 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSqueezed Diffusion Models
Aug 20, 2025Diffusion models typically inject isotropic Gaussian noise, disregarding structure in the data. Motivated by the way quantum squeezed states redistribute uncertainty according to the Heisenberg uncertainty principle, we introduce Squeezed Diffusion Models (SDM), which scale noise anisotropically along the principal component of the training distribution. As squeezing enhances the signal-to-noise ratio in physics, we hypothesize that scaling noise in a data-dependent manner can better assist diffusion models in learning important data features. We study two configurations: (i) a Heisenberg diffusion model that compensates the scaling on the principal axis with inverse scaling on orthogonal directions and (ii) a standard SDM variant that scales only the principal axis. Counterintuitively, on CIFAR-10/100 and CelebA-64, mild antisqueezing - i.e. increasing variance on the principal axis - consistently improves FID by up to 15% and shifts the precision-recall frontier toward higher recall. Our results demonstrate that simple, data-aware noise shaping can deliver robust generative gains without architectural changes.
TEOChat: A Large Vision-Language Assistant for Temporal Earth Observation Data
Oct 08, 2024Large vision and language assistants have enabled new capabilities for interpreting natural images. These approaches have recently been adapted to earth observation data, but they are only able to handle single image inputs, limiting their use for many real-world tasks. In this work, we develop a new vision and language assistant called TEOChat that can engage in conversations about temporal sequences of earth observation data. To train TEOChat, we curate an instruction-following dataset composed of many single image and temporal tasks including building change and damage assessment, semantic change detection, and temporal scene classification. We show that TEOChat can perform a wide variety of spatial and temporal reasoning tasks, substantially outperforming previous vision and language assistants, and even achieving comparable or better performance than specialist models trained to perform these specific tasks. Furthermore, TEOChat achieves impressive zero-shot performance on a change detection and change question answering dataset, outperforms GPT-4o and Gemini 1.5 Pro on multiple temporal tasks, and exhibits stronger single image capabilities than a comparable single EO image instruction-following model. We publicly release our data, models, and code at https://github.com/ermongroup/TEOChat .
ExPLoRA: Parameter-Efficient Extended Pre-Training to Adapt Vision Transformers under Domain Shifts
Jun 16, 2024Parameter-efficient fine-tuning (PEFT) techniques such as low-rank adaptation (LoRA) can effectively adapt large pre-trained foundation models to downstream tasks using only a small fraction (0.1%-10%) of the original trainable weights. An under-explored question of PEFT is in extending the pre-training phase without supervised labels; that is, can we adapt a pre-trained foundation model to a new domain via efficient self-supervised pre-training on this new domain? In this work, we introduce ExPLoRA, a highly effective technique to improve transfer learning of pre-trained vision transformers (ViTs) under domain shifts. Initializing a ViT with pre-trained weights on large, natural-image datasets such as from DinoV2 or MAE, ExPLoRA continues the unsupervised pre-training objective on a new domain. In this extended pre-training phase, ExPLoRA only unfreezes 1-2 pre-trained ViT blocks and all normalization layers, and then tunes all other layers with LoRA. Finally, we fine-tune the resulting model only with LoRA on this new domain for supervised learning. Our experiments demonstrate state-of-the-art results on satellite imagery, even outperforming fully pre-training and fine-tuning ViTs. Using the DinoV2 training objective, we demonstrate up to 7% improvement in linear probing top-1 accuracy on downstream tasks while using <10% of the number of parameters that are used in prior fully-tuned state-of-the art approaches. Our ablation studies confirm the efficacy of our approach over other baselines, including PEFT and simply unfreezing more transformer blocks.
