 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndexRAG: Bridging Facts for Cross-Document Reasoning at Index Time
Mar 17, 2026Multi-hop question answering (QA) requires reasoning across multiple documents, yet existing retrieval-augmented generation (RAG) approaches address this either through graph-based methods requiring additional online processing or iterative multi-step reasoning. We present IndexRAG, a novel approach that shifts cross-document reasoning from online inference to offline indexing. IndexRAG identifies bridge entities shared across documents and generates bridging facts as independently retrievable units, requiring no additional training or fine-tuning. Experiments on three widely-used multi-hop QA benchmarks (HotpotQA, 2WikiMultiHopQA, MuSiQue) show that IndexRAG improves F1 over Naive RAG by 4.6 points on average, while requiring only single-pass retrieval and a single LLM call at inference time. When combined with IRCoT, IndexRAG outperforms all graph-based baselines on average, including HippoRAG and FastGraphRAG, while relying solely on flat retrieval. Our code will be released upon acceptance.
FlashLabs Chroma 1.0: A Real-Time End-to-End Spoken Dialogue Model with Personalized Voice Cloning
Jan 16, 2026Recent end-to-end spoken dialogue systems leverage speech tokenizers and neural audio codecs to enable LLMs to operate directly on discrete speech representations. However, these models often exhibit limited speaker identity preservation, hindering personalized voice interaction. In this work, we present Chroma 1.0, the first open-source, real-time, end-to-end spoken dialogue model that achieves both low-latency interaction and high-fidelity personalized voice cloning. Chroma achieves sub-second end-to-end latency through an interleaved text-audio token schedule (1:2) that supports streaming generation, while maintaining high-quality personalized voice synthesis across multi-turn conversations. Our experimental results demonstrate that Chroma achieves a 10.96% relative improvement in speaker similarity over the human baseline, with a Real-Time Factor (RTF) of 0.43, while maintaining strong reasoning and dialogue capabilities. Our code and models are publicly available at https://github.com/FlashLabs-AI-Corp/FlashLabs-Chroma and https://huggingface.co/FlashLabs/Chroma-4B .
Enhancing Meme Emotion Understanding with Multi-Level Modality Enhancement and Dual-Stage Modal Fusion
Nov 14, 2025With the rapid rise of social media and Internet culture, memes have become a popular medium for expressing emotional tendencies. This has sparked growing interest in Meme Emotion Understanding (MEU), which aims to classify the emotional intent behind memes by leveraging their multimodal contents. While existing efforts have achieved promising results, two major challenges remain: (1) a lack of fine-grained multimodal fusion strategies, and (2) insufficient mining of memes' implicit meanings and background knowledge. To address these challenges, we propose MemoDetector, a novel framework for advancing MEU. First, we introduce a four-step textual enhancement module that utilizes the rich knowledge and reasoning capabilities of Multimodal Large Language Models (MLLMs) to progressively infer and extract implicit and contextual insights from memes. These enhanced texts significantly enrich the original meme contents and provide valuable guidance for downstream classification. Next, we design a dual-stage modal fusion strategy: the first stage performs shallow fusion on raw meme image and text, while the second stage deeply integrates the enhanced visual and textual features. This hierarchical fusion enables the model to better capture nuanced cross-modal emotional cues. Experiments on two datasets, MET-MEME and MOOD, demonstrate that our method consistently outperforms state-of-the-art baselines. Specifically, MemoDetector improves F1 scores by 4.3\% on MET-MEME and 3.4\% on MOOD. Further ablation studies and in-depth analyses validate the effectiveness and robustness of our approach, highlighting its strong potential for advancing MEU. Our code is available at https://github.com/singing-cat/MemoDetector.
