 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Where It Matters: High-Resolution Crops Retrieval for Efficient VLMs
Mar 14, 2026Vision-language models (VLMs) typically process images at a native high-resolution, forcing a trade-off between accuracy and computational efficiency: high-resolution inputs capture fine details but incur significant computational costs, while low-resolution inputs advocate for efficiency, they potentially miss critical visual information, like small text. We present AwaRes, a spatial-on-demand framework that resolves this accuracy-efficiency trade-off by operating on a low-resolution global view and using tool-calling to retrieve only high-resolution segments needed for a given query. We construct supervised data automatically: a judge compares low- vs.\ high-resolution answers to label whether cropping is needed, and an oracle grounding model localizes the evidence for the correct answer, which we map to a discrete crop set to form multi-turn tool-use trajectories. We train our framework with cold-start SFT followed by multi-turn GRPO with a composite reward that combines semantic answer correctness with explicit crop-cost penalties. Project page: https://nimrodshabtay.github.io/AwaRes
No Data, No Optimization: A Lightweight Method To Disrupt Neural Networks With Sign-Flips
Feb 11, 2025Deep Neural Networks (DNNs) can be catastrophically disrupted by flipping only a handful of sign bits in their parameters. We introduce Deep Neural Lesion (DNL), a data-free, lightweight method that locates these critical parameters and triggers massive accuracy drops. We validate its efficacy on a wide variety of computer vision models and datasets. The method requires no training data or optimization and can be carried out via common exploits software, firmware or hardware based attack vectors. An enhanced variant that uses a single forward and backward pass further amplifies the damage beyond DNL's zero-pass approach. Flipping just two sign bits in ResNet50 on ImageNet reduces accuracy by 99.8\%. We also show that selectively protecting a small fraction of vulnerable sign bits provides a practical defense against such attacks.
Hysteresis Activation Function for Efficient Inference
Nov 15, 2024



The widely used ReLU is favored for its hardware efficiency, {as the implementation at inference is a one bit sign case,} yet suffers from issues such as the ``dying ReLU'' problem, where during training, neurons fail to activate and constantly remain at zero, as highlighted by Lu et al. Traditional approaches to mitigate this issue often introduce more complex and less hardware-friendly activation functions. In this work, we propose a Hysteresis Rectified Linear Unit (HeLU), an efficient activation function designed to address the ``dying ReLU'' problem with minimal complexity. Unlike traditional activation functions with fixed thresholds for training and inference, HeLU employs a variable threshold that refines the backpropagation. This refined mechanism allows simpler activation functions to achieve competitive performance comparable to their more complex counterparts without introducing unnecessary complexity or requiring inductive biases. Empirical evaluations demonstrate that HeLU enhances model generalization across diverse datasets, offering a promising solution for efficient and effective inference suitable for a wide range of neural network architectures.
Context-aware Prompt Tuning: Advancing In-Context Learning with Adversarial Methods
Oct 22, 2024Fine-tuning Large Language Models (LLMs) typically involves updating at least a few billions of parameters. A more parameter-efficient approach is Prompt Tuning (PT), which updates only a few learnable tokens, and differently, In-Context Learning (ICL) adapts the model to a new task by simply including examples in the input without any training. When applying optimization-based methods, such as fine-tuning and PT for few-shot learning, the model is specifically adapted to the small set of training examples, whereas ICL leaves the model unchanged. This distinction makes traditional learning methods more prone to overfitting; in contrast, ICL is less sensitive to the few-shot scenario. While ICL is not prone to overfitting, it does not fully extract the information that exists in the training examples. This work introduces Context-aware Prompt Tuning (CPT), a method inspired by ICL, PT, and adversarial attacks. We build on the ICL strategy of concatenating examples before the input, but we extend this by PT-like learning, refining the context embedding through iterative optimization to extract deeper insights from the training examples. We carefully modify specific context tokens, considering the unique structure of input and output formats. Inspired by adversarial attacks, we adjust the input based on the labels present in the context, focusing on minimizing, rather than maximizing, the loss. Moreover, we apply a projected gradient descent algorithm to keep token embeddings close to their original values, under the assumption that the user-provided data is inherently valuable. Our method has been shown to achieve superior accuracy across multiple classification tasks using various LLM models.
