 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableMotion: Training Motion Cleanup Models with Unpaired Corrupted Data
May 06, 2025
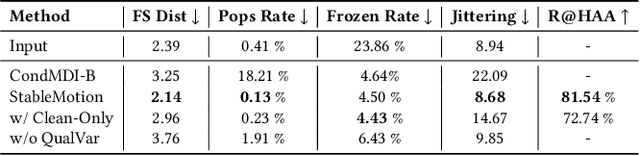
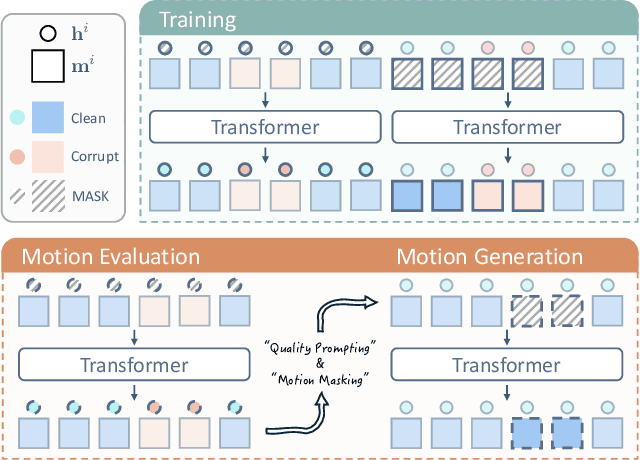
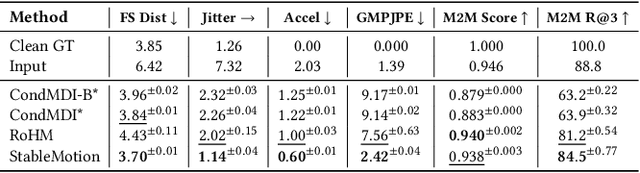
Motion capture (mocap) data often exhibits visually jarring artifacts due to inaccurate sensors and post-processing. Cleaning this corrupted data can require substantial manual effort from human experts, which can be a costly and time-consuming process. Previous data-driven motion cleanup methods offer the promise of automating this cleanup process, but often require in-domain paired corrupted-to-clean training data. Constructing such paired datasets requires access to high-quality, relatively artifact-free motion clips, which often necessitates laborious manual cleanup. In this work, we present StableMotion, a simple yet effective method for training motion cleanup models directly from unpaired corrupted datasets that need cleanup. The core component of our method is the introduction of motion quality indicators, which can be easily annotated through manual labeling or heuristic algorithms and enable training of quality-aware motion generation models on raw motion data with mixed quality. At test time, the model can be prompted to generate high-quality motions using the quality indicators. Our method can be implemented through a simple diffusion-based framework, leading to a unified motion generate-discriminate model, which can be used to both identify and fix corrupted frames. We demonstrate that our proposed method is effective for training motion cleanup models on raw mocap data in production scenarios by applying StableMotion to SoccerMocap, a 245-hour soccer mocap dataset containing real-world motion artifacts. The trained model effectively corrects a wide range of motion artifacts, reducing motion pops and frozen frames by 68% and 81%, respectively. See https://youtu.be/3Y7MMAH02B4 for more results.
MotionDreamer: One-to-Many Motion Synthesis with Localized Generative Masked Transformer
Apr 11, 2025Generative masked transformers have demonstrated remarkable success across various content generation tasks, primarily due to their ability to effectively model large-scale dataset distributions with high consistency. However, in the animation domain, large datasets are not always available. Applying generative masked modeling to generate diverse instances from a single MoCap reference may lead to overfitting, a challenge that remains unexplored. In this work, we present MotionDreamer, a localized masked modeling paradigm designed to learn internal motion patterns from a given motion with arbitrary topology and duration. By embedding the given motion into quantized tokens with a novel distribution regularization method, MotionDreamer constructs a robust and informative codebook for local motion patterns. Moreover, a sliding window local attention is introduced in our masked transformer, enabling the generation of natural yet diverse animations that closely resemble the reference motion patterns. As demonstrated through comprehensive experiments, MotionDreamer outperforms the state-of-the-art methods that are typically GAN or Diffusion-based in both faithfulness and diversity. Thanks to the consistency and robustness of the quantization-based approach, MotionDreamer can also effectively perform downstream tasks such as temporal motion editing, \textcolor{update}{crowd animation}, and beat-aligned dance generation, all using a single reference motion. Visit our project page: https://motiondreamer.github.io/
GSD: View-Guided Gaussian Splatting Diffusion for 3D Reconstruction
Jul 05, 2024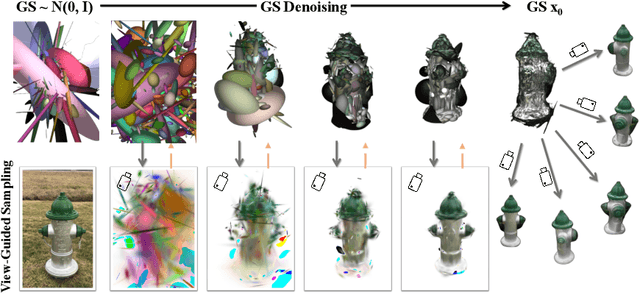



We present GSD, a diffusion model approach based on Gaussian Splatting (GS) representation for 3D object reconstruction from a single view. Prior works suffer from inconsistent 3D geometry or mediocre rendering quality due to improper representations. We take a step towards resolving these shortcomings by utilizing the recent state-of-the-art 3D explicit representation, Gaussian Splatting, and an unconditional diffusion model. This model learns to generate 3D objects represented by sets of GS ellipsoids. With these strong generative 3D priors, though learning unconditionally, the diffusion model is ready for view-guided reconstruction without further model fine-tuning. This is achieved by propagating fine-grained 2D features through the efficient yet flexible splatting function and the guided denoising sampling process. In addition, a 2D diffusion model is further employed to enhance rendering fidelity, and improve reconstructed GS quality by polishing and re-using the rendered images. The final reconstructed objects explicitly come with high-quality 3D structure and texture, and can be efficiently rendered in arbitrary views. Experiments on the challenging real-world CO3D dataset demonstrate the superiority of our approach.