Adaptive Context Length Optimization with Low-Frequency Truncation for Multi-Agent Reinforcement Learning
Oct 30, 2025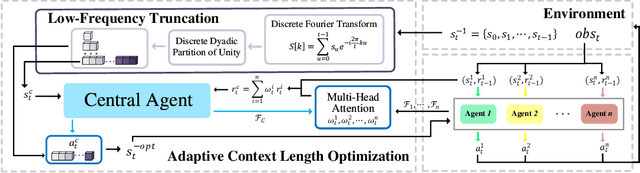
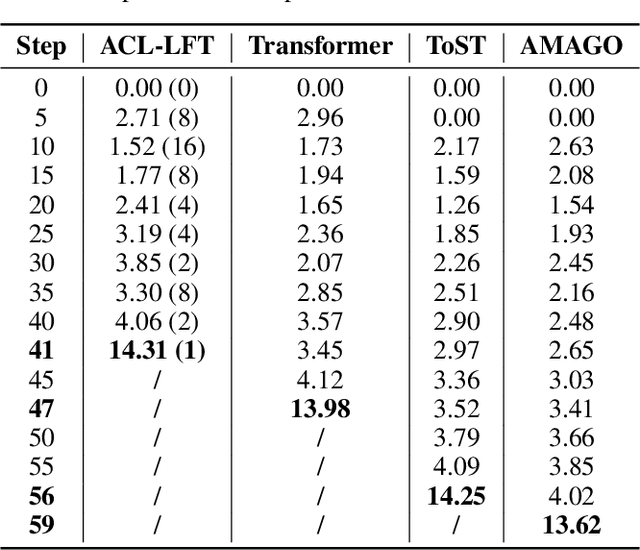
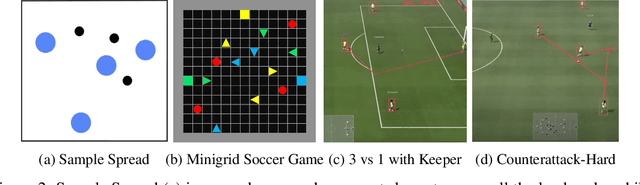
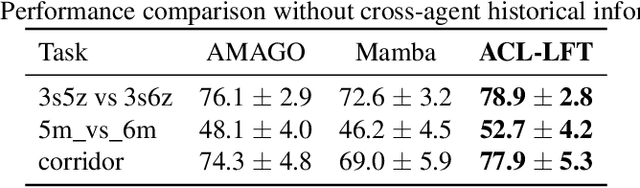
Recently, deep multi-agent reinforcement learning (MARL) has demonstrated promising performance for solving challenging tasks, such as long-term dependencies and non-Markovian environments. Its success is partly attributed to conditioning policies on large fixed context length. However, such large fixed context lengths may lead to limited exploration efficiency and redundant information. In this paper, we propose a novel MARL framework to obtain adaptive and effective contextual information. Specifically, we design a central agent that dynamically optimizes context length via temporal gradient analysis, enhancing exploration to facilitate convergence to global optima in MARL. Furthermore, to enhance the adaptive optimization capability of the context length, we present an efficient input representation for the central agent, which effectively filters redundant information. By leveraging a Fourier-based low-frequency truncation method, we extract global temporal trends across decentralized agents, providing an effective and efficient representation of the MARL environment. Extensive experiments demonstrate that the proposed method achieves state-of-the-art (SOTA) performance on long-term dependency tasks, including PettingZoo, MiniGrid, Google Research Football (GRF), and StarCraft Multi-Agent Challenge v2 (SMACv2).
Demystify Protein Generation with Hierarchical Conditional Diffusion Models
Jul 24, 2025Generating novel and functional protein sequences is critical to a wide range of applications in biology. Recent advancements in conditional diffusion models have shown impressive empirical performance in protein generation tasks. However, reliable generations of protein remain an open research question in de novo protein design, especially when it comes to conditional diffusion models. Considering the biological function of a protein is determined by multi-level structures, we propose a novel multi-level conditional diffusion model that integrates both sequence-based and structure-based information for efficient end-to-end protein design guided by specified functions. By generating representations at different levels simultaneously, our framework can effectively model the inherent hierarchical relations between different levels, resulting in an informative and discriminative representation of the generated protein. We also propose a Protein-MMD, a new reliable evaluation metric, to evaluate the quality of generated protein with conditional diffusion models. Our new metric is able to capture both distributional and functional similarities between real and generated protein sequences while ensuring conditional consistency. We experiment with the benchmark datasets, and the results on conditional protein generation tasks demonstrate the efficacy of the proposed generation framework and evaluation metric.
NeurNCD: Novel Class Discovery via Implicit Neural Representation
Jun 06, 2025
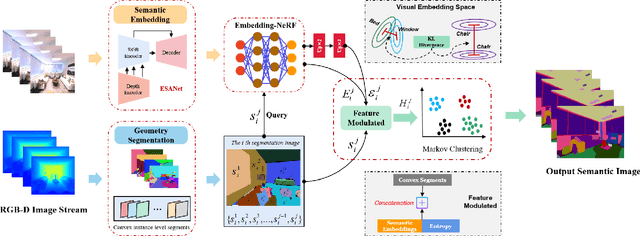
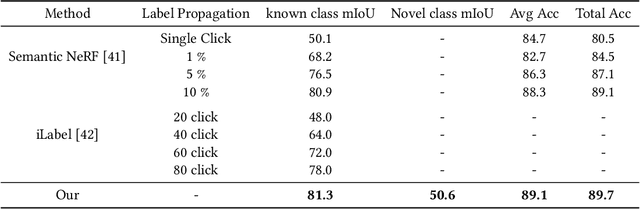

Discovering novel classes in open-world settings is crucial for real-world applications. Traditional explicit representations, such as object descriptors or 3D segmentation maps, are constrained by their discrete, hole-prone, and noisy nature, which hinders accurate novel class discovery. To address these challenges, we introduce NeurNCD, the first versatile and data-efficient framework for novel class discovery that employs the meticulously designed Embedding-NeRF model combined with KL divergence as a substitute for traditional explicit 3D segmentation maps to aggregate semantic embedding and entropy in visual embedding space. NeurNCD also integrates several key components, including feature query, feature modulation and clustering, facilitating efficient feature augmentation and information exchange between the pre-trained semantic segmentation network and implicit neural representations. As a result, our framework achieves superior segmentation performance in both open and closed-world settings without relying on densely labelled datasets for supervised training or human interaction to generate sparse label supervision. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art approaches on the NYUv2 and Replica datasets.
