 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation
Jan 11, 2026Recent advancements in vision-language-action (VLA) models have shown promise in robotic manipulation, yet they continue to struggle with long-horizon, multi-step tasks. Existing methods lack internal reasoning mechanisms that can identify task-relevant interaction cues or track progress within a subtask, leading to critical execution errors such as repeated actions, missed steps, and premature termination. To address these challenges, we introduce PALM, a VLA framework that structures policy learning around interaction-centric affordance reasoning and subtask progress cues. PALM distills complementary affordance representations that capture object relevance, contact geometry, spatial placements, and motion dynamics, and serve as task-relevant anchors for visuomotor control. To further stabilize long-horizon execution, PALM predicts continuous within-subtask progress, enabling seamless subtask transitions. Across extensive simulation and real-world experiments, PALM consistently outperforms baselines, achieving a 91.8% success rate on LIBERO-LONG, a 12.5% improvement in average length on CALVIN ABC->D, and a 2x improvement over real-world baselines across three long-horizon generalization settings.
Wisdom of the Crowd: Reinforcement Learning from Coevolutionary Collective Feedback
Aug 17, 2025



Reinforcement learning (RL) has significantly enhanced the reasoning capabilities of large language models (LLMs), but its reliance on expensive human-labeled data or complex reward models severely limits scalability. While existing self-feedback methods aim to address this problem, they are constrained by the capabilities of a single model, which can lead to overconfidence in incorrect answers, reward hacking, and even training collapse. To this end, we propose Reinforcement Learning from Coevolutionary Collective Feedback (RLCCF), a novel RL framework that enables multi-model collaborative evolution without external supervision. Specifically, RLCCF optimizes the ability of a model collective by maximizing its Collective Consistency (CC), which jointly trains a diverse ensemble of LLMs and provides reward signals by voting on collective outputs. Moreover, each model's vote is weighted by its Self-Consistency (SC) score, ensuring that more confident models contribute more to the collective decision. Benefiting from the diverse output distributions and complementary abilities of multiple LLMs, RLCCF enables the model collective to continuously enhance its reasoning ability through coevolution. Experiments on four mainstream open-source LLMs across four mathematical reasoning benchmarks demonstrate that our framework yields significant performance gains, achieving an average relative improvement of 16.72\% in accuracy. Notably, RLCCF not only improves the performance of individual models but also enhances the group's majority-voting accuracy by 4.51\%, demonstrating its ability to extend the collective capability boundary of the model collective.
A Modularized Design Approach for GelSight Family of Vision-based Tactile Sensors
Apr 20, 2025GelSight family of vision-based tactile sensors has proven to be effective for multiple robot perception and manipulation tasks. These sensors are based on an internal optical system and an embedded camera to capture the deformation of the soft sensor surface, inferring the high-resolution geometry of the objects in contact. However, customizing the sensors for different robot hands requires a tedious trial-and-error process to re-design the optical system. In this paper, we formulate the GelSight sensor design process as a systematic and objective-driven design problem and perform the design optimization with a physically accurate optical simulation. The method is based on modularizing and parameterizing the sensor's optical components and designing four generalizable objective functions to evaluate the sensor. We implement the method with an interactive and easy-to-use toolbox called OptiSense Studio. With the toolbox, non-sensor experts can quickly optimize their sensor design in both forward and inverse ways following our predefined modules and steps. We demonstrate our system with four different GelSight sensors by quickly optimizing their initial design in simulation and transferring it to the real sensors.
DoorBot: Closed-Loop Task Planning and Manipulation for Door Opening in the Wild with Haptic Feedback
Apr 12, 2025Robots operating in unstructured environments face significant challenges when interacting with everyday objects like doors. They particularly struggle to generalize across diverse door types and conditions. Existing vision-based and open-loop planning methods often lack the robustness to handle varying door designs, mechanisms, and push/pull configurations. In this work, we propose a haptic-aware closed-loop hierarchical control framework that enables robots to explore and open different unseen doors in the wild. Our approach leverages real-time haptic feedback, allowing the robot to adjust its strategy dynamically based on force feedback during manipulation. We test our system on 20 unseen doors across different buildings, featuring diverse appearances and mechanical types. Our framework achieves a 90% success rate, demonstrating its ability to generalize and robustly handle varied door-opening tasks. This scalable solution offers potential applications in broader open-world articulated object manipulation tasks.
