ranks on the leaderboard. We also provide a comprehensive empirical study on ensembling strategies, offering insights into their effectiveness. Our findings highlight the potential of advanced ensembling techniques in trajectory prediction, significantly improving predictive performance and paving the way for more reliable predicted trajectories.
Generative Modeling of Graphs via Joint Diffusion of Node and Edge Attributes
Feb 06, 2024Graph generation is integral to various engineering and scientific disciplines. Nevertheless, existing methodologies tend to overlook the generation of edge attributes. However, we identify critical applications where edge attributes are essential, making prior methods potentially unsuitable in such contexts. Moreover, while trivial adaptations are available, empirical investigations reveal their limited efficacy as they do not properly model the interplay among graph components. To address this, we propose a joint score-based model of nodes and edges for graph generation that considers all graph components. Our approach offers two key novelties: (i) node and edge attributes are combined in an attention module that generates samples based on the two ingredients; and (ii) node, edge and adjacency information are mutually dependent during the graph diffusion process. We evaluate our method on challenging benchmarks involving real-world and synthetic datasets in which edge features are crucial. Additionally, we introduce a new synthetic dataset that incorporates edge values. Furthermore, we propose a novel application that greatly benefits from the method due to its nature: the generation of traffic scenes represented as graphs. Our method outperforms other graph generation methods, demonstrating a significant advantage in edge-related measures.
Can you text what is happening? Integrating pre-trained language encoders into trajectory prediction models for autonomous driving
Sep 13, 2023In autonomous driving tasks, scene understanding is the first step towards predicting the future behavior of the surrounding traffic participants. Yet, how to represent a given scene and extract its features are still open research questions. In this study, we propose a novel text-based representation of traffic scenes and process it with a pre-trained language encoder. First, we show that text-based representations, combined with classical rasterized image representations, lead to descriptive scene embeddings. Second, we benchmark our predictions on the nuScenes dataset and show significant improvements compared to baselines. Third, we show in an ablation study that a joint encoder of text and rasterized images outperforms the individual encoders confirming that both representations have their complementary strengths.
GraphVid: It Only Takes a Few Nodes to Understand a Video
Jul 04, 2022
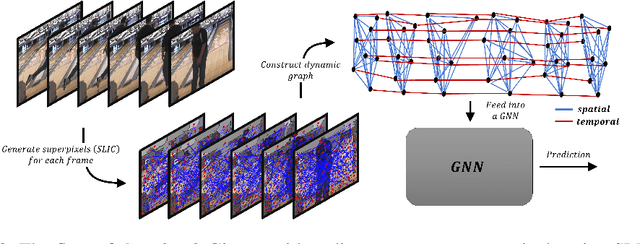
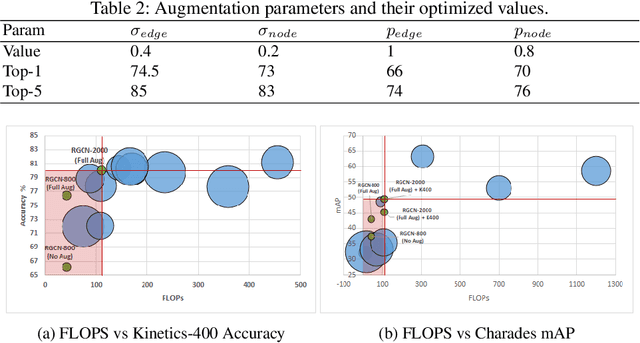
We propose a concise representation of videos that encode perceptually meaningful features into graphs. With this representation, we aim to leverage the large amount of redundancies in videos and save computations. First, we construct superpixel-based graph representations of videos by considering superpixels as graph nodes and create spatial and temporal connections between adjacent superpixels. Then, we leverage Graph Convolutional Networks to process this representation and predict the desired output. As a result, we are able to train models with much fewer parameters, which translates into short training periods and a reduction in computation resource requirements. A comprehensive experimental study on the publicly available datasets Kinetics-400 and Charades shows that the proposed method is highly cost-effective and uses limited commodity hardware during training and inference. It reduces the computational requirements 10-fold while achieving results that are comparable to state-of-the-art methods. We believe that the proposed approach is a promising direction that could open the door to solving video understanding more efficiently and enable more resource limited users to thrive in this research field.
