 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarthVL: A Progressive Earth Vision-Language Understanding and Generation Framework
Jan 06, 2026Earth vision has achieved milestones in geospatial object recognition but lacks exploration in object-relational reasoning, limiting comprehensive scene understanding. To address this, a progressive Earth vision-language understanding and generation framework is proposed, including a multi-task dataset (EarthVLSet) and a semantic-guided network (EarthVLNet). Focusing on city planning applications, EarthVLSet includes 10.9k sub-meter resolution remote sensing images, land-cover masks, and 761.5k textual pairs involving both multiple-choice and open-ended visual question answering (VQA) tasks. In an object-centric way, EarthVLNet is proposed to progressively achieve semantic segmentation, relational reasoning, and comprehensive understanding. The first stage involves land-cover segmentation to generate object semantics for VQA guidance. Guided by pixel-wise semantics, the object awareness based large language model (LLM) performs relational reasoning and knowledge summarization to generate the required answers. As for optimization, the numerical difference loss is proposed to dynamically add difference penalties, addressing the various objects' statistics. Three benchmarks, including semantic segmentation, multiple-choice, and open-ended VQA demonstrated the superiorities of EarthVLNet, yielding three future directions: 1) segmentation features consistently enhance VQA performance even in cross-dataset scenarios; 2) multiple-choice tasks show greater sensitivity to the vision encoder than to the language decoder; and 3) open-ended tasks necessitate advanced vision encoders and language decoders for an optimal performance. We believe this dataset and method will provide a beneficial benchmark that connects ''image-mask-text'', advancing geographical applications for Earth vision.
Toward Global Large Language Models in Medicine
Jan 05, 2026Despite continuous advances in medical technology, the global distribution of health care resources remains uneven. The development of large language models (LLMs) has transformed the landscape of medicine and holds promise for improving health care quality and expanding access to medical information globally. However, existing LLMs are primarily trained on high-resource languages, limiting their applicability in global medical scenarios. To address this gap, we constructed GlobMed, a large multilingual medical dataset, containing over 500,000 entries spanning 12 languages, including four low-resource languages. Building on this, we established GlobMed-Bench, which systematically assesses 56 state-of-the-art proprietary and open-weight LLMs across multiple multilingual medical tasks, revealing significant performance disparities across languages, particularly for low-resource languages. Additionally, we introduced GlobMed-LLMs, a suite of multilingual medical LLMs trained on GlobMed, with parameters ranging from 1.7B to 8B. GlobMed-LLMs achieved an average performance improvement of over 40% relative to baseline models, with a more than threefold increase in performance on low-resource languages. Together, these resources provide an important foundation for advancing the equitable development and application of LLMs globally, enabling broader language communities to benefit from technological advances.
Advancing Weakly-Supervised Change Detection in Satellite Images via Adversarial Class Prompting
Aug 24, 2025


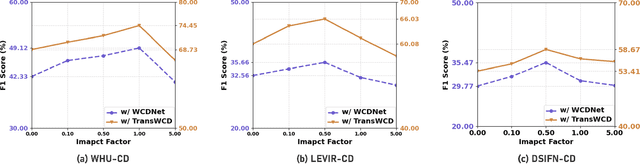
Weakly-Supervised Change Detection (WSCD) aims to distinguish specific object changes (e.g., objects appearing or disappearing) from background variations (e.g., environmental changes due to light, weather, or seasonal shifts) in paired satellite images, relying only on paired image (i.e., image-level) classification labels. This technique significantly reduces the need for dense annotations required in fully-supervised change detection. However, as image-level supervision only indicates whether objects have changed in a scene, WSCD methods often misclassify background variations as object changes, especially in complex remote-sensing scenarios. In this work, we propose an Adversarial Class Prompting (AdvCP) method to address this co-occurring noise problem, including two phases: a) Adversarial