 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRational Inverse Reasoning
Aug 12, 2025



Humans can observe a single, imperfect demonstration and immediately generalize to very different problem settings. Robots, in contrast, often require hundreds of examples and still struggle to generalize beyond the training conditions. We argue that this limitation arises from the inability to recover the latent explanations that underpin intelligent behavior, and that these explanations can take the form of structured programs consisting of high-level goals, sub-task decomposition, and execution constraints. In this work, we introduce Rational Inverse Reasoning (RIR), a framework for inferring these latent programs through a hierarchical generative model of behavior. RIR frames few-shot imitation as Bayesian program induction: a vision-language model iteratively proposes structured symbolic task hypotheses, while a planner-in-the-loop inference scheme scores each by the likelihood of the observed demonstration under that hypothesis. This loop yields a posterior over concise, executable programs. We evaluate RIR on a suite of continuous manipulation tasks designed to test one-shot and few-shot generalization across variations in object pose, count, geometry, and layout. With as little as one demonstration, RIR infers the intended task structure and generalizes to novel settings, outperforming state-of-the-art vision-language model baselines.
Investigating Vision Foundational Models for Tactile Representation Learning
Apr 30, 2023



Tactile representation learning (TRL) equips robots with the ability to leverage touch information, boosting performance in tasks such as environment perception and object manipulation. However, the heterogeneity of tactile sensors results in many sensor- and task-specific learning approaches. This limits the efficacy of existing tactile datasets, and the subsequent generalisability of any learning outcome. In this work, we investigate the applicability of vision foundational models to sensor-agnostic TRL, via a simple yet effective transformation technique to feed the heterogeneous sensor readouts into the model. Our approach recasts TRL as a computer vision (CV) problem, which permits the application of various CV techniques for tackling TRL-specific challenges. We evaluate our approach on multiple benchmark tasks, using datasets collected from four different tactile sensors. Empirically, we demonstrate significant improvements in task performance, model robustness, as well as cross-sensor and cross-task knowledge transferability with limited data requirements.
Towards Optimal Compression: Joint Pruning and Quantization
Feb 15, 2023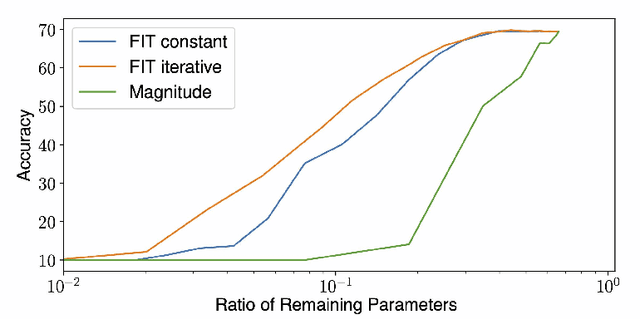
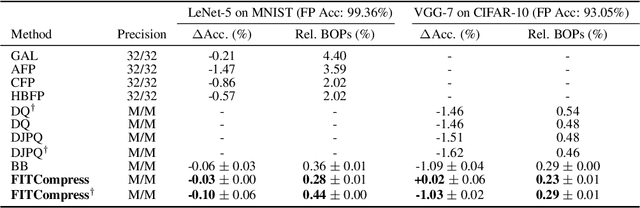
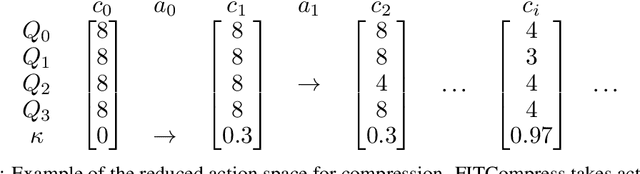
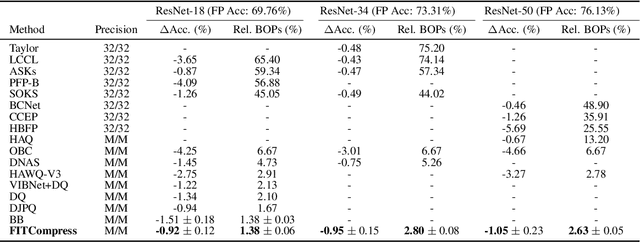
Compression of deep neural networks has become a necessary stage for optimizing model inference on resource-constrained hardware. This paper presents FITCompress, a method for unifying layer-wise mixed precision quantization and pruning under a single heuristic, as an alternative to neural architecture search and Bayesian-based techniques. FITCompress combines the Fisher Information Metric, and path planning through compression space, to pick optimal configurations given size and operation constraints with single-shot fine-tuning. Experiments on ImageNet validate the method and show that our approach yields a better trade-off between accuracy and efficiency when compared to the baselines. Besides computer vision benchmarks, we experiment with the BERT model on a language understanding task, paving the way towards its optimal compression.
FIT: A Metric for Model Sensitivity
Oct 16, 2022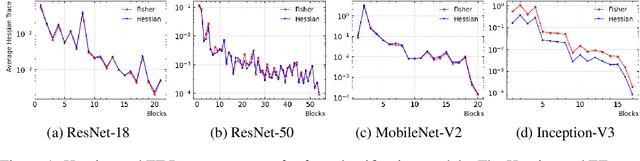


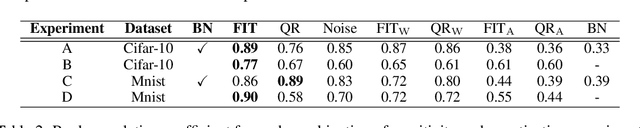
Model compression is vital to the deployment of deep learning on edge devices. Low precision representations, achieved via quantization of weights and activations, can reduce inference time and memory requirements. However, quantifying and predicting the response of a model to the changes associated with this procedure remains challenging. This response is non-linear and heterogeneous throughout the network. Understanding which groups of parameters and activations are more sensitive to quantization than others is a critical stage in maximizing efficiency. For this purpose, we propose FIT. Motivated by an information geometric perspective, FIT combines the Fisher information with a model of quantization. We find that FIT can estimate the final performance of a network without retraining. FIT effectively fuses contributions from both parameter and activation quantization into a single metric. Additionally, FIT is fast to compute when compared to existing methods, demonstrating favourable convergence properties. These properties are validated experimentally across hundreds of quantization configurations, with a focus on layer-wise mixed-precision quantization.