LSP : Acceleration and Regularization of Graph Neural Networks via Locality Sensitive Pruning of Graphs
Nov 10, 2021

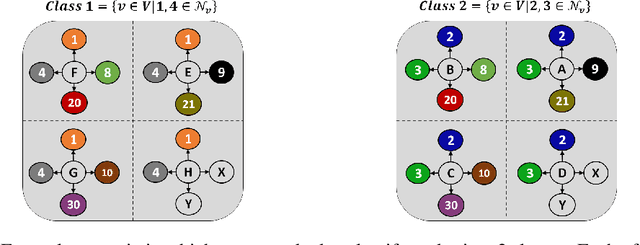
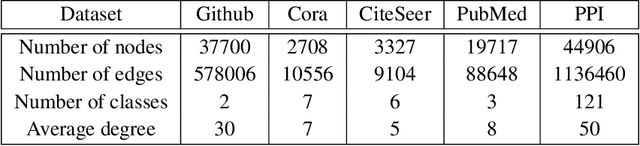
Graph Neural Networks (GNNs) have emerged as highly successful tools for graph-related tasks. However, real-world problems involve very large graphs, and the compute resources needed to fit GNNs to those problems grow rapidly. Moreover, the noisy nature and size of real-world graphs cause GNNs to over-fit if not regularized properly. Surprisingly, recent works show that large graphs often involve many redundant components that can be removed without compromising the performance too much. This includes node or edge removals during inference through GNNs layers or as a pre-processing step that sparsifies the input graph. This intriguing phenomenon enables the development of state-of-the-art GNNs that are both efficient and accurate. In this paper, we take a further step towards demystifying this phenomenon and propose a systematic method called Locality-Sensitive Pruning (LSP) for graph pruning based on Locality-Sensitive Hashing. We aim to sparsify a graph so that similar local environments of the original graph result in similar environments in the resulting sparsified graph, which is an essential feature for graph-related tasks. To justify the application of pruning based on local graph properties, we exemplify the advantage of applying pruning based on locality properties over other pruning strategies in various scenarios. Extensive experiments on synthetic and real-world datasets demonstrate the superiority of LSP, which removes a significant amount of edges from large graphs without compromising the performance, accompanied by a considerable acceleration.
Vision-Guided Forecasting -- Visual Context for Multi-Horizon Time Series Forecasting
Jul 27, 2021
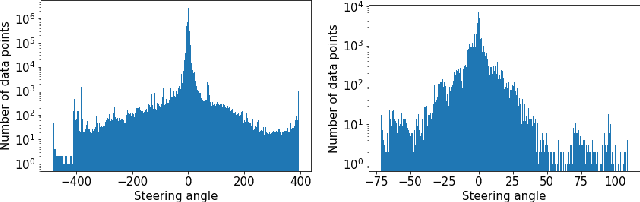

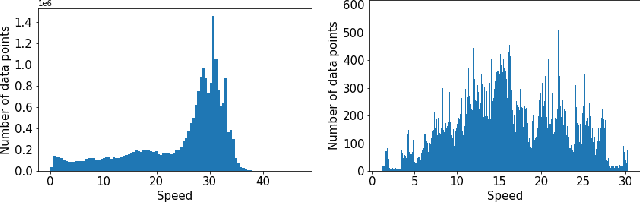
Autonomous driving gained huge traction in recent years, due to its potential to change the way we commute. Much effort has been put into trying to estimate the state of a vehicle. Meanwhile, learning to forecast the state of a vehicle ahead introduces new capabilities, such as predicting dangerous situations. Moreover, forecasting brings new supervision opportunities by learning to predict richer a context, expressed by multiple horizons. Intuitively, a video stream originated from a front-facing camera is necessary because it encodes information about the upcoming road. Besides, historical traces of the vehicle's states give more context. In this paper, we tackle multi-horizon forecasting of vehicle states by fusing the two modalities. We design and experiment with 3 end-to-end architectures that exploit 3D convolutions for visual features extraction and 1D convolutions for features extraction from speed and steering angle traces. To demonstrate the effectiveness of our method, we perform extensive experiments on two publicly available real-world datasets, Comma2k19 and the Udacity challenge. We show that we are able to forecast a vehicle's state to various horizons, while outperforming the current state-of-the-art results on the related task of driving state estimation. We examine the contribution of vision features, and find that a model fed with vision features achieves an error that is 56.6% and 66.9% of the error of a model that doesn't use those features, on the Udacity and Comma2k19 datasets respectively.