VLRMBench: A Comprehensive and Challenging Benchmark for Vision-Language Reward Models
Mar 10, 2025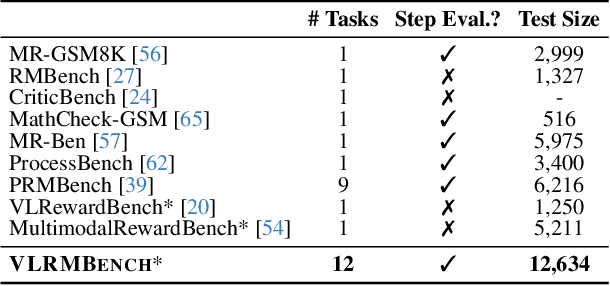
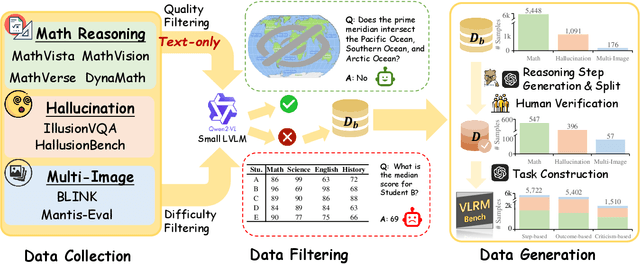
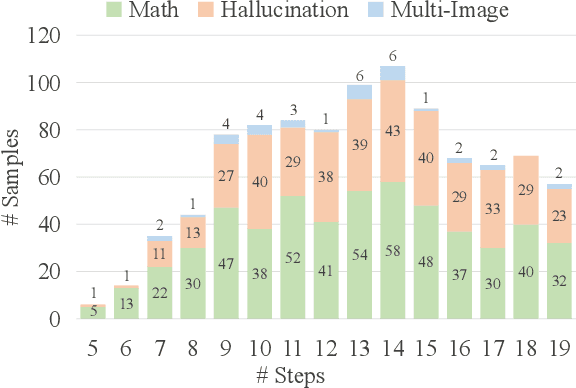
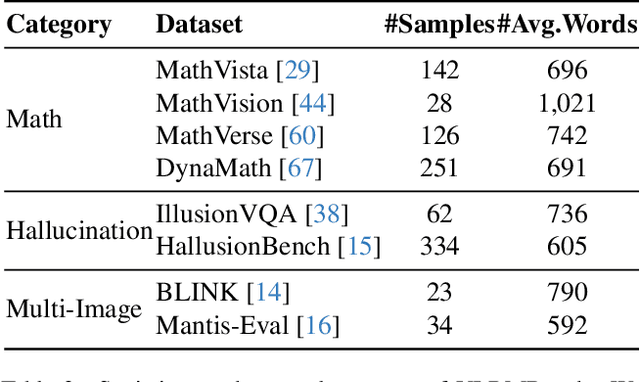
Although large visual-language models (LVLMs) have demonstrated strong performance in multimodal tasks, errors may occasionally arise due to biases during the reasoning process. Recently, reward models (RMs) have become increasingly pivotal in the reasoning process. Specifically, process RMs evaluate each reasoning step, outcome RMs focus on the assessment of reasoning results, and critique RMs perform error analysis on the entire reasoning process, followed by corrections. However, existing benchmarks for vision-language RMs (VLRMs) typically assess only a single aspect of their capabilities (e.g., distinguishing between two answers), thus limiting the all-round evaluation and restricting the development of RMs in the visual-language domain. To address this gap, we propose a comprehensive and challenging benchmark, dubbed as VLRMBench, encompassing 12,634 questions. VLRMBench is constructed based on three distinct types of datasets, covering mathematical reasoning, hallucination understanding, and multi-image understanding. We design 12 tasks across three major categories, focusing on evaluating VLRMs in the aspects of process understanding, outcome judgment, and critique generation. Extensive experiments are conducted on 21 open-source models and 5 advanced closed-source models, highlighting the challenges posed by VLRMBench. For instance, in the `Forecasting Future', a binary classification task, the advanced GPT-4o achieves only a 76.0% accuracy. Additionally, we perform comprehensive analytical studies, offering valuable insights for the future development of VLRMs. We anticipate that VLRMBench will serve as a pivotal benchmark in advancing VLRMs. Code and datasets will be available at https://github.com/JCruan519/VLRMBench.