Prompt Mining: After each training iteration, we introduce adversarial prompting perturbations, using incorrect one-hot image-level labels to activate erroneous feature mappings. This process reveals co-occurring adversarial samples under weak supervision, namely background variation features that are likely to be misclassified as object changes. b) Adversarial Sample Rectification: We integrate these adversarially prompt-activated pixel samples into training by constructing an online global prototype. This prototype is built from an exponentially weighted moving average of the current batch and all historical training data. Our AdvCP can be seamlessly integrated into current WSCD methods without adding additional inference cost. Experiments on ConvNet, Transformer, and Segment Anything Model (SAM)-based baselines demonstrate significant performance enhancements. Furthermore, we demonstrate the generalizability of AdvCP to other multi-class weakly-supervised dense prediction scenarios. Code is available at https://github.com/zhenghuizhao/AdvCP
DynamicVL: Benchmarking Multimodal Large Language Models for Dynamic City Understanding
May 27, 2025Multimodal large language models have demonstrated remarkable capabilities in visual understanding, but their application to long-term Earth observation analysis remains limited, primarily focusing on single-temporal or bi-temporal imagery. To address this gap, we introduce DVL-Suite, a comprehensive framework for analyzing long-term urban dynamics through remote sensing imagery. Our suite comprises 15,063 high-resolution (1.0m) multi-temporal images spanning 42 megacities in the U.S. from 2005 to 2023, organized into two components: DVL-Bench and DVL-Instruct. The DVL-Bench includes seven urban understanding tasks, from fundamental change detection (pixel-level) to quantitative analyses (regional-level) and comprehensive urban narratives (scene-level), capturing diverse urban dynamics including expansion/transformation patterns, disaster assessment, and environmental challenges. We evaluate 17 state-of-the-art multimodal large language models and reveal their limitations in long-term temporal understanding and quantitative analysis. These challenges motivate the creation of DVL-Instruct, a specialized instruction-tuning dataset designed to enhance models' capabilities in multi-temporal Earth observation. Building upon this dataset, we develop DVLChat, a baseline model capable of both image-level question-answering and pixel-level segmentation, facilitating a comprehensive understanding of city dynamics through language interactions.
DisasterM3: A Remote Sensing Vision-Language Dataset for Disaster Damage Assessment and Response
May 27, 2025Large vision-language models (VLMs) have made great achievements in Earth vision. However, complex disaster scenes with diverse disaster types, geographic regions, and satellite sensors have posed new challenges for VLM applications. To fill this gap, we curate a remote sensing vision-language dataset (DisasterM3) for global-scale disaster assessment and response. DisasterM3 includes 26,988 bi-temporal satellite images and 123k instruction pairs across 5 continents, with three characteristics: 1) Multi-hazard: DisasterM3 involves 36 historical disaster events with significant impacts, which are categorized into 10 common natural and man-made disasters. 2)Multi-sensor: Extreme weather during disasters often hinders optical sensor imaging, making it necessary to combine Synthetic Aperture Radar (SAR) imagery for post-disaster scenes. 3) Multi-task: Based on real-world scenarios, DisasterM3 includes 9 disaster-related visual perception and reasoning tasks, harnessing the full potential of VLM's reasoning ability with progressing from disaster-bearing body recognition to structural damage assessment and object relational reasoning, culminating in the generation of long-form disaster reports. We extensively evaluated 14 generic and remote sensing VLMs on our benchmark, revealing that state-of-the-art models struggle with the disaster tasks, largely due to the lack of a disaster-specific corpus, cross-sensor gap, and damage object counting insensitivity. Focusing on these issues, we fine-tune four VLMs using our dataset and achieve stable improvements across all tasks, with robust cross-sensor and cross-disaster generalization capabilities.
