 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvalid Logic, Equivalent Gains: The Bizarreness of Reasoning in Language Model Prompting
Paper and Code
Jul 23, 2023
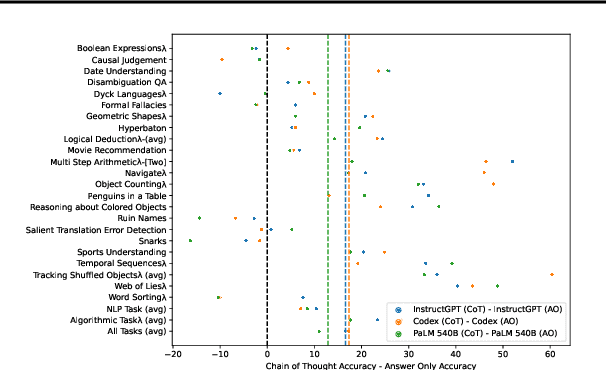
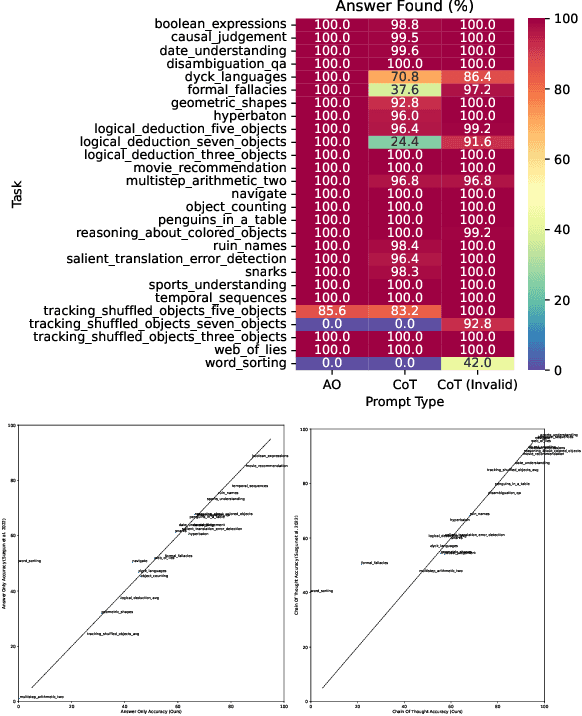
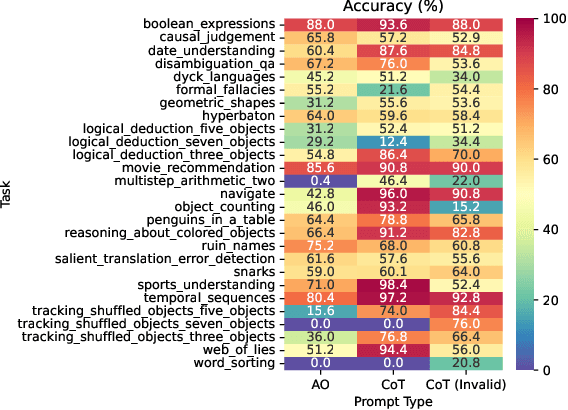
Language models can be prompted to reason through problems in a manner that significantly improves performance. However, \textit{why} such prompting improves performance is unclear. Recent work showed that using logically \textit{invalid} Chain-of-Thought (CoT) prompting improves performance almost as much as logically \textit{valid} CoT prompting, and that editing CoT prompts to replace problem-specific information with abstract information or out-of-distribution information typically doesn't harm performance. Critics have responded that these findings are based on too few and too easily solved tasks to draw meaningful conclusions. To resolve this dispute, we test whether logically invalid CoT prompts offer the same level of performance gains as logically valid prompts on the hardest tasks in the BIG-Bench benchmark, termed BIG-Bench Hard (BBH). We find that the logically \textit{invalid} reasoning prompts do indeed achieve similar performance gains on BBH tasks as logically valid reasoning prompts. We also discover that some CoT prompts used by previous works contain logical errors. This suggests that covariates beyond logically valid reasoning are responsible for performance improvements.