Sakuga-42M Dataset: Scaling Up Cartoon Research
May 13, 2024

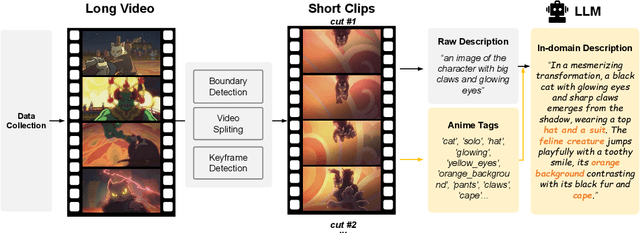
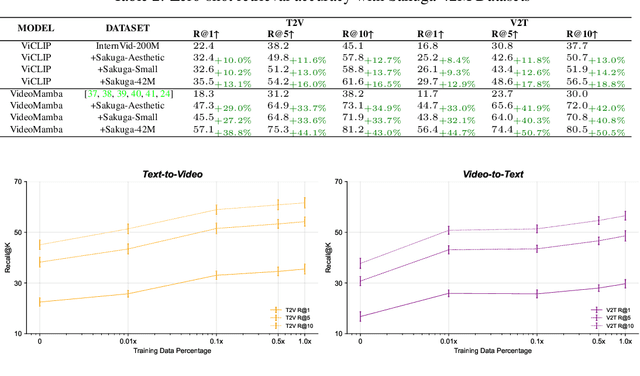
Hand-drawn cartoon animation employs sketches and flat-color segments to create the illusion of motion. While recent advancements like CLIP, SVD, and Sora show impressive results in understanding and generating natural video by scaling large models with extensive datasets, they are not as effective for cartoons. Through our empirical experiments, we argue that this ineffectiveness stems from a notable bias in hand-drawn cartoons that diverges from the distribution of natural videos. Can we harness the success of the scaling paradigm to benefit cartoon research? Unfortunately, until now, there has not been a sizable cartoon dataset available for exploration. In this research, we propose the Sakuga-42M Dataset, the first large-scale cartoon animation dataset. Sakuga-42M comprises 42 million keyframes covering various artistic styles, regions, and years, with comprehensive semantic annotations including video-text description pairs, anime tags, content taxonomies, etc. We pioneer the benefits of such a large-scale cartoon dataset on comprehension and generation tasks by finetuning contemporary foundation models like Video CLIP, Video Mamba, and SVD, achieving outstanding performance on cartoon-related tasks. Our motivation is to introduce large-scaling to cartoon research and foster generalization and robustness in future cartoon applications. Dataset, Code, and Pretrained Models will be publicly available.
Generative Human Motion Stylization in Latent Space
Jan 24, 2024



Human motion stylization aims to revise the style of an input motion while keeping its content unaltered. Unlike existing works that operate directly in pose space, we leverage the latent space of pretrained autoencoders as a more expressive and robust representation for motion extraction and infusion. Building upon this, we present a novel generative model that produces diverse stylization results of a single motion (latent) code. During training, a motion code is decomposed into two coding components: a deterministic content code, and a probabilistic style code adhering to a prior distribution; then a generator massages the random combination of content and style codes to reconstruct the corresponding motion codes. Our approach is versatile, allowing the learning of probabilistic style space from either style labeled or unlabeled motions, providing notable flexibility in stylization as well. In inference, users can opt to stylize a motion using style cues from a reference motion or a label. Even in the absence of explicit style input, our model facilitates novel re-stylization by sampling from the unconditional style prior distribution. Experimental results show that our proposed stylization models, despite their lightweight design, outperform the state-of-the-arts in style reeanactment, content preservation, and generalization across various applications and settings. Project Page: https://yxmu.foo/GenMoStyle
MoMask: Generative Masked Modeling of 3D Human Motions
Nov 29, 2023



We introduce MoMask, a novel masked modeling framework for text-driven 3D human motion generation. In MoMask, a hierarchical quantization scheme is employed to represent human motion as multi-layer discrete motion tokens with high-fidelity details. Starting at the base layer, with a sequence of motion tokens obtained by vector quantization, the residual tokens of increasing orders are derived and stored at the subsequent layers of the hierarchy. This is consequently followed by two distinct bidirectional transformers. For the base-layer motion tokens, a Masked Transformer is designated to predict randomly masked motion tokens conditioned on text input at training stage. During generation (i.e. inference) stage, starting from an empty sequence, our Masked Transformer iteratively fills up the missing tokens; Subsequently, a Residual Transformer learns to progressively predict the next-layer tokens based on the results from current layer. Extensive experiments demonstrate that MoMask outperforms the state-of-art methods on the text-to-motion generation task, with an FID of 0.045 (vs e.g. 0.141 of T2M-GPT) on the HumanML3D dataset, and 0.228 (vs 0.514) on KIT-ML, respectively. MoMask can also be seamlessly applied in related tasks without further model fine-tuning, such as text-guided temporal inpainting.