HOpenCls: Training Hyperspectral Image Open-Set Classifiers in Their Living Environments
Feb 21, 2025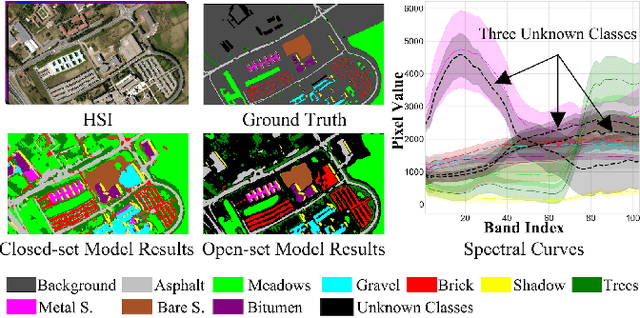
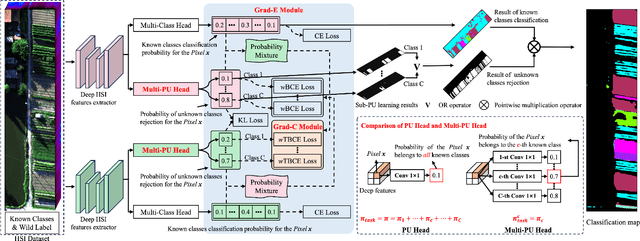
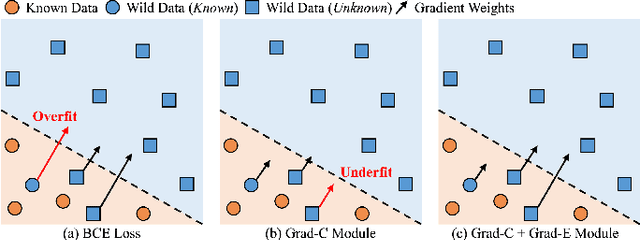

Hyperspectral image (HSI) open-set classification is critical for HSI classification models deployed in real-world environments, where classifiers must simultaneously classify known classes and reject unknown classes. Recent methods utilize auxiliary unknown classes data to improve classification performance. However, the auxiliary unknown classes data is strongly assumed to be completely separable from known classes and requires labor-intensive annotation. To address this limitation, this paper proposes a novel framework, HOpenCls, to leverage the unlabeled wild data-that is the mixture of known and unknown classes. Such wild data is abundant and can be collected freely during deploying classifiers in their living environments. The key insight is reformulating the open-set HSI classification with unlabeled wild data as a positive-unlabeled (PU) learning problem. Specifically, the multi-label strategy is introduced to bridge the PU learning and open-set HSI classification, and then the proposed gradient contraction and gradient expansion module to make this PU learning problem tractable from the observation of abnormal gradient weights associated with wild data. Extensive experiment results demonstrate that incorporating wild data has the potential to significantly enhance open-set HSI classification in complex real-world scenarios.
TEOChat: A Large Vision-Language Assistant for Temporal Earth Observation Data
Oct 08, 2024Large vision and language assistants have enabled new capabilities for interpreting natural images. These approaches have recently been adapted to earth observation data, but they are only able to handle single image inputs, limiting their use for many real-world tasks. In this work, we develop a new vision and language assistant called TEOChat that can engage in conversations about temporal sequences of earth observation data. To train TEOChat, we curate an instruction-following dataset composed of many single image and temporal tasks including building change and damage assessment, semantic change detection, and temporal scene classification. We show that TEOChat can perform a wide variety of spatial and temporal reasoning tasks, substantially outperforming previous vision and language assistants, and even achieving comparable or better performance than specialist models trained to perform these specific tasks. Furthermore, TEOChat achieves impressive zero-shot performance on a change detection and change question answering dataset, outperforms GPT-4o and Gemini 1.5 Pro on multiple temporal tasks, and exhibits stronger single image capabilities than a comparable single EO image instruction-following model. We publicly release our data, models, and code at https://github.com/ermongroup/TEOChat .