ELGAR: Expressive Cello Performance Motion Generation for Audio Rendition
May 07, 2025The art of instrument performance stands as a vivid manifestation of human creativity and emotion. Nonetheless, generating instrument performance motions is a highly challenging task, as it requires not only capturing intricate movements but also reconstructing the complex dynamics of the performer-instrument interaction. While existing works primarily focus on modeling partial body motions, we propose Expressive ceLlo performance motion Generation for Audio Rendition (ELGAR), a state-of-the-art diffusion-based framework for whole-body fine-grained instrument performance motion generation solely from audio. To emphasize the interactive nature of the instrument performance, we introduce Hand Interactive Contact Loss (HICL) and Bow Interactive Contact Loss (BICL), which effectively guarantee the authenticity of the interplay. Moreover, to better evaluate whether the generated motions align with the semantic context of the music audio, we design novel metrics specifically for string instrument performance motion generation, including finger-contact distance, bow-string distance, and bowing score. Extensive evaluations and ablation studies are conducted to validate the efficacy of the proposed methods. In addition, we put forward a motion generation dataset SPD-GEN, collated and normalized from the MoCap dataset SPD. As demonstrated, ELGAR has shown great potential in generating instrument performance motions with complicated and fast interactions, which will promote further development in areas such as animation, music education, interactive art creation, etc.
PARC: Physics-based Augmentation with Reinforcement Learning for Character Controllers
May 06, 2025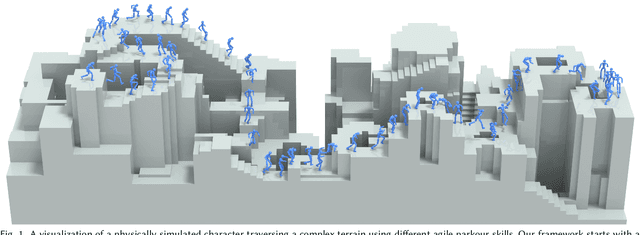
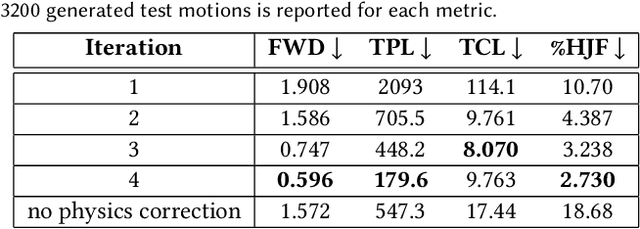

Humans excel in navigating diverse, complex environments with agile motor skills, exemplified by parkour practitioners performing dynamic maneuvers, such as climbing up walls and jumping across gaps. Reproducing these agile movements with simulated characters remains challenging, in part due to the scarcity of motion capture data for agile terrain traversal behaviors and the high cost of acquiring such data. In this work, we introduce PARC (Physics-based Augmentation with Reinforcement Learning for Character Controllers), a framework that leverages machine learning and physics-based simulation to iteratively augment motion datasets and expand the capabilities of terrain traversal controllers. PARC begins by training a motion generator on a small dataset consisting of core terrain traversal skills. The motion generator is then used to produce synthetic data for traversing new terrains. However, these generated motions often exhibit artifacts, such as incorrect contacts or discontinuities. To correct these artifacts, we train a physics-based tracking controller to imitate the motions in simulation. The corrected motions are then added to the dataset, which is used to continue training the motion generator in the next iteration. PARC's iterative process jointly expands the capabilities of the motion generator and tracker, creating agile and versatile models for interacting with complex environments. PARC provides an effective approach to develop controllers for agile terrain traversal, which bridges the gap between the scarcity of motion data and the need for versatile character controllers.