Event-based Human Pose Tracking by Spiking Spatiotemporal Transformer
Mar 31, 2023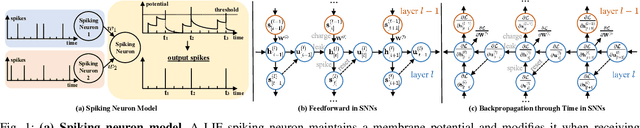
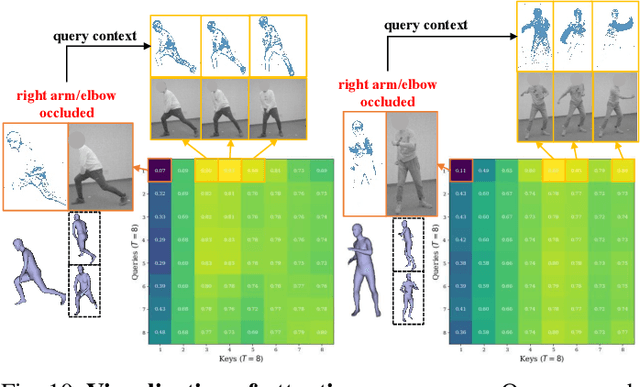
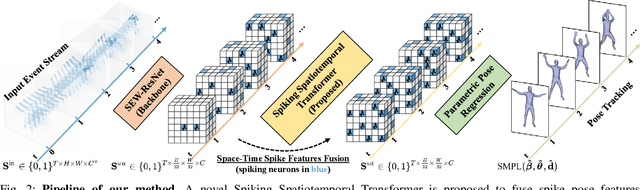
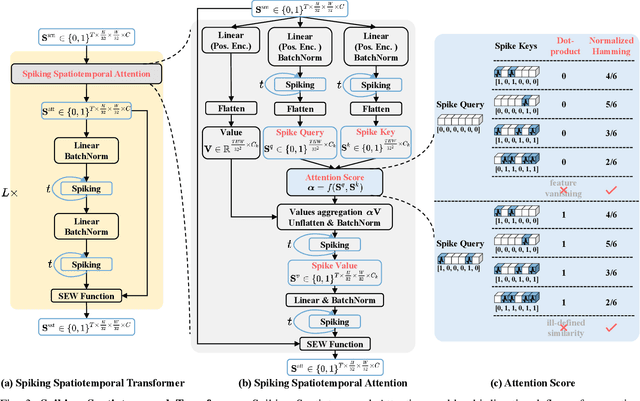
Event camera, as an emerging biologically-inspired vision sensor for capturing motion dynamics, presents new potential for 3D human pose tracking, or video-based 3D human pose estimation. However, existing works in pose tracking either require the presence of additional gray-scale images to establish a solid starting pose, or ignore the temporal dependencies all together by collapsing segments of event streams to form static event frames. Meanwhile, although the effectiveness of Artificial Neural Networks (ANNs, a.k.a. dense deep learning) has been showcased in many event-based tasks, the use of ANNs tends to neglect the fact that compared to the dense frame-based image sequences, the occurrence of events from an event camera is spatiotemporally much sparser. Motivated by the above mentioned issues, we present in this paper a dedicated end-to-end sparse deep learning approach for event-based pose tracking: 1) to our knowledge this is the first time that 3D human pose tracking is obtained from events only, thus eliminating the need of accessing to any frame-based images as part of input; 2) our approach is based entirely upon the framework of Spiking Neural Networks (SNNs), which consists of Spike-Element-Wise (SEW) ResNet and a novel Spiking Spatiotemporal Transformer; 3) a large-scale synthetic dataset is constructed that features a broad and diverse set of annotated 3D human motions, as well as longer hours of event stream data, named SynEventHPD. Empirical experiments demonstrate that, with superior performance over the state-of-the-art (SOTA) ANNs counterparts, our approach also achieves a significant computation reduction of 80% in FLOPS. Furthermore, our proposed method also outperforms SOTA SNNs in the regression task of human pose tracking. Our implementation is available at https://github.com/JimmyZou/HumanPoseTracking_SNN and dataset will be released upon paper acceptance.