 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Optimal Compression: Joint Pruning and Quantization
Feb 15, 2023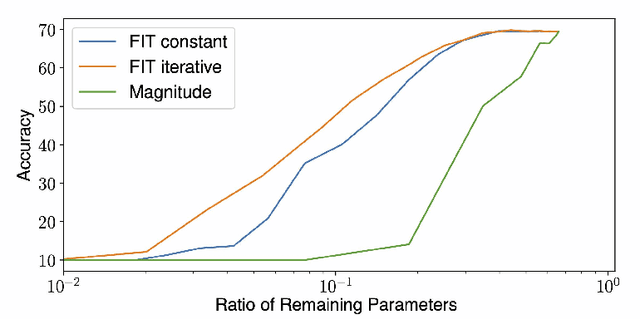
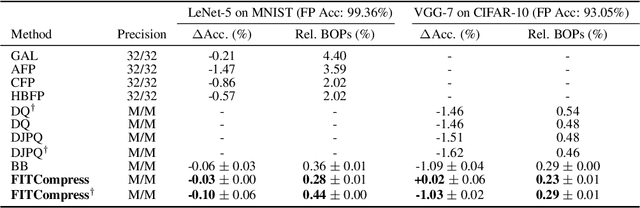
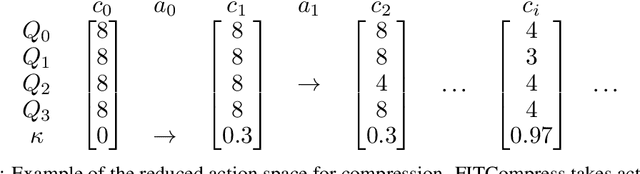
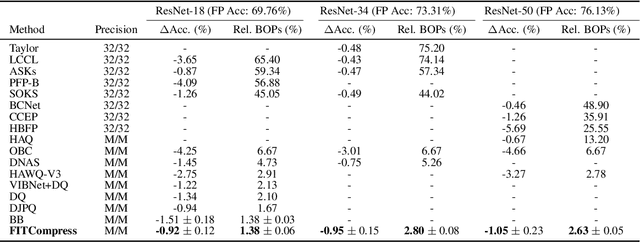
Compression of deep neural networks has become a necessary stage for optimizing model inference on resource-constrained hardware. This paper presents FITCompress, a method for unifying layer-wise mixed precision quantization and pruning under a single heuristic, as an alternative to neural architecture search and Bayesian-based techniques. FITCompress combines the Fisher Information Metric, and path planning through compression space, to pick optimal configurations given size and operation constraints with single-shot fine-tuning. Experiments on ImageNet validate the method and show that our approach yields a better trade-off between accuracy and efficiency when compared to the baselines. Besides computer vision benchmarks, we experiment with the BERT model on a language understanding task, paving the way towards its optimal compression.
FIT: A Metric for Model Sensitivity
Oct 16, 2022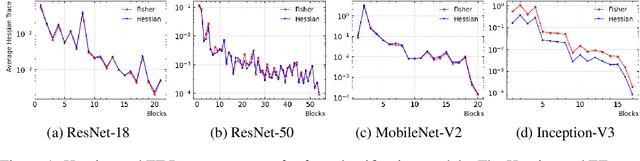


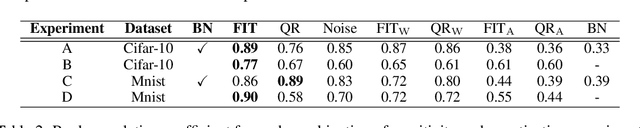
Model compression is vital to the deployment of deep learning on edge devices. Low precision representations, achieved via quantization of weights and activations, can reduce inference time and memory requirements. However, quantifying and predicting the response of a model to the changes associated with this procedure remains challenging. This response is non-linear and heterogeneous throughout the network. Understanding which groups of parameters and activations are more sensitive to quantization than others is a critical stage in maximizing efficiency. For this purpose, we propose FIT. Motivated by an information geometric perspective, FIT combines the Fisher information with a model of quantization. We find that FIT can estimate the final performance of a network without retraining. FIT effectively fuses contributions from both parameter and activation quantization into a single metric. Additionally, FIT is fast to compute when compared to existing methods, demonstrating favourable convergence properties. These properties are validated experimentally across hundreds of quantization configurations, with a focus on layer-wise mixed-precision quantization.