Open-CD: A Comprehensive Toolbox for Change Detection
Jul 22, 2024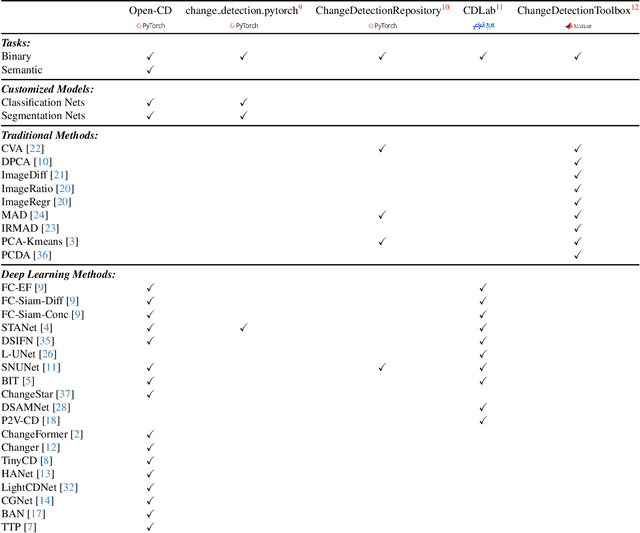
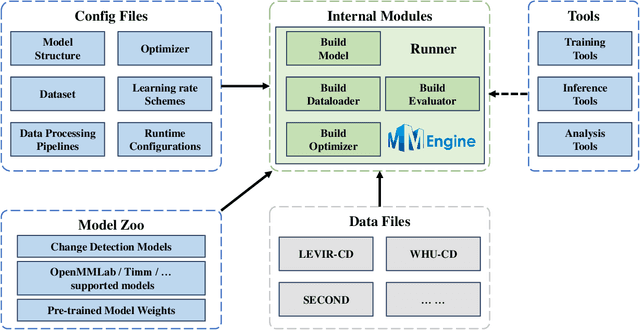
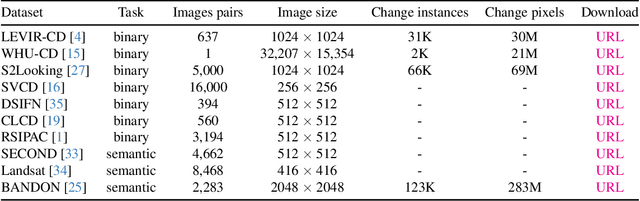
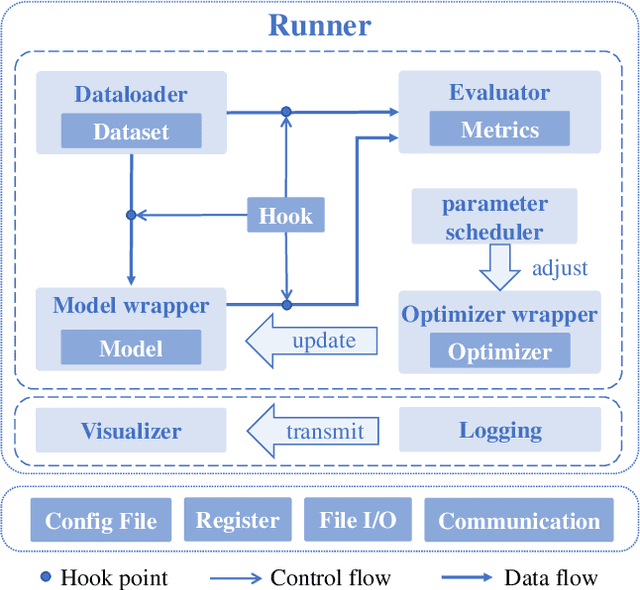
We present Open-CD, a change detection toolbox that contains a rich set of change detection methods as well as related components and modules. The toolbox started from a series of open source general vision task tools, including OpenMMLab Toolkits, PyTorch Image Models, etc. It gradually evolves into a unified platform that covers many popular change detection methods and contemporary modules. It not only includes training and inference codes, but also provides some useful scripts for data analysis. We believe this toolbox is by far the most complete change detection toolbox. In this report, we introduce the various features, supported methods and applications of Open-CD. In addition, we also conduct a benchmarking study on different methods and components. We wish that the toolbox and benchmark could serve the growing research community by providing a flexible toolkit to reimplement existing methods and develop their own new change detectors. Code and models are available at \url{https://github.com/likyoo/open-cd}. Pioneeringly, this report also includes brief descriptions of the algorithms supported in Open-CD, mainly contributed by their authors. We sincerely encourage researchers in this field to participate in this project and work together to create a more open community. This toolkit and report will be kept updated.