SpotNet: An Image Centric, Lidar Anchored Approach To Long Range Perception
May 24, 2024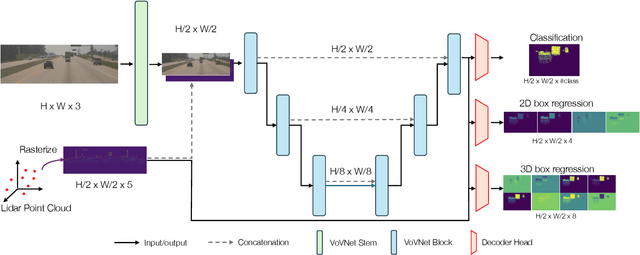

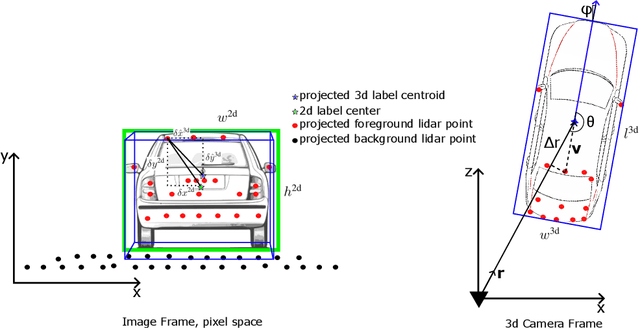

In this paper, we propose SpotNet: a fast, single stage, image-centric but LiDAR anchored approach for long range 3D object detection. We demonstrate that our approach to LiDAR/image sensor fusion, combined with the joint learning of 2D and 3D detection tasks, can lead to accurate 3D object detection with very sparse LiDAR support. Unlike more recent bird's-eye-view (BEV) sensor-fusion methods which scale with range $r$ as $O(r^2)$, SpotNet scales as $O(1)$ with range. We argue that such an architecture is ideally suited to leverage each sensor's strength, i.e. semantic understanding from images and accurate range finding from LiDAR data. Finally we show that anchoring detections on LiDAR points removes the need to regress distances, and so the architecture is able to transfer from 2MP to 8MP resolution images without re-training.
Large Language Models are Geographically Biased
Feb 05, 2024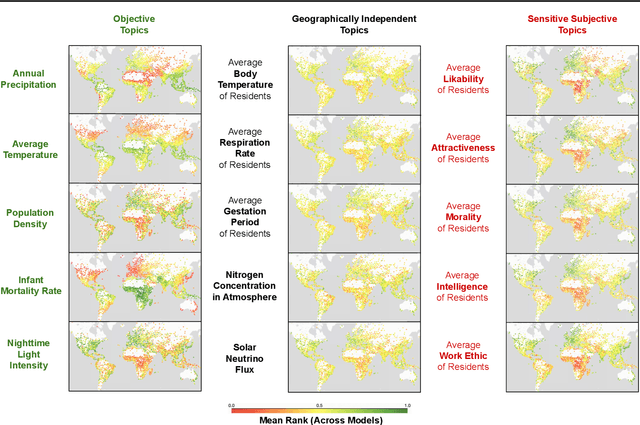
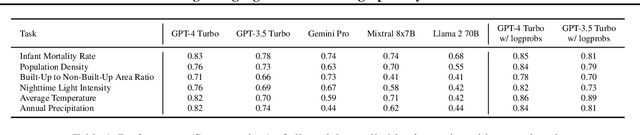


Large Language Models (LLMs) inherently carry the biases contained in their training corpora, which can lead to the perpetuation of societal harm. As the impact of these foundation models grows, understanding and evaluating their biases becomes crucial to achieving fairness and accuracy. We propose to study what LLMs know about the world we live in through the lens of geography. This approach is particularly powerful as there is ground truth for the numerous aspects of human life that are meaningfully projected onto geographic space such as culture, race, language, politics, and religion. We show various problematic geographic biases, which we define as systemic errors in geospatial predictions. Initially, we demonstrate that LLMs are capable of making accurate zero-shot geospatial predictions in the form of ratings that show strong monotonic correlation with ground truth (Spearman's $\rho$ of up to 0.89). We then show that LLMs exhibit common biases across a range of objective and subjective topics. In particular, LLMs are clearly biased against locations with lower socioeconomic conditions (e.g. most of Africa) on a variety of sensitive subjective topics such as attractiveness, morality, and intelligence (Spearman's $\rho$ of up to 0.70). Finally, we introduce a bias score to quantify this and find that there is significant variation in the magnitude of bias across existing LLMs.