FBM: Fast-Bit Allocation for Mixed-Precision Quantization
May 30, 2022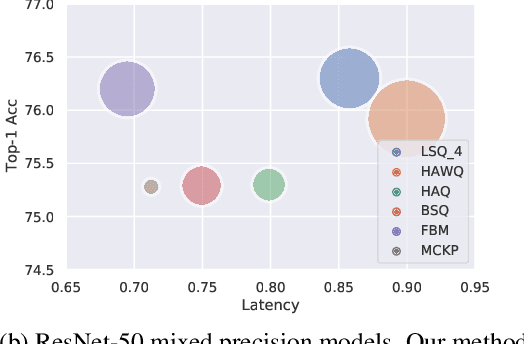
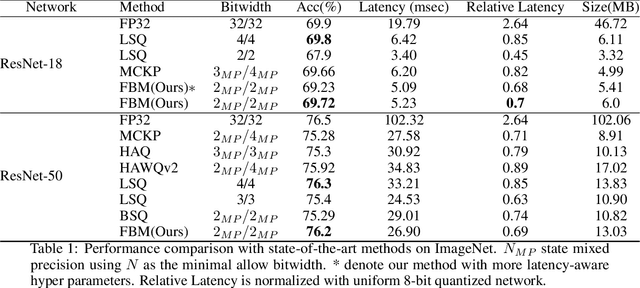
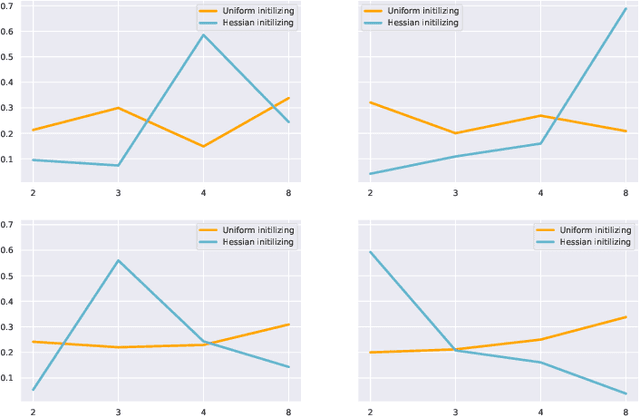
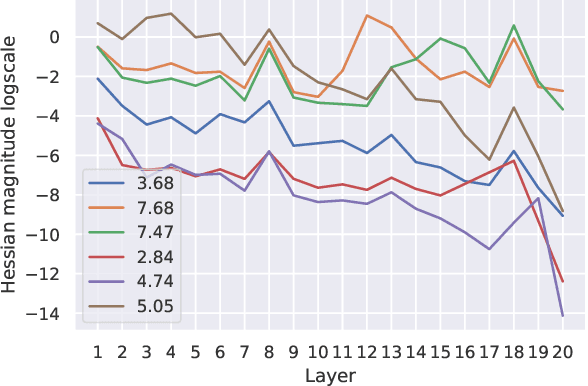
Quantized neural networks are well known for reducing latency, power consumption, and model size without significant degradation in accuracy, making them highly applicable for systems with limited resources and low power requirements. Mixed precision quantization offers better utilization of customized hardware that supports arithmetic operations at different bitwidths. Existing mixed-precision schemes rely on having a high exploration space, resulting in a large carbon footprint. In addition, these bit allocation strategies mostly induce constraints on the model size rather than utilizing the performance of neural network deployment on specific hardware. Our work proposes Fast-Bit Allocation for Mixed-Precision Quantization (FBM), which finds an optimal bitwidth allocation by measuring desired behaviors through a simulation of a specific device, or even on a physical one. While dynamic transitions of bit allocation in mixed precision quantization with ultra-low bitwidth are known to suffer from performance degradation, we present a fast recovery solution from such transitions. A comprehensive evaluation of the proposed method on CIFAR-10 and ImageNet demonstrates our method's superiority over current state-of-the-art schemes in terms of the trade-off between neural network accuracy and hardware efficiency. Our source code, experimental settings and quantized models are available at https://github.com/RamorayDrake/FBM/