Robot Instance Segmentation with Few Annotations for Grasping
Jul 01, 2024The ability of robots to manipulate objects relies heavily on their aptitude for visual perception. In domains characterized by cluttered scenes and high object variability, most methods call for vast labeled datasets, laboriously hand-annotated, with the aim of training capable models. Once deployed, the challenge of generalizing to unfamiliar objects implies that the model must evolve alongside its domain. To address this, we propose a novel framework that combines Semi-Supervised Learning (SSL) with Learning Through Interaction (LTI), allowing a model to learn by observing scene alterations and leverage visual consistency despite temporal gaps without requiring curated data of interaction sequences. As a result, our approach exploits partially annotated data through self-supervision and incorporates temporal context using pseudo-sequences generated from unlabeled still images. We validate our method on two common benchmarks, ARMBench mix-object-tote and OCID, where it achieves state-of-the-art performance. Notably, on ARMBench, we attain an $\text{AP}_{50}$ of $86.37$, almost a $20\%$ improvement over existing work, and obtain remarkable results in scenarios with extremely low annotation, achieving an $\text{AP}_{50}$ score of $84.89$ with just $1 \%$ of annotated data compared to $72$ presented in ARMBench on the fully annotated counterpart.
Benchmarking Label Noise in Instance Segmentation: Spatial Noise Matters
Jun 18, 2024



Obtaining accurate labels for instance segmentation is particularly challenging due to the complex nature of the task. Each image necessitates multiple annotations, encompassing not only the object's class but also its precise spatial boundaries. These requirements elevate the likelihood of errors and inconsistencies in both manual and automated annotation processes. By simulating different noise conditions, we provide a realistic scenario for assessing the robustness and generalization capabilities of instance segmentation models in different segmentation tasks, introducing COCO-N and Cityscapes-N. We also propose a benchmark for weakly annotation noise, dubbed COCO-WAN, which utilizes foundation models and weak annotations to simulate semi-automated annotation tools and their noisy labels. This study sheds light on the quality of segmentation masks produced by various models and challenges the efficacy of popular methods designed to address learning with label noise.
