 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTactile DreamFusion: Exploiting Tactile Sensing for 3D Generation
Dec 09, 2024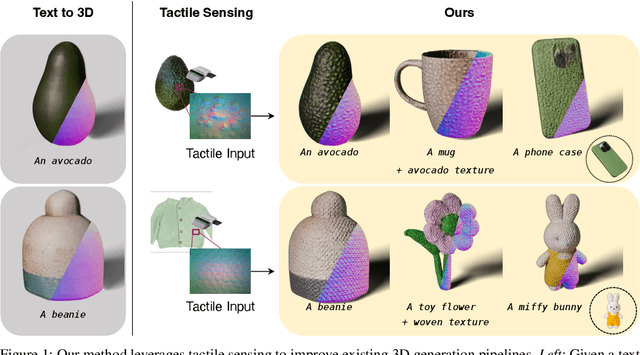
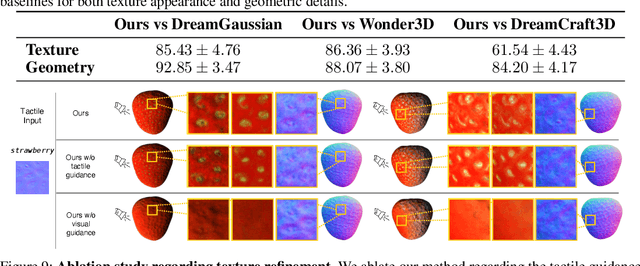
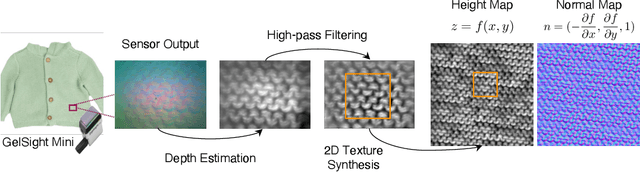

3D generation methods have shown visually compelling results powered by diffusion image priors. However, they often fail to produce realistic geometric details, resulting in overly smooth surfaces or geometric details inaccurately baked in albedo maps. To address this, we introduce a new method that incorporates touch as an additional modality to improve the geometric details of generated 3D assets. We design a lightweight 3D texture field to synthesize visual and tactile textures, guided by 2D diffusion model priors on both visual and tactile domains. We condition the visual texture generation on high-resolution tactile normals and guide the patch-based tactile texture refinement with a customized TextureDreambooth. We further present a multi-part generation pipeline that enables us to synthesize different textures across various regions. To our knowledge, we are the first to leverage high-resolution tactile sensing to enhance geometric details for 3D generation tasks. We evaluate our method in both text-to-3D and image-to-3D settings. Our experiments demonstrate that our method provides customized and realistic fine geometric textures while maintaining accurate alignment between two modalities of vision and touch.
Controllable Visual-Tactile Synthesis
May 04, 2023



Deep generative models have various content creation applications such as graphic design, e-commerce, and virtual Try-on. However, current works mainly focus on synthesizing realistic visual outputs, often ignoring other sensory modalities, such as touch, which limits physical interaction with users. In this work, we leverage deep generative models to create a multi-sensory experience where users can touch and see the synthesized object when sliding their fingers on a haptic surface. The main challenges lie in the significant scale discrepancy between vision and touch sensing and the lack of explicit mapping from touch sensing data to a haptic rendering device. To bridge this gap, we collect high-resolution tactile data with a GelSight sensor and create a new visuotactile clothing dataset. We then develop a conditional generative model that synthesizes both visual and tactile outputs from a single sketch. We evaluate our method regarding image quality and tactile rendering accuracy. Finally, we introduce a pipeline to render high-quality visual and tactile outputs on an electroadhesion-based haptic device for an immersive experience, allowing for challenging materials and editable sketch inputs.
Investigating Vision Foundational Models for Tactile Representation Learning
Apr 30, 2023



