 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionSense: Bridging Common Sense, Vision, and Touch for Robust Sparse-View Reconstruction
Oct 10, 2024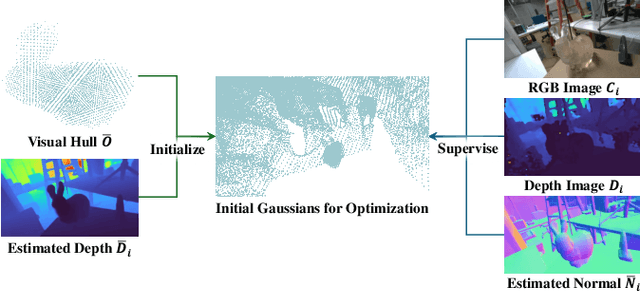


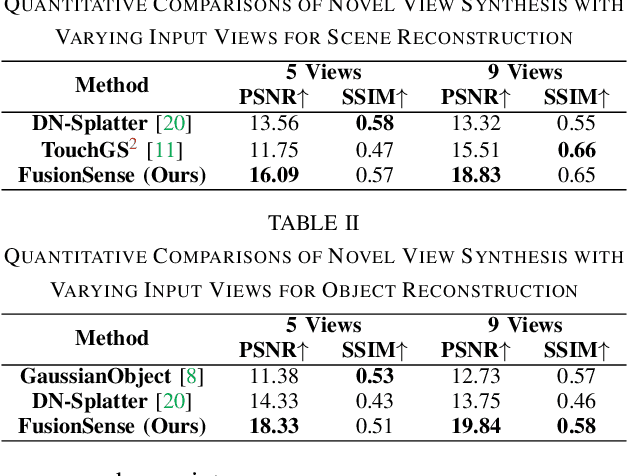
Humans effortlessly integrate common-sense knowledge with sensory input from vision and touch to understand their surroundings. Emulating this capability, we introduce FusionSense, a novel 3D reconstruction framework that enables robots to fuse priors from foundation models with highly sparse observations from vision and tactile sensors. FusionSense addresses three key challenges: (i) How can robots efficiently acquire robust global shape information about the surrounding scene and objects? (ii) How can robots strategically select touch points on the object using geometric and common-sense priors? (iii) How can partial observations such as tactile signals improve the overall representation of the object? Our framework employs 3D Gaussian Splatting as a core representation and incorporates a hierarchical optimization strategy involving global structure construction, object visual hull pruning and local geometric constraints. This advancement results in fast and robust perception in environments with traditionally challenging objects that are transparent, reflective, or dark, enabling more downstream manipulation or navigation tasks. Experiments on real-world data suggest that our framework outperforms previously state-of-the-art sparse-view methods. All code and data are open-sourced on the project website.
LUWA Dataset: Learning Lithic Use-Wear Analysis on Microscopic Images
Mar 27, 2024



Lithic Use-Wear Analysis (LUWA) using microscopic images is an underexplored vision-for-science research area. It seeks to distinguish the worked material, which is critical for understanding archaeological artifacts, material interactions, tool functionalities, and dental records. However, this challenging task goes beyond the well-studied image classification problem for common objects. It is affected by many confounders owing to the complex wear mechanism and microscopic imaging, which makes it difficult even for human experts to identify the worked material successfully. In this paper, we investigate the following three questions on this unique vision task for the first time:(i) How well can state-of-the-art pre-trained models (like DINOv2) generalize to the rarely seen domain? (ii) How can few-shot learning be exploited for scarce microscopic images? (iii) How do the ambiguous magnification and sensing modality influence the classification accuracy? To study these, we collaborated with archaeologists and built the first open-source and the largest LUWA dataset containing 23,130 microscopic images with different magnifications and sensing modalities. Extensive experiments show that existing pre-trained models notably outperform human experts but still leave a large gap for improvements. Most importantly, the LUWA dataset provides an underexplored opportunity for vision and learning communities and complements existing image classification problems on common objects.
Toward Zero-Shot Sim-to-Real Transfer Learning for Pneumatic Soft Robot 3D Proprioceptive Sensing
Mar 08, 2023



Pneumatic soft robots present many advantages in manipulation tasks. Notably, their inherent compliance makes them safe and reliable in unstructured and fragile environments. However, full-body shape sensing for pneumatic soft robots is challenging because of their high degrees of freedom and complex deformation behaviors. Vision-based proprioception sensing methods relying on embedded cameras and deep learning provide a good solution to proprioception sensing by extracting the full-body shape information from the high-dimensional sensing data. But the current training data collection process makes it difficult for many applications. To address this challenge, we propose and demonstrate a robust sim-to-real pipeline that allows the collection of the soft robot's shape information in high-fidelity point cloud representation. The model trained on simulated data was evaluated with real internal camera images. The results show that the model performed with averaged Chamfer distance of 8.85 mm and tip position error of 10.12 mm even with external perturbation for a pneumatic soft robot with a length of 100.0 mm. We also demonstrated the sim-to-real pipeline's potential for exploring different configurations of visual patterns to improve vision-based reconstruction results. The code and dataset are available at https://github.com/DeepSoRo/DeepSoRoSim2Real.