 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFood-R1: A Unified Multi-Task Food Vision-Language Model with Reinforcement Learning
Jun 03, 2026Recent studies have explored Vision-Language Models (VLMs) for food analysis. However, most existing methods rely primarily on supervised fine-tuning (SFT), which often limits reasoning and generalization capabilities. Moreover, high-quality large-scale nutritional annotations remain scarce. To address these issues, we introduce CalorieBench-80K, a large-scale benchmark with curated calorie labels and dietary advice annotations. To the best of our knowledge, it is the first food image benchmark to incorporate Chain-of-Thought (CoT) annotations for calorie reasoning. We also propose Food-R1, a unified food VLM trained in a multi-task learning paradigm to equip the model with broad capabilities. Food-R1 undergoes CoT-based cold-start instruction tuning, followed by reinforcement fine-tuning (RFT) using Group Relative Policy Optimization (GRPO) to improve reasoning and performance. Experiments on CalorieBench-80K and representative benchmarks show that Food-R1 consistently outperforms strong baselines across food-related tasks. The code, model weights, and benchmark annotations are available at the project repository.
NeuroFlow: Toward Unified Visual Encoding and Decoding from Neural Activity
Apr 10, 2026Visual encoding and decoding models act as gateways to understanding the neural mechanisms underlying human visual perception. Typically, visual encoding models that predict brain activity from stimuli and decoding models that reproduce stimuli from brain activity are treated as distinct tasks, requiring separate models and training procedures. This separation is inefficient and fails to model the consistency between encoding and decoding processes. To address this limitation, we propose NeuroFlow, the first unified framework that jointly models visual encoding and decoding from neural activity within a single flow model. NeuroFlow introduces two key components: (1) NeuroVAE is designed as a variational backbone to model neural variability and establish a compact, semantically structured latent space for bidirectional modeling across visual and neural modalities. (2) Cross-modal Flow Matching (XFM) bypasses the typical paradigm of noise-to-data diffusion guided by a specific modality condition, instead learning a reversibly consistent flow model between visual and neural latent distributions. For the first time, visual encoding and decoding are reformulated as a time-dependent, reversible process within a shared latent space for unified modeling. Empirical results demonstrate that NeuroFlow achieves superior overall performance in visual encoding and decoding tasks with higher computational efficiency compared to any isolated methods. We further analyze principal factors that steer the model toward encoding-decoding consistency and, through brain functional analyses, demonstrate that NeuroFlow captures consistent activation patterns underlying neural variability. NeuroFlow marks a major step toward unified visual encoding and decoding from neural activity, providing mechanistic insights that inform future bidirectional visual brain-computer interfaces.
Unlocking Positive Transfer in Incrementally Learning Surgical Instruments: A Self-reflection Hierarchical Prompt Framework
Apr 03, 2026To continuously enhance model adaptability in surgical video scene parsing, recent studies incrementally update it to progressively learn to segment an increasing number of surgical instruments over time. However, prior works constantly overlooked the potential of positive forward knowledge transfer, i.e., how past knowledge could help learn new classes, and positive backward knowledge transfer, i.e., how learning new classes could help refine past knowledge. In this paper, we propose a self-reflection hierarchical prompt framework that unlocks the power of positive forward and backward knowledge transfer in class incremental segmentation, aiming to proficiently learn new instruments, improve existing skills of regular instruments, and avoid catastrophic forgetting of old instruments. Our framework is built on a frozen, pre-trained model that adaptively appends instrument-aware prompts for new classes throughout training episodes. To enable positive forward knowledge transfer, we organize instrument prompts into a hierarchical prompt parsing tree with the instrument-shared prompt partition as the root node, n-part-shared prompt partitions as intermediate nodes and instrument-distinct prompt partitions as leaf nodes, to expose the reusable historical knowledge for new classes to simplify their learning. Conversely, to encourage positive backward knowledge transfer, we conduct self-reflection refining on existing knowledge by directed-weighted graph propagation, examining the knowledge associations recorded in the tree to improve its representativeness without causing catastrophic forgetting. Our framework is applicable to both CNN-based models and advanced transformer-based foundation models, yielding more than 5% and 11% improvements over the competing methods on two public benchmarks respectively.