Semi-Supervised Semantic Segmentation via Marginal Contextual Information
Aug 26, 2023
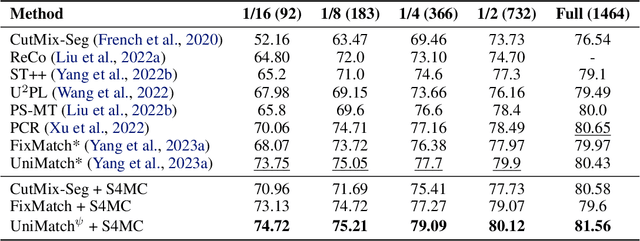
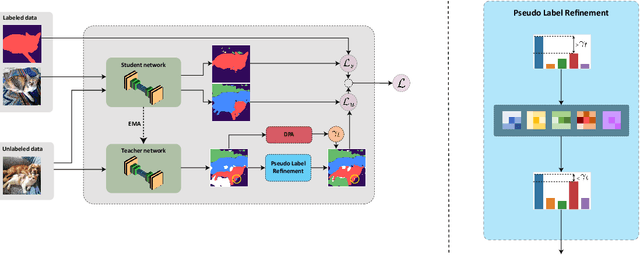
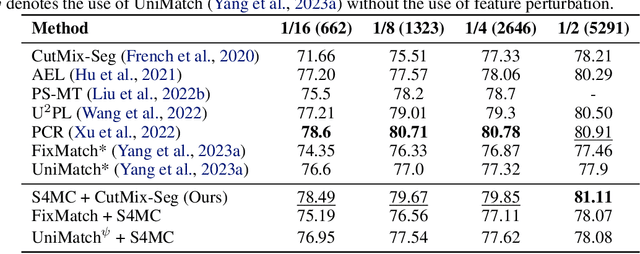
We present a novel confidence refinement scheme that enhances pseudo-labels in semi-supervised semantic segmentation. Unlike current leading methods, which filter pixels with low-confidence predictions in isolation, our approach leverages the spatial correlation of labels in segmentation maps by grouping neighboring pixels and considering their pseudo-labels collectively. With this contextual information, our method, named S4MC, increases the amount of unlabeled data used during training while maintaining the quality of the pseudo-labels, all with negligible computational overhead. Through extensive experiments on standard benchmarks, we demonstrate that S4MC outperforms existing state-of-the-art semi-supervised learning approaches, offering a promising solution for reducing the cost of acquiring dense annotations. For example, S4MC achieves a 1.29 mIoU improvement over the prior state-of-the-art method on PASCAL VOC 12 with 366 annotated images. The code to reproduce our experiments is available at https://s4mcontext.github.io/
FBM: Fast-Bit Allocation for Mixed-Precision Quantization
May 30, 2022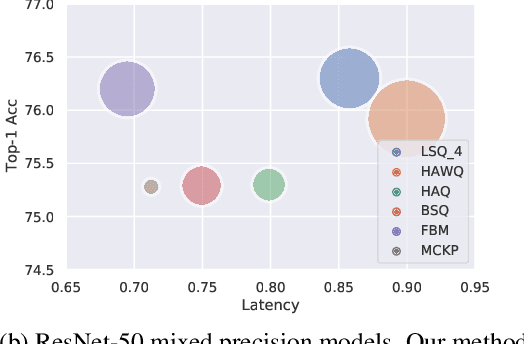
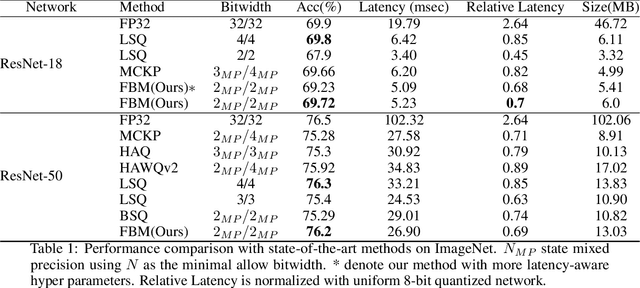
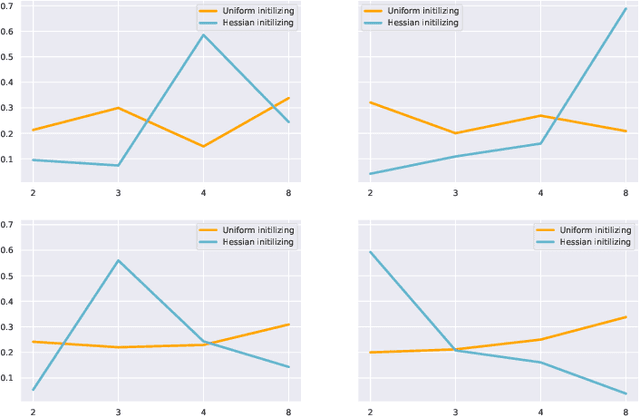
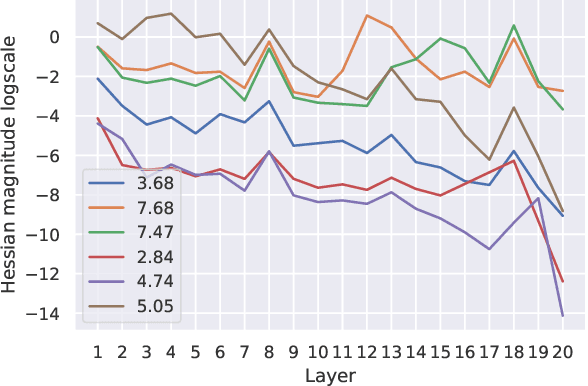
Quantized neural networks are well known for reducing latency, power consumption, and model size without significant degradation in accuracy, making them highly applicable for systems with limited resources and low power requirements. Mixed precision quantization offers better utilization of customized hardware that supports arithmetic operations at different bitwidths. Existing mixed-precision schemes rely on having a high exploration space, resulting in a large carbon footprint. In addition, these bit allocation strategies mostly induce constraints