 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Inference-Time Compute: LLMs Can Predict if They Can Do Better, Even Mid-Generation
Oct 03, 2024Inference-time computation is a powerful paradigm to enhance the performance of large language models (LLMs), with Best-of-N sampling being a widely used technique. However, this method is computationally expensive, requiring both (1) an external reward model and (2) the generation of multiple samples. In this work, we introduce a new generative self-evaluation scheme designed to adaptively reduce the number of generated samples while maintaining or even improving performance. We use a generative reward model formulation, allowing the LLM to predict mid-generation the probability that restarting the generation will yield a better response. These predictions are obtained without an external reward model and can be used to decide whether or not to generate more samples, prune unpromising samples early on, or to pick the best sample. This capability is very inexpensive as it involves generating a single predefined token. Trained using a dataset constructed with real unfiltered LMSYS user prompts, Llama 3.1 8B's win rate against GPT-4 on AlpacaEval increases from 21% to 34% with 16 samples and math performance on GSM8K improves from 84% to 91%. By sampling only when the LLM determines that it is beneficial to do so and adaptively adjusting temperature annealing, we demonstrate that 74% of the improvement from using 16 samples can be achieved with only 1.2 samples on average. We further demonstrate that 50-75% of samples can be pruned early in generation with minimal degradation in performance. Overall, our methods enable more efficient and scalable compute utilization during inference for LLMs.
Large Language Models are Geographically Biased
Feb 05, 2024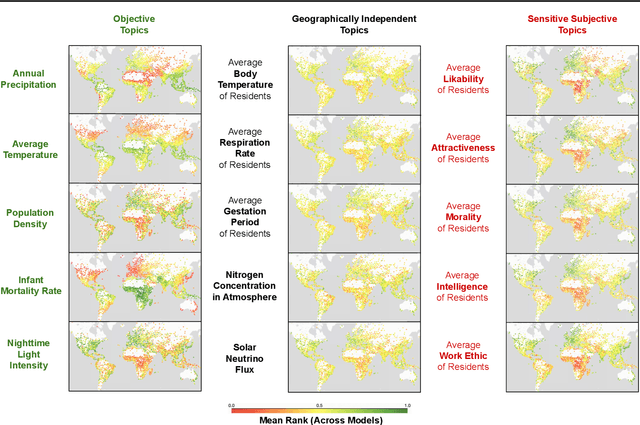


Large Language Models (LLMs) inherently carry the biases contained in their training corpora, which can lead to the perpetuation of societal harm. As the impact of these foundation models grows, understanding and evaluating their biases becomes crucial to achieving fairness and accuracy. We propose to study what LLMs know about the world we live in through the lens of geography. This approach is particularly powerful as there is ground truth for the numerous aspects of human life that are meaningfully projected onto geographic space such as culture, race, language, politics, and religion. We show various problematic geographic biases, which we define as systemic errors in geospatial predictions. Initially, we demonstrate that LLMs are capable of making accurate zero-shot geospatial predictions in the form of ratings that show strong monotonic correlation with ground truth (Spearman's $\rho$ of up to 0.89). We then show that LLMs exhibit common biases across a range of objective and subjective topics. In particular, LLMs are clearly biased against locations with lower socioeconomic conditions (e.g. most of Africa) on a variety of sensitive subjective topics such as attractiveness, morality, and intelligence (Spearman's $\rho$ of up to 0.70). Finally, we introduce a bias score to quantify this and find that there is significant variation in the magnitude of bias across existing LLMs.
GeoLLM: Extracting Geospatial Knowledge from Large Language Models
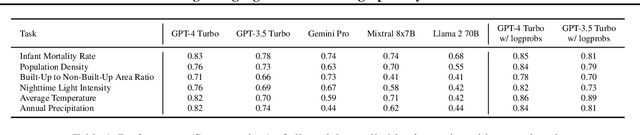
Oct 10, 2023The application of machine learning (ML) in a range of geospatial tasks is increasingly common but often relies on globally available covariates such as satellite imagery that can either be expensive or lack predictive power. Here we explore the question of whether the vast amounts of knowledge found in Internet language corpora, now compressed within large language models (LLMs), can be leveraged for geospatial prediction tasks. We first demonstrate that LLMs embed remarkable spatial information about locations, but naively querying LLMs using geographic coordinates alone is ineffective in predicting key indicators like population density. We then present GeoLLM, a novel method that can effectively extract geospatial knowledge from LLMs with auxiliary map data from OpenStreetMap. We demonstrate the utility of our approach across multiple tasks of central interest to the international community, including the measurement of population density and economic livelihoods. Across these tasks, our method demonstrates a 70% improvement in performance (measured using Pearson's $r^2$) relative to baselines that use nearest neighbors or use information directly from the prompt, and performance equal to or exceeding satellite-based benchmarks in the literature. With GeoLLM, we observe that GPT-3.5 outperforms Llama 2 and RoBERTa by 19% and 51% respectively, suggesting that the performance of our method scales well with the size of the model and its pretraining dataset. Our experiments reveal that LLMs are remarkably sample-efficient, rich in geospatial information, and robust across the globe. Crucially, GeoLLM shows promise in mitigating the limitations of existing geospatial covariates and complementing them well.