LLM-Driven Multi-Turn Task-Oriented Dialogue Synthesis for Realistic Reasoning
Feb 27, 2026The reasoning capability of large language models (LLMs), defined as their ability to analyze, infer, and make decisions based on input information, is essential for building intelligent task-oriented dialogue systems. However, existing benchmarks do not sufficiently reflect the complexity of real-world scenarios, which limits their effectiveness in evaluating and enhancing LLM reasoning in practical contexts. Many current reasoning datasets are overly simplistic and abstract, often disconnected from realistic task flows, domain constraints, and operational rules, making it difficult to effectively evaluate LLMs' logical reasoning ability. In addition, data contamination from pretraining corpora undermines the reliability of evaluation results, and traditional crowdsourcing methods for dataset construction are labor-intensive and difficult to scale. To address these challenges, we propose a LLM-driven framework for synthesizing multi-turn, task-oriented dialogues grounded in realistic reasoning scenarios, leveraging trilevel optimization to enhance dialogue quality. Our method generates dialogues grounded in authentic task scenarios, enriched with real-world information, and exhibiting strong contextual coherence. Corresponding reasoning tasks are carefully designed around these dialogues and iteratively refined to continuously improve the tasks' quality and challenge. The resulting dataset serves as a valuable benchmark for assessing and advancing the realistic logical reasoning capabilities of LLMs. Experimental results show that our synthetic data-based reasoning tasks introduce non-trivial reasoning challenges and provide meaningful support for improving the reasoning capabilities of LLMs.
Explainable Interictal Epileptiform Discharge Detection Method Based on Scalp EEG and Retrieval-Augmented Generation
Feb 15, 2026The detection of interictal epileptiform discharge (IED) is crucial for the diagnosis of epilepsy, but automated methods often lack interpretability. This study proposes IED-RAG, an explainable multimodal framework for joint IED detection and report generation. Our approach employs a dual-encoder to extract electrophysiological and semantic features, aligned via contrastive learning in a shared EEG-text embedding space. During inference, clinically relevant EEG-text pairs are retrieved from a vector database as explicit evidence to condition a large language model (LLM) for the generation of evidence-based reports. Evaluated on a private dataset from Wuhan Children's Hospital and the public TUH EEG Events Corpus (TUEV), the framework achieved balanced accuracies of 89.17\% and 71.38\%, with BLEU scores of 89.61\% and 64.14\%, respectively. The results demonstrate that retrieval of explicit evidence enhances both diagnostic performance and clinical interpretability compared to standard black-box methods.
Spark-Prover-X1: Formal Theorem Proving Through Diverse Data Training
Nov 18, 2025Large Language Models (LLMs) have shown significant promise in automated theorem proving, yet progress is often constrained by the scarcity of diverse and high-quality formal language data. To address this issue, we introduce Spark-Prover-X1, a 7B parameter model trained via an three-stage framework designed to unlock the reasoning potential of more accessible and moderately-sized LLMs. The first stage infuses deep knowledge through continuous pre-training on a broad mathematical corpus, enhanced by a suite of novel data tasks. Key innovation is a "CoT-augmented state prediction" task to achieve fine-grained reasoning. The second stage employs Supervised Fine-tuning (SFT) within an expert iteration loop to specialize both the Spark-Prover-X1-7B and Spark-Formalizer-X1-7B models. Finally, a targeted round of Group Relative Policy Optimization (GRPO) is applied to sharpen the prover's capabilities on the most challenging problems. To facilitate robust evaluation, particularly on problems from real-world examinations, we also introduce ExamFormal-Bench, a new benchmark dataset of 402 formal problems. Experimental results demonstrate that Spark-Prover achieves state-of-the-art performance among similarly-sized open-source models within the "Whole-Proof Generation" paradigm. It shows exceptional performance on difficult competition benchmarks, notably solving 27 problems on PutnamBench (pass@32) and achieving 24.0\% on CombiBench (pass@32). Our work validates that this diverse training data and progressively refined training pipeline provides an effective path for enhancing the formal reasoning capabilities of lightweight LLMs. Both Spark-Prover-X1-7B and Spark-Formalizer-X1-7B, along with the ExamFormal-Bench dataset, are made publicly available at: https://www.modelscope.cn/organization/iflytek, https://gitcode.com/ifly_opensource.