Changen2: Multi-Temporal Remote Sensing Generative Change Foundation Model
Jun 26, 2024

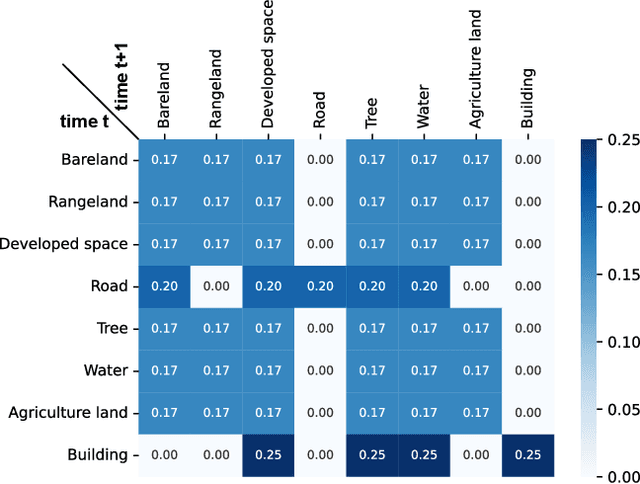
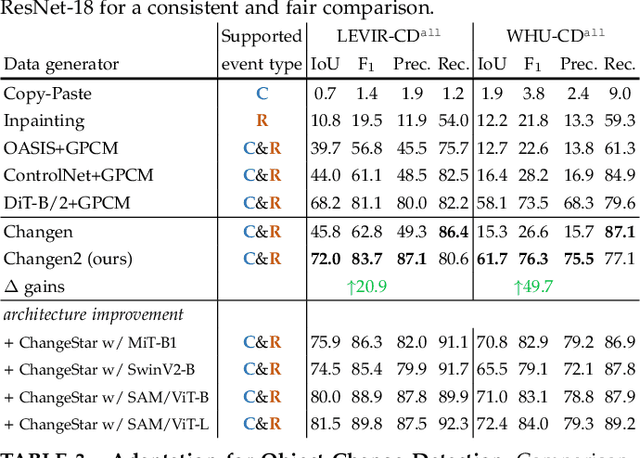
Our understanding of the temporal dynamics of the Earth's surface has been advanced by deep vision models, which often require lots of labeled multi-temporal images for training. However, collecting, preprocessing, and annotating multi-temporal remote sensing images at scale is non-trivial since it is expensive and knowledge-intensive. In this paper, we present change data generators based on generative models, which are cheap and automatic, alleviating these data problems. Our main idea is to simulate a stochastic change process over time. We describe the stochastic change process as a probabilistic graphical model (GPCM), which factorizes the complex simulation problem into two more tractable sub-problems, i.e., change event simulation and semantic change synthesis. To solve these two problems, we present Changen2, a GPCM with a resolution-scalable diffusion transformer which can generate time series of images and their semantic and change labels from labeled or unlabeled single-temporal images. Changen2 is a generative change foundation model that can be trained at scale via self-supervision, and can produce change supervisory signals from unlabeled single-temporal images. Unlike existing foundation models, Changen2 synthesizes change data to train task-specific foundation models for change detection. The resulting model possesses inherent zero-shot change detection capabilities and excellent transferability. Experiments suggest Changen2 has superior spatiotemporal scalability, e.g., Changen2 model trained on 256$^2$ pixel single-temporal images can yield time series of any length and resolutions of 1,024$^2$ pixels. Changen2 pre-trained models exhibit superior zero-shot performance (narrowing the performance gap to 3% on LEVIR-CD and approximately 10% on both S2Looking and SECOND, compared to fully supervised counterparts) and transferability across multiple types of change tasks.
Single-Temporal Supervised Learning for Universal Remote Sensing Change Detection
Jun 22, 2024Bitemporal supervised learning paradigm always dominates remote sensing change detection using numerous labeled bitemporal image pairs, especially for high spatial resolution (HSR) remote sensing imagery. However, it is very expensive and labor-intensive to label change regions in large-scale bitemporal HSR remote sensing image pairs. In this paper, we propose single-temporal supervised learning (STAR) for universal remote sensing change detection from a new perspective of exploiting changes between unpaired images as supervisory signals. STAR enables us to train a high-accuracy change detector only using unpaired labeled images and can generalize to real-world bitemporal image pairs. To demonstrate the flexibility and scalability of STAR, we design a simple yet unified change detector, termed ChangeStar2, capable of addressing binary change detection, object change detection, and semantic change detection in one architecture. ChangeStar2 achieves state-of-the-art performances on eight public remote sensing change detection datasets, covering above two supervised settings, multiple change types, multiple scenarios. The code is available at https://github.com/Z-Zheng/pytorch-change-models.