on the model size rather than utilizing the performance of neural network deployment on specific hardware. Our work proposes Fast-Bit Allocation for Mixed-Precision Quantization (FBM), which finds an optimal bitwidth allocation by measuring desired behaviors through a simulation of a specific device, or even on a physical one. While dynamic transitions of bit allocation in mixed precision quantization with ultra-low bitwidth are known to suffer from performance degradation, we present a fast recovery solution from such transitions. A comprehensive evaluation of the proposed method on CIFAR-10 and ImageNet demonstrates our method's superiority over current state-of-the-art schemes in terms of the trade-off between neural network accuracy and hardware efficiency. Our source code, experimental settings and quantized models are available at https://github.com/RamorayDrake/FBM/
Bimodal Distributed Binarized Neural Networks
Apr 05, 2022
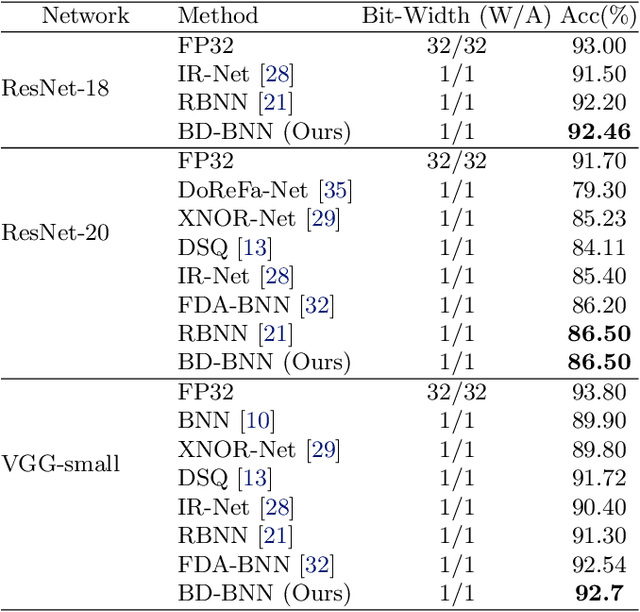

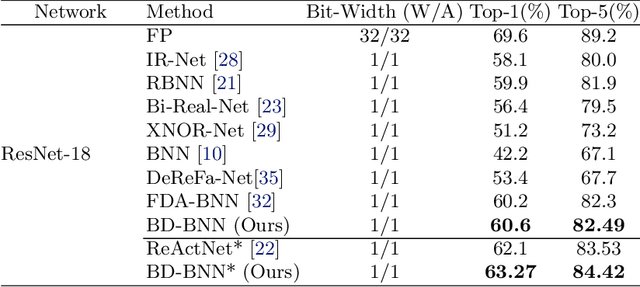
Binary Neural Networks (BNNs) are an extremely promising method to reduce deep neural networks' complexity and power consumption massively. Binarization techniques, however, suffer from ineligible performance degradation compared to their full-precision counterparts. Prior work mainly focused on strategies for sign function approximation during forward and backward phases to reduce the quantization error during the binarization process. In this work, we propose a Bi-Modal Distributed binarization method (\methodname{}). That imposes bi-modal distribution of the network weights by kurtosis regularization. The proposed method consists of a training scheme that we call Weight Distribution Mimicking (WDM), which efficiently imitates the full-precision network weight distribution to their binary counterpart. Preserving this distribution during binarization-aware training creates robust and informative binary feature maps and significantly reduces the generalization error of the BNN. Extensive evaluations on CIFAR-10 and ImageNet demonstrate the superiority of our method over current state-of-the-art schemes. Our source code, experimental settings, training logs, and binary models are available at \url{https://github.com/BlueAnon/BD-BNN}.