 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualTSR: Unified Dual-Diffusion Transformer for Scene Text Image Super-Resolution
Mar 15, 2026Scene Text Image Super-Resolution (STISR) aims to restore high-resolution details in low-resolution text images, which is crucial for both human readability and machine recognition. Existing methods, however, often depend on external Optical Character Recognition (OCR) models for textual priors or rely on complex multi-component architectures that are difficult to train and reproduce. In this paper, we introduce DualTSR, a unified end-to-end framework that addresses both issues. DualTSR employs a single multimodal transformer backbone trained with a dual diffusion objective. It simultaneously models the continuous distribution of high-resolution images via Conditional Flow Matching and the discrete distribution of textual content via discrete diffusion. This shared design enables visual and textual information to interact at every layer, allowing the model to infer text priors internally instead of relying on an external OCR module. Compared with prior multi-branch diffusion systems, DualTSR offers a simpler end-to-end formulation with fewer hand-crafted components. Experiments on synthetic Chinese benchmarks and a curated real-world evaluation protocol show that DualTSR achieves strong perceptual quality and text fidelity.
Sparse2DGS: Geometry-Prioritized Gaussian Splatting for Surface Reconstruction from Sparse Views
Apr 29, 2025We present a Gaussian Splatting method for surface reconstruction using sparse input views. Previous methods relying on dense views struggle with extremely sparse Structure-from-Motion points for initialization. While learning-based Multi-view Stereo (MVS) provides dense 3D points, directly combining it with Gaussian Splatting leads to suboptimal results due to the ill-posed nature of sparse-view geometric optimization. We propose Sparse2DGS, an MVS-initialized Gaussian Splatting pipeline for complete and accurate reconstruction. Our key insight is to incorporate the geometric-prioritized enhancement schemes, allowing for direct and robust geometric learning under ill-posed conditions. Sparse2DGS outperforms existing methods by notable margins while being ${2}\times$ faster than the NeRF-based fine-tuning approach.
HVI: A New Color Space for Low-light Image Enhancement
Feb 28, 2025



Low-Light Image Enhancement (LLIE) is a crucial computer vision task that aims to restore detailed visual information from corrupted low-light images. Many existing LLIE methods are based on standard RGB (sRGB) space, which often produce color bias and brightness artifacts due to inherent high color sensitivity in sRGB. While converting the images using Hue, Saturation and Value (HSV) color space helps resolve the brightness issue, it introduces significant red and black noise artifacts. To address this issue, we propose a new color space for LLIE, namely Horizontal/Vertical-Intensity (HVI), defined by polarized HS maps and learnable intensity. The former enforces small distances for red coordinates to remove the red artifacts, while the latter compresses the low-light regions to remove the black artifacts. To fully leverage the chromatic and intensity information, a novel Color and Intensity Decoupling Network (CIDNet) is further introduced to learn accurate photometric mapping function under different lighting conditions in the HVI space. Comprehensive results from benchmark and ablation experiments show that the proposed HVI color space with CIDNet outperforms the state-of-the-art methods on 10 datasets. The code is available at https://github.com/Fediory/HVI-CIDNet.
C-Drag: Chain-of-Thought Driven Motion Controller for Video Generation
Feb 27, 2025



Trajectory-based motion control has emerged as an intuitive and efficient approach for controllable video generation. However, the existing trajectory-based approaches are usually limited to only generating the motion trajectory of the controlled object and ignoring the dynamic interactions between the controlled object and its surroundings. To address this limitation, we propose a Chain-of-Thought-based motion controller for controllable video generation, named C-Drag. Instead of directly generating the motion of some objects, our C-Drag first performs object perception and then reasons the dynamic interactions between different objects according to the given motion control of the objects. Specifically, our method includes an object perception module and a Chain-of-Thought-based motion reasoning module. The object perception module employs visual language models to capture the position and category information of various objects within the image. The Chain-of-Thought-based motion reasoning module takes this information as input and conducts a stage-wise reasoning process to generate motion trajectories for each of the affected objects, which are subsequently fed to the diffusion model for video synthesis. Furthermore, we introduce a new video object interaction (VOI) dataset to evaluate the generation quality of motion controlled video generation methods. Our VOI dataset contains three typical types of interactions and provides the motion trajectories of objects that can be used for accurate performance evaluation. Experimental results show that C-Drag achieves promising performance across multiple metrics, excelling in object motion control. Our benchmark, codes, and models will be available at https://github.com/WesLee88524/C-Drag-Official-Repo.
UIR-LoRA: Achieving Universal Image Restoration through Multiple Low-Rank Adaptation
Sep 30, 2024



Existing unified methods typically treat multi-degradation image restoration as a multi-task learning problem. Despite performing effectively compared to single degradation restoration methods, they overlook the utilization of commonalities and specificities within multi-task restoration, thereby impeding the model's performance. Inspired by the success of deep generative models and fine-tuning techniques, we proposed a universal image restoration framework based on multiple low-rank adapters (LoRA) from multi-domain transfer learning. Our framework leverages the pre-trained generative model as the shared component for multi-degradation restoration and transfers it to specific degradation image restoration tasks using low-rank adaptation. Additionally, we introduce a LoRA composing strategy based on the degradation similarity, which adaptively combines trained LoRAs and enables our model to be applicable for mixed degradation restoration. Extensive experiments on multiple and mixed degradations demonstrate that the proposed universal image restoration method not only achieves higher fidelity and perceptual image quality but also has better generalization ability than other unified image restoration models. Our code is available at https://github.com/Justones/UIR-LoRA.
Multi-Granularity Language-Guided Multi-Object Tracking
Jun 07, 2024