Tactile representation learning (TRL) equips robots with the ability to leverage touch information, boosting performance in tasks such as environment perception and object manipulation. However, the heterogeneity of tactile sensors results in many sensor- and task-specific learning approaches. This limits the efficacy of existing tactile datasets, and the subsequent generalisability of any learning outcome. In this work, we investigate the applicability of vision foundational models to sensor-agnostic TRL, via a simple yet effective transformation technique to feed the heterogeneous sensor readouts into the model. Our approach recasts TRL as a computer vision (CV) problem, which permits the application of various CV techniques for tackling TRL-specific challenges. We evaluate our approach on multiple benchmark tasks, using datasets collected from four different tactile sensors. Empirically, we demonstrate significant improvements in task performance, model robustness, as well as cross-sensor and cross-task knowledge transferability with limited data requirements.
Runtime-Safety-Guided Policy Repair
Aug 17, 2020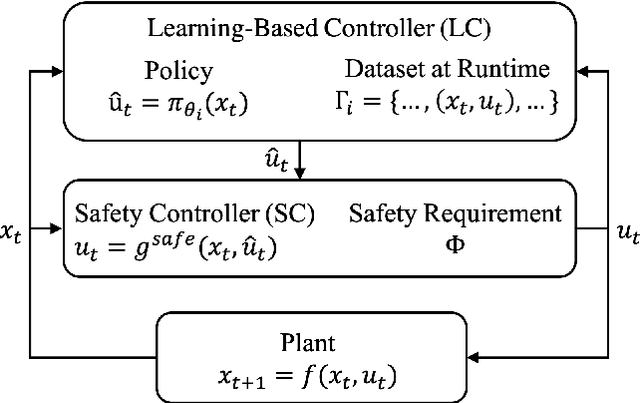
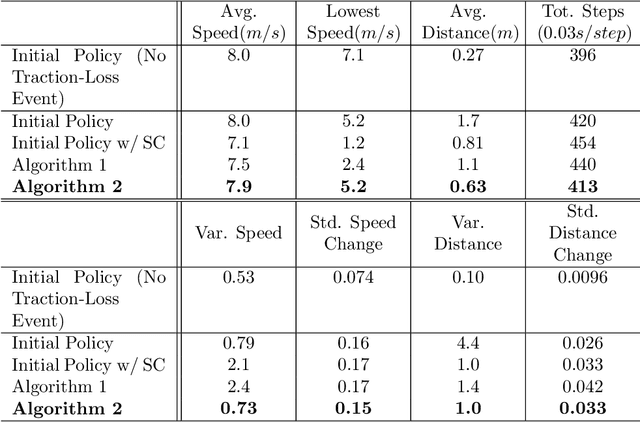
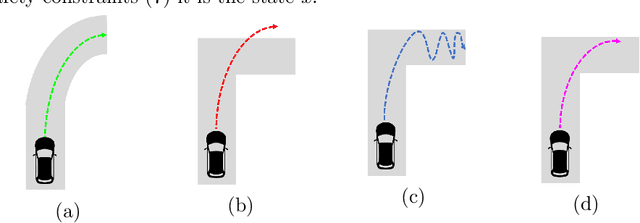
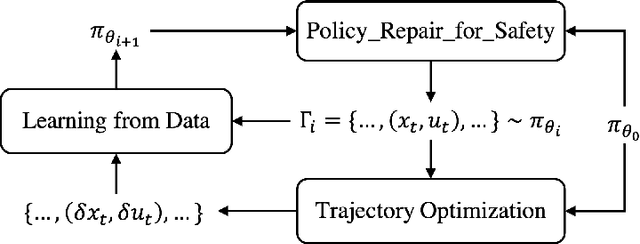
We study the problem of policy repair for learning-based control policies in safety-critical settings. We consider an architecture where a high-performance learning-based control policy (e.g. one trained as a neural network) is paired with a model-based safety controller. The safety controller is endowed with the abilities to predict whether the trained policy will lead the system to an unsafe state, and take over control when necessary. While this architecture can provide added safety assurances, intermittent and frequent switching between the trained policy and the safety controller can result in undesirable behaviors and reduced performance. We propose to reduce or even eliminate control switching by `repairing' the trained policy based on runtime data produced by the safety controller in a way that deviates minimally from the original policy. The key idea behind our approach is the formulation of a trajectory optimization problem that allows the joint reasoning of policy update and safety constraints. Experimental results demonstrate that our approach is effective even when the system model in the safety controller is unknown and only approximated.