 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFBM: Fast-Bit Allocation for Mixed-Precision Quantization
May 30, 2022
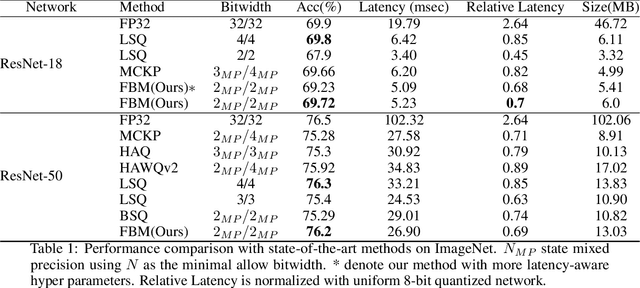
Quantized neural networks are well known for reducing latency, power consumption, and model size without significant degradation in accuracy, making them highly applicable for systems with limited resources and low power requirements. Mixed precision quantization offers better utilization of customized hardware that supports arithmetic operations at different bitwidths. Existing mixed-precision schemes rely on having a high exploration space, resulting in a large carbon footprint. In addition, these bit allocation strategies mostly induce constraints on the model size rather than utilizing the performance of neural network deployment on specific hardware. Our work proposes Fast-Bit Allocation for Mixed-Precision Quantization (FBM), which finds an optimal bitwidth allocation by measuring desired behaviors through a simulation of a specific device, or even on a physical one. While dynamic transitions of bit allocation in mixed precision quantization with ultra-low bitwidth are known to suffer from performance degradation, we present a fast recovery solution from such transitions. A comprehensive evaluation of the proposed method on CIFAR-10 and ImageNet demonstrates our method's superiority over current state-of-the-art schemes in terms of the trade-off between neural network accuracy and hardware efficiency. Our source code, experimental settings and quantized models are available at https://github.com/RamorayDrake/FBM/
Bimodal Distributed Binarized Neural Networks
Apr 05, 2022
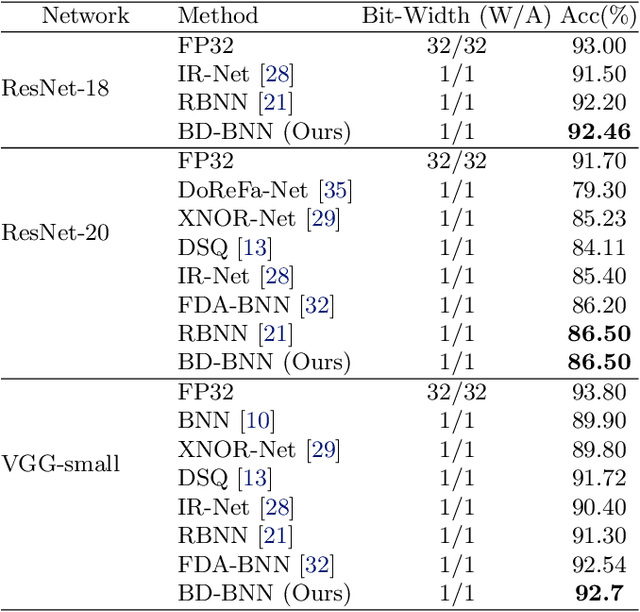

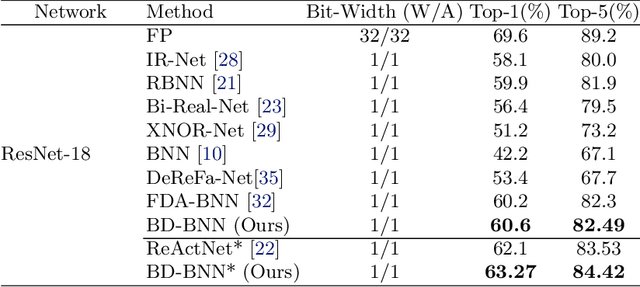
Binary Neural Networks (BNNs) are an extremely promising method to reduce deep neural networks' complexity and power consumption massively. Binarization techniques, however, suffer from ineligible performance degradation compared to their full-precision counterparts. Prior work mainly focused on strategies for sign function approximation during forward and backward phases to reduce the quantization error during the binarization process. In this work, we propose a Bi-Modal Distributed binarization method (\methodname{}). That imposes bi-modal distribution of the network weights by kurtosis regularization. The proposed method consists of a training scheme that we call Weight Distribution Mimicking (WDM), which efficiently imitates the full-precision network weight distribution to their binary counterpart. Preserving this distribution during binarization-aware training creates robust and informative binary feature maps and significantly reduces the generalization error of the BNN. Extensive evaluations on CIFAR-10 and ImageNet demonstrate the superiority of our method over current state-of-the-art schemes. Our source code, experimental settings, training logs, and binary models are available at \url{https://github.com/BlueAnon/BD-BNN}.