StableMotion: Training Motion Cleanup Models with Unpaired Corrupted Data
May 06, 2025
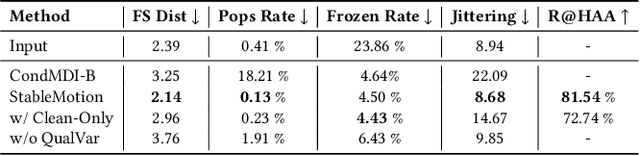
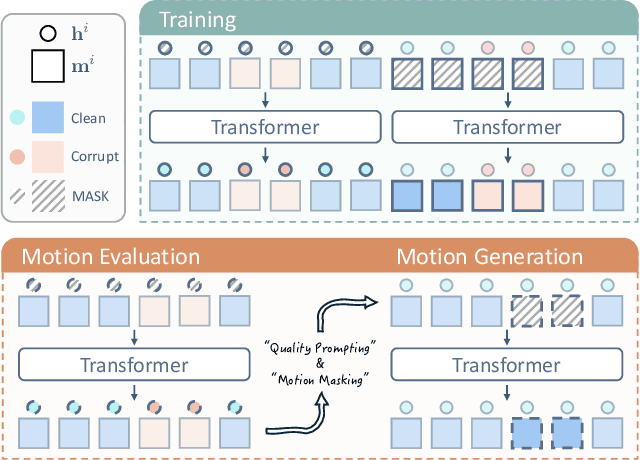
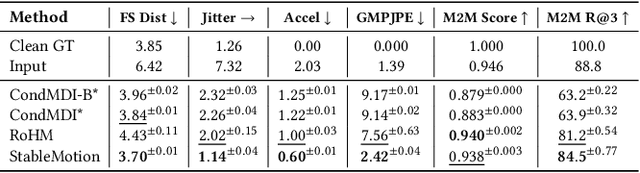
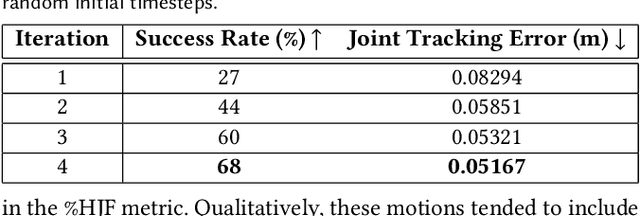
Motion capture (mocap) data often exhibits visually jarring artifacts due to inaccurate sensors and post-processing. Cleaning this corrupted data can require substantial manual effort from human experts, which can be a costly and time-consuming process. Previous data-driven motion cleanup methods offer the promise of automating this cleanup process, but often require in-domain paired corrupted-to-clean training data. Constructing such paired datasets requires access to high-quality, relatively artifact-free motion clips, which often necessitates laborious manual cleanup. In this work, we present StableMotion, a simple yet effective method for training motion cleanup models directly from unpaired corrupted datasets that need cleanup. The core component of our method is the introduction of motion quality indicators, which can be easily annotated through manual labeling or heuristic algorithms and enable training of quality-aware motion generation models on raw motion data with mixed quality. At test time, the model can be prompted to generate high-quality motions using the quality indicators. Our method can be implemented through a simple diffusion-based framework, leading to a unified motion generate-discriminate model, which can be used to both identify and fix corrupted frames. We demonstrate that our proposed method is effective for training motion cleanup models on raw mocap data in production scenarios by applying StableMotion to SoccerMocap, a 245-hour soccer mocap dataset containing real-world motion artifacts. The trained model effectively corrects a wide range of motion artifacts, reducing motion pops and frozen frames by 68% and 81%, respectively. See https://youtu.be/3Y7MMAH02B4 for more results.
SpeHeatal: A Cluster-Enhanced Segmentation Method for Sperm Morphology Analysis
Feb 18, 2025The accurate assessment of sperm morphology is crucial in andrological diagnostics, where the segmentation of sperm images presents significant challenges. Existing approaches frequently rely on large annotated datasets and often struggle with the segmentation of overlapping sperm and the presence of dye impurities. To address these challenges, this paper first analyzes the issue of overlapping sperm tails from a geometric perspective and introduces a novel clustering algorithm, Con2Dis, which effectively segments overlapping tails by considering three essential factors: CONnectivity, CONformity, and DIStance. Building on this foundation, we propose an unsupervised method, SpeHeatal, designed for the comprehensive segmentation of the SPErm HEAd and TAiL. SpeHeatal employs the Segment Anything Model(SAM) to generate masks for sperm heads while filtering out dye impurities, utilizes Con2Dis to segment tails, and then applies a tailored mask splicing technique to produce complete sperm masks. Experimental results underscore the superior performance of SpeHeatal, particularly in handling images with overlapping sperm.