Social Gesture Recognition in spHRI: Leveraging Fabric-Based Tactile Sensing on Humanoid Robots
Mar 05, 2025Humans are able to convey different messages using only touch. Equipping robots with the ability to understand social touch adds another modality in which humans and robots can communicate. In this paper, we present a social gesture recognition system using a fabric-based, large-scale tactile sensor integrated onto the arms of a humanoid robot. We built a social gesture dataset using multiple participants and extracted temporal features for classification. By collecting real-world data on a humanoid robot, our system provides valuable insights into human-robot social touch, further advancing the development of spHRI systems for more natural and effective communication.
Sensor-Invariant Tactile Representation
Feb 27, 2025High-resolution tactile sensors have become critical for embodied perception and robotic manipulation. However, a key challenge in the field is the lack of transferability between sensors due to design and manufacturing variations, which result in significant differences in tactile signals. This limitation hinders the ability to transfer models or knowledge learned from one sensor to another. To address this, we introduce a novel method for extracting Sensor-Invariant Tactile Representations (SITR), enabling zero-shot transfer across optical tactile sensors. Our approach utilizes a transformer-based architecture trained on a diverse dataset of simulated sensor designs, allowing it to generalize to new sensors in the real world with minimal calibration. Experimental results demonstrate the method's effectiveness across various tactile sensing applications, facilitating data and model transferability for future advancements in the field.
Learning to Double Guess: An Active Perception Approach for Estimating the Center of Mass of Arbitrary Objects
Feb 04, 2025Manipulating arbitrary objects in unstructured environments is a significant challenge in robotics, primarily due to difficulties in determining an object's center of mass. This paper introduces U-GRAPH: Uncertainty-Guided Rotational Active Perception with Haptics, a novel framework to enhance the center of mass estimation using active perception. Traditional methods often rely on single interaction and are limited by the inherent inaccuracies of Force-Torque (F/T) sensors. Our approach circumvents these limitations by integrating a Bayesian Neural Network (BNN) to quantify uncertainty and guide the robotic system through multiple, information-rich interactions via grid search and a neural network that scores each action. We demonstrate the remarkable generalizability and transferability of our method with training on a small dataset with limited variation yet still perform well on unseen complex real-world objects.
GelBelt: A Vision-based Tactile Sensor for Continuous Sensing of Large Surfaces
Jan 09, 2025Scanning large-scale surfaces is widely demanded in surface reconstruction applications and detecting defects in industries' quality control and maintenance stages. Traditional vision-based tactile sensors have shown promising performance in high-resolution shape reconstruction while suffering limitations such as small sensing areas or susceptibility to damage when slid across surfaces, making them unsuitable for continuous sensing on large surfaces. To address these shortcomings, we introduce a novel vision-based tactile sensor designed for continuous surface sensing applications. Our design uses an elastomeric belt and two wheels to continuously scan the target surface. The proposed sensor showed promising results in both shape reconstruction and surface fusion, indicating its applicability. The dot product of the estimated and reference surface normal map is reported over the sensing area and for different scanning speeds. Results indicate that the proposed sensor can rapidly scan large-scale surfaces with high accuracy at speeds up to 45 mm/s.
NormalFlow: Fast, Robust, and Accurate Contact-based Object 6DoF Pose Tracking with Vision-based Tactile Sensors
Dec 12, 2024Tactile sensing is crucial for robots aiming to achieve human-level dexterity. Among tactile-dependent skills, tactile-based object tracking serves as the cornerstone for many tasks, including manipulation, in-hand manipulation, and 3D reconstruction. In this work, we introduce NormalFlow, a fast, robust, and real-time tactile-based 6DoF tracking algorithm. Leveraging the precise surface normal estimation of vision-based tactile sensors, NormalFlow determines object movements by minimizing discrepancies between the tactile-derived surface normals. Our results show that NormalFlow consistently outperforms competitive baselines and can track low-texture objects like table surfaces. For long-horizon tracking, we demonstrate when rolling the sensor around a bead for 360 degrees, NormalFlow maintains a rotational tracking error of 2.5 degrees. Additionally, we present state-of-the-art tactile-based 3D reconstruction results, showcasing the high accuracy of NormalFlow. We believe NormalFlow unlocks new possibilities for high-precision perception and manipulation tasks that involve interacting with objects using hands. The video demo, code, and dataset are available on our website: https://joehjhuang.github.io/normalflow.
* 8 pages, published in 2024 RA-L, website link: https://joehjhuang.github.io/normalflow