CapeNext: Rethinking and refining dynamic support information for category-agnostic pose estimation
Nov 17, 2025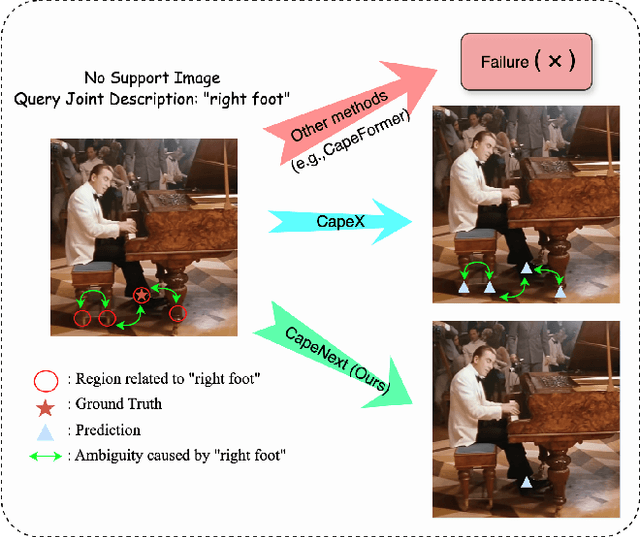
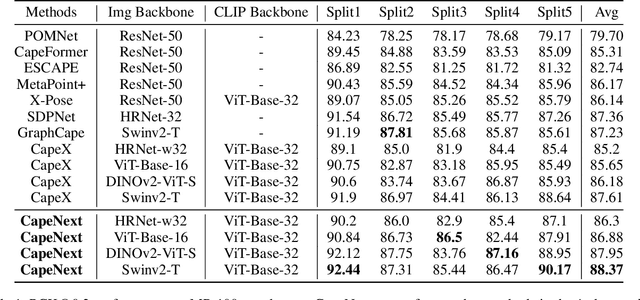
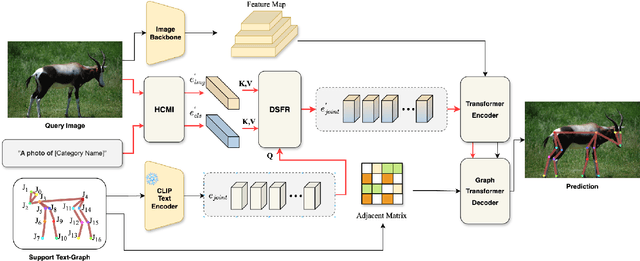
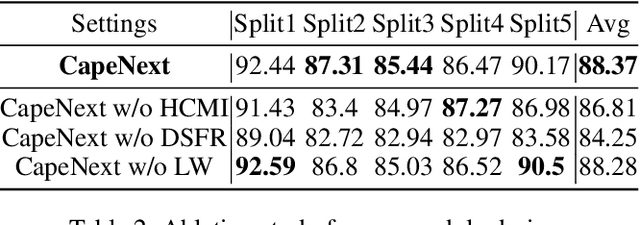
Recent research in Category-Agnostic Pose Estimation (CAPE) has adopted fixed textual keypoint description as semantic prior for two-stage pose matching frameworks. While this paradigm enhances robustness and flexibility by disentangling the dependency of support images, our critical analysis reveals two inherent limitations of static joint embedding: (1) polysemy-induced cross-category ambiguity during the matching process(e.g., the concept "leg" exhibiting divergent visual manifestations across humans and furniture), and (2) insufficient discriminability for fine-grained intra-category variations (e.g., posture and fur discrepancies between a sleeping white cat and a standing black cat). To overcome these challenges, we propose a new framework that innovatively integrates hierarchical cross-modal interaction with dual-stream feature refinement, enhancing the joint embedding with both class-level and instance-specific cues from textual description and specific images. Experiments on the MP-100 dataset demonstrate that, regardless of the network backbone, CapeNext consistently outperforms state-of-the-art CAPE methods by a large margin.
SRLF: An Agent-Driven Set-Wise Reflective Learning Framework for Sequential Recommendation
Nov 14, 2025LLM-based agents are emerging as a promising paradigm for simulating user behavior to enhance recommender systems. However, their effectiveness is often limited by existing studies that focus on modeling user ratings for individual items. This point-wise approach leads to prevalent issues such as inaccurate user preference comprehension and rigid item-semantic representations. To address these limitations, we propose the novel Set-wise Reflective Learning Framework (SRLF). Our framework operationalizes a closed-loop "assess-validate-reflect" cycle that harnesses the powerful in-context learning capabilities of LLMs. SRLF departs from conventional point-wise assessment by formulating a holistic judgment on an entire set of items. It accomplishes this by comprehensively analyzing both the intricate interrelationships among items within the set and their collective alignment with the user's preference profile. This method of set-level contextual understanding allows our model to capture complex relational patterns essential to user behavior, making it significantly more adept for sequential recommendation. Extensive experiments validate our approach, confirming that this set-wise perspective is crucial for achieving state-of-the-art performance in sequential recommendation tasks.