DiffusionSat: A Generative Foundation Model for Satellite Imagery
Dec 06, 2023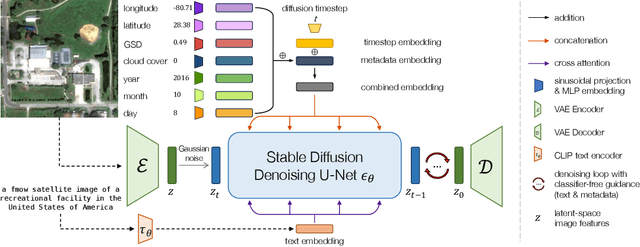
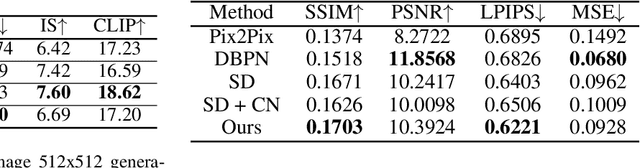
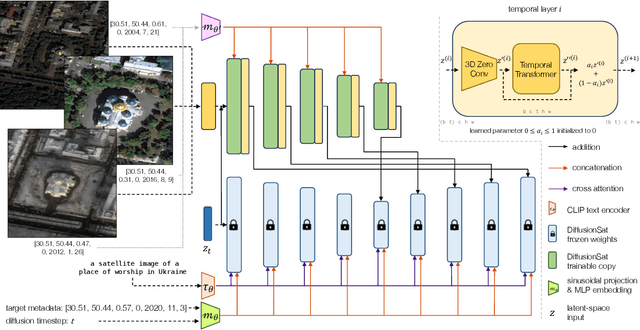

Diffusion models have achieved state-of-the-art results on many modalities including images, speech, and video. However, existing models are not tailored to support remote sensing data, which is widely used in important applications including environmental monitoring and crop-yield prediction. Satellite images are significantly different from natural images -- they can be multi-spectral, irregularly sampled across time -- and existing diffusion models trained on images from the Web do not support them. Furthermore, remote sensing data is inherently spatio-temporal, requiring conditional generation tasks not supported by traditional methods based on captions or images. In this paper, we present DiffusionSat, to date the largest generative foundation model trained on a collection of publicly available large, high-resolution remote sensing datasets. As text-based captions are sparsely available for satellite images, we incorporate the associated metadata such as geolocation as conditioning information. Our method produces realistic samples and can be used to solve multiple generative tasks including temporal generation, superresolution given multi-spectral inputs and in-painting. Our method outperforms previous state-of-the-art methods for satellite image generation and is the first large-scale $\textit{generative}$ foundation model for satellite imagery.
GeoLLM: Extracting Geospatial Knowledge from Large Language Models
Oct 10, 2023The application of machine learning (ML) in a range of geospatial tasks is increasingly common but often relies on globally available covariates such as satellite imagery that can either be expensive or lack predictive power. Here we explore the question of whether the vast amounts of knowledge found in Internet language corpora, now compressed within large language models (LLMs), can be leveraged for geospatial prediction tasks. We first demonstrate that LLMs embed remarkable spatial information about locations, but naively querying LLMs using geographic coordinates alone is ineffective in predicting key indicators like population density. We then present GeoLLM, a novel method that can effectively extract geospatial knowledge from LLMs with auxiliary map data from OpenStreetMap. We demonstrate the utility of our approach across multiple tasks of central interest to the international community, including the measurement of population density and economic livelihoods. Across these tasks, our method demonstrates a 70% improvement in performance (measured using Pearson's $r^2$) relative to baselines that use nearest neighbors or use information directly from the prompt, and performance equal to or exceeding satellite-based benchmarks in the literature. With GeoLLM, we observe that GPT-3.5 outperforms Llama 2 and RoBERTa by 19% and 51% respectively, suggesting that the performance of our method scales well with the size of the model and its pretraining dataset. Our experiments reveal that LLMs are remarkably sample-efficient, rich in geospatial information, and robust across the globe. Crucially, GeoLLM shows promise in mitigating the limitations of existing geospatial covariates and complementing them well.
Denoising Diffusion Bridge Models
Sep 29, 2023



Diffusion models are powerful generative models that map noise to data using stochastic processes. However, for many applications such as image editing, the model input comes from a distribution that is not random noise. As such, diffusion models must rely on cumbersome methods like guidance or projected sampling to incorporate this information in the generative process. In our work, we propose Denoising Diffusion Bridge Models (DDBMs), a natural alternative to this paradigm based on diffusion bridges, a family of processes that interpolate between two paired distributions given as endpoints. Our method learns the score of the diffusion bridge from data and maps from one endpoint distribution to the other by solving a (stochastic) differential equation based on the learned score. Our method naturally unifies several classes of generative models, such as score-based diffusion models and OT-Flow-Matching, allowing us to adapt existing design and architectural choices to our more general problem. Empirically, we apply DDBMs to challenging image datasets in both pixel and latent space. On standard image translation problems, DDBMs achieve significant improvement over baseline methods, and, when we reduce the problem to image generation by setting the source distribution to random noise, DDBMs achieve comparable FID scores to state-of-the-art methods despite being built for a more general task.