Lightweight Jet Reconstruction and Identification as an Object Detection Task
Feb 09, 2022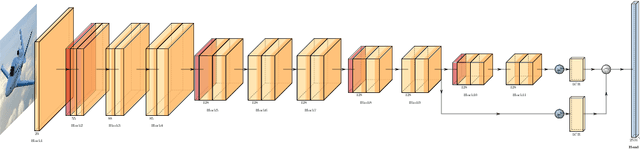
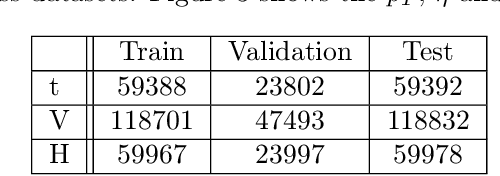
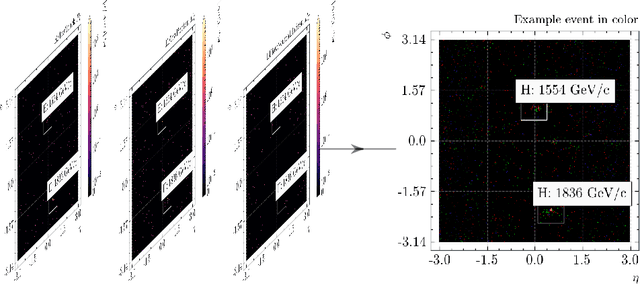
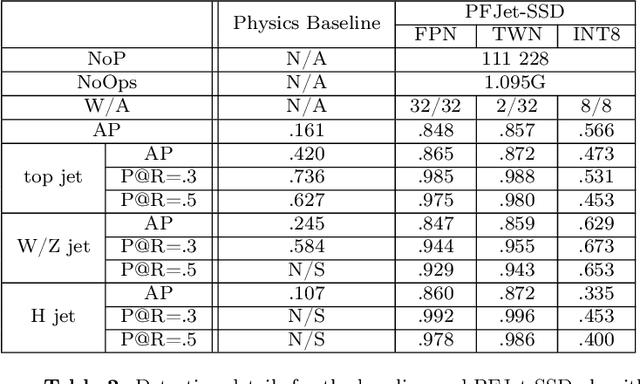
We apply object detection techniques based on deep convolutional blocks to end-to-end jet identification and reconstruction tasks encountered at the CERN Large Hadron Collider (LHC). Collision events produced at the LHC and represented as an image composed of calorimeter and tracker cells are given as an input to a Single Shot Detection network. The algorithm, named PFJet-SSD performs simultaneous localization, classification and regression tasks to cluster jets and reconstruct their features. This all-in-one single feed-forward pass gives advantages in terms of execution time and an improved accuracy w.r.t. traditional rule-based methods. A further gain is obtained from network slimming, homogeneous quantization, and optimized runtime for meeting memory and latency constraints of a typical real-time processing environment. We experiment with 8-bit and ternary quantization, benchmarking their accuracy and inference latency against a single-precision floating-point. We show that the ternary network closely matches the performance of its full-precision equivalent and outperforms the state-of-the-art rule-based algorithm. Finally, we report the inference latency on different hardware platforms and discuss future applications.