 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePREGEN: Uncovering Latent Thoughts in Composed Video Retrieval
Jan 20, 2026Composed Video Retrieval (CoVR) aims to retrieve a video based on a query video and a modifying text. Current CoVR methods fail to fully exploit modern Vision-Language Models (VLMs), either using outdated architectures or requiring computationally expensive fine-tuning and slow caption generation. We introduce PREGEN (PRE GENeration extraction), an efficient and powerful CoVR framework that overcomes these limitations. Our approach uniquely pairs a frozen, pre-trained VLM with a lightweight encoding model, eliminating the need for any VLM fine-tuning. We feed the query video and modifying text into the VLM and extract the hidden state of the final token from each layer. A simple encoder is then trained on these pooled representations, creating a semantically rich and compact embedding for retrieval. PREGEN significantly advances the state of the art, surpassing all prior methods on standard CoVR benchmarks with substantial gains in Recall@1 of +27.23 and +69.59. Our method demonstrates robustness across different VLM backbones and exhibits strong zero-shot generalization to more complex textual modifications, highlighting its effectiveness and semantic capabilities.
Robot Instance Segmentation with Few Annotations for Grasping
Jul 01, 2024The ability of robots to manipulate objects relies heavily on their aptitude for visual perception. In domains characterized by cluttered scenes and high object variability, most methods call for vast labeled datasets, laboriously hand-annotated, with the aim of training capable models. Once deployed, the challenge of generalizing to unfamiliar objects implies that the model must evolve alongside its domain. To address this, we propose a novel framework that combines Semi-Supervised Learning (SSL) with Learning Through Interaction (LTI), allowing a model to learn by observing scene alterations and leverage visual consistency despite temporal gaps without requiring curated data of interaction sequences. As a result, our approach exploits partially annotated data through self-supervision and incorporates temporal context using pseudo-sequences generated from unlabeled still images. We validate our method on two common benchmarks, ARMBench mix-object-tote and OCID, where it achieves state-of-the-art performance. Notably, on ARMBench, we attain an $\text{AP}_{50}$ of $86.37$, almost a $20\%$ improvement over existing work, and obtain remarkable results in scenarios with extremely low annotation, achieving an $\text{AP}_{50}$ score of $84.89$ with just $1 \%$ of annotated data compared to $72$ presented in ARMBench on the fully annotated counterpart.
Terraforming -- Environment Manipulation during Disruptions for Multi-Agent Pickup and Delivery
May 19, 2023In automated warehouses, teams of mobile robots fulfill the packaging process by transferring inventory pods to designated workstations while navigating narrow aisles formed by tightly packed pods. This problem is typically modeled as a Multi-Agent Pickup and Delivery (MAPD) problem, which is then solved by repeatedly planning collision-free paths for agents on a fixed graph, as in the Rolling-Horizon Collision Resolution (RHCR) algorithm. However, existing approaches make the limiting assumption that agents are only allowed to move pods that correspond to their current task, while considering the other pods as stationary obstacles (even though all pods are movable). This behavior can result in unnecessarily long paths which could otherwise be avoided by opening additional corridors via pod manipulation. To this end, we explore the implications of allowing agents the flexibility of dynamically relocating pods. We call this new problem Terraforming MAPD (tMAPD) and develop an RHCR-based approach to tackle it. As the extra flexibility of terraforming comes at a significant computational cost, we utilize this capability judiciously by identifying situations where it could make a significant impact on the solution quality. In particular, we invoke terraforming in response to disruptions that often occur in automated warehouses, e.g., when an item is dropped from a pod or when agents malfunction. Empirically, using our approach for tMAPD, where disruptions are modeled via a stochastic process, we improve throughput by over 10%, reduce the maximum service time (the difference between the drop-off time and the pickup time of a pod) by more than 50%, without drastically increasing the runtime, compared to the MAPD setting.
Multi-Agent Terraforming: Efficient Multi-Agent Path Finding via Environment Manipulation
Mar 20, 2022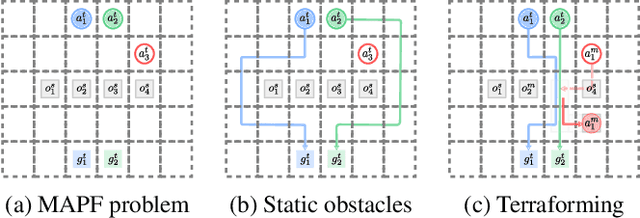
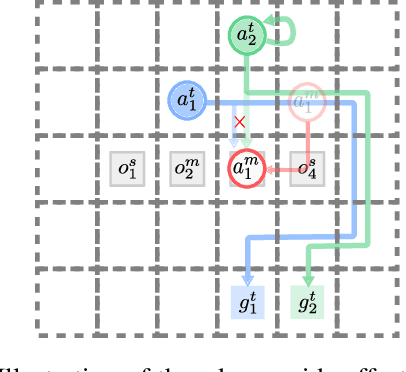
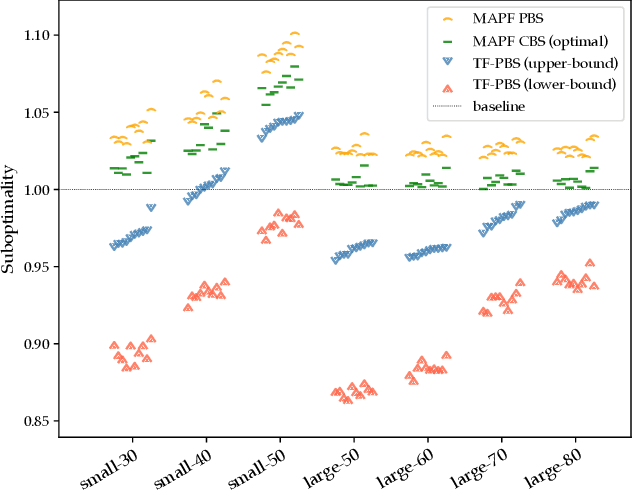
Multi-agent pathfinding (MAPF) is concerned with planning collision-free paths for a team of agents from their start to goal locations in an environment cluttered with obstacles. Typical approaches for MAPF consider the locations of obstacles as being fixed, which limits their effectiveness in automated warehouses, where obstacles (representing pods or shelves) can be moved out of the way by agents (representing robots) to relieve bottlenecks and introduce shorter routes. In this work we initiate the study of MAPF with movable obstacles. In particular, we introduce a new extension of MAPF, which we call Terraforming MAPF (tMAPF), where some agents are responsible for moving obstacles to clear the way for other agents. Solving tMAPF is extremely challenging as it requires reasoning not only about collisions between agents, but also where and when obstacles should be moved. We present extensions of two state-of-the-art algorithms, CBS and PBS, in order to tackle tMAPF, and demonstrate that they can consistently outperform the best solution possible under a static-obstacle setting.