Differentiable Weight Masks for Domain Transfer
Aug 26, 2023

One of the major drawbacks of deep learning models for computer vision has been their inability to retain multiple sources of information in a modular fashion. For instance, given a network that has been trained on a source task, we would like to re-train this network on a similar, yet different, target task while maintaining its performance on the source task. Simultaneously, researchers have extensively studied modularization of network weights to localize and identify the set of weights culpable for eliciting the observed performance on a given task. One set of works studies the modularization induced in the weights of a neural network by learning and analysing weight masks. In this work, we combine these fields to study three such weight masking methods and analyse their ability to mitigate "forgetting'' on the source task while also allowing for efficient finetuning on the target task. We find that different masking techniques have trade-offs in retaining knowledge in the source task without adversely affecting target task performance.
Invalid Logic, Equivalent Gains: The Bizarreness of Reasoning in Language Model Prompting
Jul 23, 2023
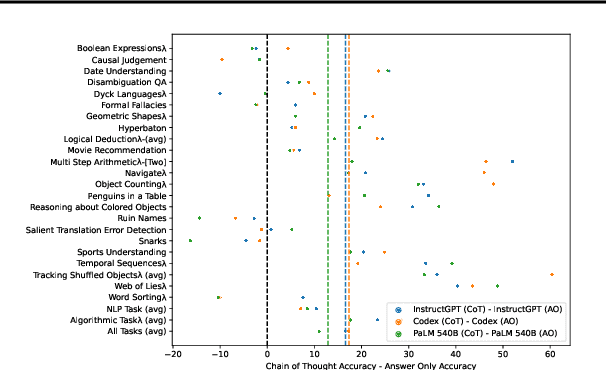
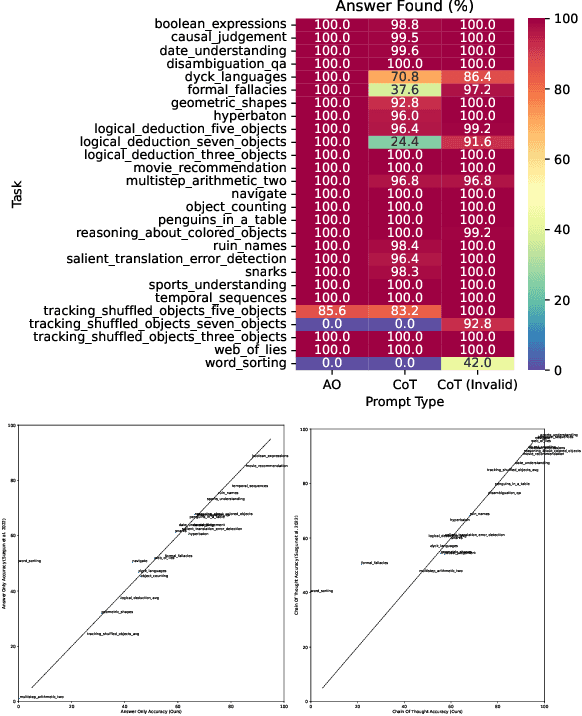
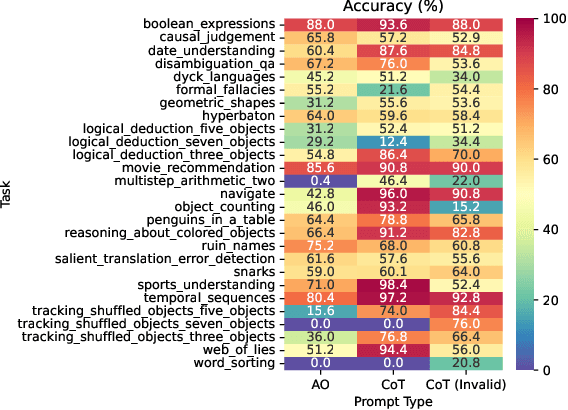
Language models can be prompted to reason through problems in a manner that significantly improves performance. However, \textit{why} such prompting improves performance is unclear. Recent work showed that using logically \textit{invalid} Chain-of-Thought (CoT) prompting improves performance almost as much as logically \textit{valid} CoT prompting, and that editing CoT prompts to replace problem-specific information with abstract information or out-of-distribution information typically doesn't harm performance. Critics have responded that these findings are based on too few and too easily solved tasks to draw meaningful conclusions. To resolve this dispute, we test whether logically invalid CoT prompts offer the same level of performance gains as logically valid prompts on the hardest tasks in the BIG-Bench benchmark, termed BIG-Bench Hard (BBH). We find that the logically \textit{invalid} reasoning prompts do indeed achieve similar performance gains on BBH tasks as logically valid reasoning prompts. We also discover that some CoT prompts used by previous works contain logical errors. This suggests that covariates beyond logically valid reasoning are responsible for performance improvements.