Early Stopping Chain-of-thoughts in Large Language Models
Sep 17, 2025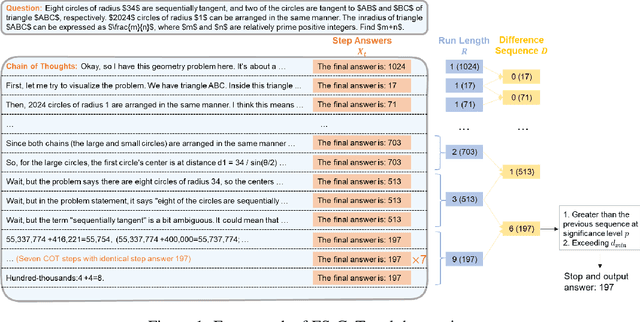
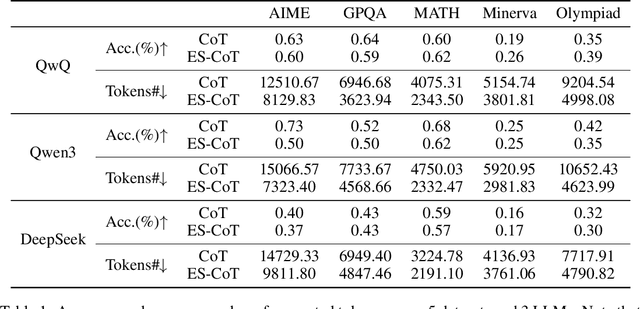
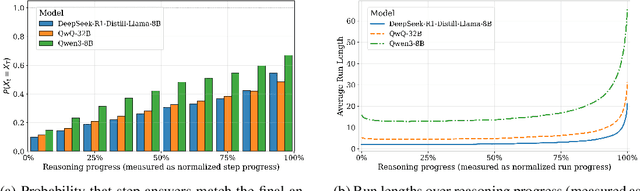
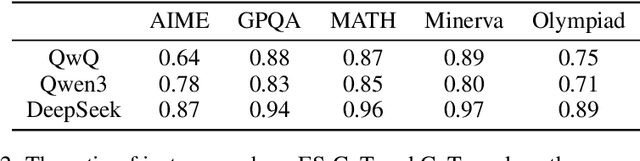
Reasoning large language models (LLMs) have demonstrated superior capacities in solving complicated problems by generating long chain-of-thoughts (CoT), but such a lengthy CoT incurs high inference costs. In this study, we introduce ES-CoT, an inference-time method that shortens CoT generation by detecting answer convergence and stopping early with minimal performance loss. At the end of each reasoning step, we prompt the LLM to output its current final answer, denoted as a step answer. We then track the run length of consecutive identical step answers as a measure of answer convergence. Once the run length exhibits a sharp increase and exceeds a minimum threshold, the generation is terminated. We provide both empirical and theoretical support for this heuristic: step answers steadily converge to the final answer, and large run-length jumps reliably mark this convergence. Experiments on five reasoning datasets across three LLMs show that ES-CoT reduces the number of inference tokens by about 41\% on average while maintaining accuracy comparable to standard CoT. Further, ES-CoT integrates seamlessly with self-consistency prompting and remains robust across hyperparameter choices, highlighting it as a practical and effective approach for efficient reasoning.
SynBrain: Enhancing Visual-to-fMRI Synthesis via Probabilistic Representation Learning
Aug 14, 2025Deciphering how visual stimuli are transformed into cortical responses is a fundamental challenge in computational neuroscience. This visual-to-neural mapping is inherently a one-to-many relationship, as identical visual inputs reliably evoke variable hemodynamic responses across trials, contexts, and subjects. However, existing deterministic methods struggle to simultaneously model this biological variability while capturing the underlying functional consistency that encodes stimulus information. To address these limitations, we propose SynBrain, a generative framework that simulates the transformation from visual semantics to neural responses in a probabilistic and biologically interpretable manner. SynBrain introduces two key components: (i) BrainVAE models neural representations as continuous probability distributions via probabilistic learning while maintaining functional consistency through visual semantic constraints; (ii) A Semantic-to-Neural Mapper acts as a semantic transmission pathway, projecting visual semantics into the neural response manifold to facilitate high-fidelity fMRI synthesis. Experimental results demonstrate that SynBrain surpasses state-of-the-art methods in subject-specific visual-to-fMRI encoding performance. Furthermore, SynBrain adapts efficiently to new subjects with few-shot data and synthesizes high-quality fMRI signals that are effective in improving data-limited fMRI-to-image decoding performance. Beyond that, SynBrain reveals functional consistency across trials and subjects, with synthesized signals capturing interpretable patterns shaped by biological neural variability. The code will be made publicly available.