Most existing multi-object tracking methods typically learn visual tracking features via maximizing dis-similarities of different instances and minimizing similarities of the same instance. While such a feature learning scheme achieves promising performance, learning discriminative features solely based on visual information is challenging especially in case of environmental interference such as occlusion, blur and domain variance. In this work, we argue that multi-modal language-driven features provide complementary information to classical visual features, thereby aiding in improving the robustness to such environmental interference. To this end, we propose a new multi-object tracking framework, named LG-MOT, that explicitly leverages language information at different levels of granularity (scene-and instance-level) and combines it with standard visual features to obtain discriminative representations. To develop LG-MOT, we annotate existing MOT datasets with scene-and instance-level language descriptions. We then encode both instance-and scene-level language information into high-dimensional embeddings, which are utilized to guide the visual features during training. At inference, our LG-MOT uses the standard visual features without relying on annotated language descriptions. Extensive experiments on three benchmarks, MOT17, DanceTrack and SportsMOT, reveal the merits of the proposed contributions leading to state-of-the-art performance. On the DanceTrack test set, our LG-MOT achieves an absolute gain of 2.2\% in terms of target object association (IDF1 score), compared to the baseline using only visual features. Further, our LG-MOT exhibits strong cross-domain generalizability. The dataset and code will be available at ~\url{https://github.com/WesLee88524/LG-MOT}.
The Third Monocular Depth Estimation Challenge
Apr 27, 2024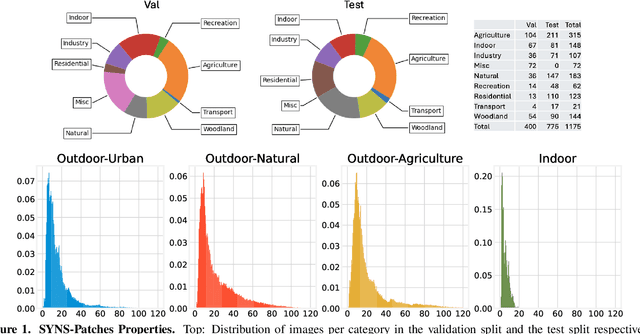

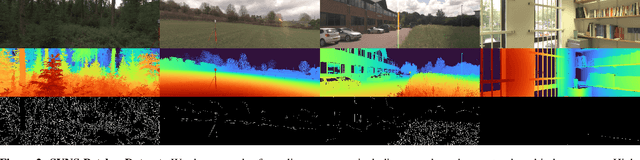
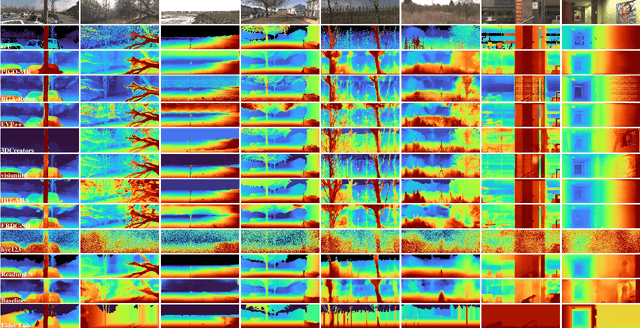
This paper discusses the results of the third edition of the Monocular Depth Estimation Challenge (MDEC). The challenge focuses on zero-shot generalization to the challenging SYNS-Patches dataset, featuring complex scenes in natural and indoor settings. As with the previous edition, methods can use any form of supervision, i.e. supervised or self-supervised. The challenge received a total of 19 submissions outperforming the baseline on the test set: 10 among them submitted a report describing their approach, highlighting a diffused use of foundational models such as Depth Anything at the core of their method. The challenge winners drastically improved 3D F-Score performance, from 17.51% to 23.72%.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024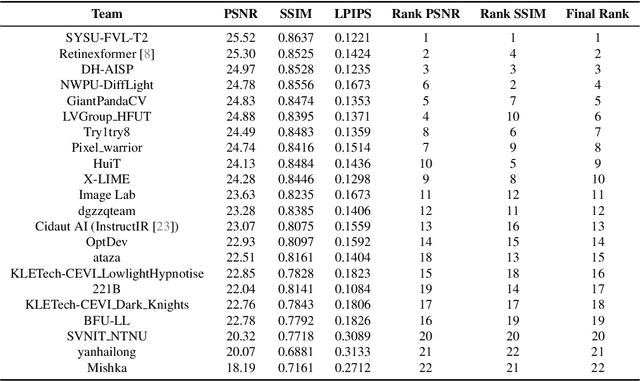


This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
GoMVS: Geometrically Consistent Cost Aggregation for Multi-View Stereo
Apr 11, 2024



Matching cost aggregation plays a fundamental role in learning-based multi-view stereo networks. However, directly aggregating adjacent costs can lead to suboptimal results due to local geometric inconsistency. Related methods either seek selective aggregation or improve aggregated depth in the 2D space, both are unable to handle geometric inconsistency in the cost volume effectively. In this paper, we propose GoMVS to aggregate geometrically consistent costs, yielding better utilization of adjacent geometries. More specifically, we correspond and propagate adjacent costs to the reference pixel by leveraging the local geometric smoothness in conjunction with surface normals. We achieve this by the geometric consistent propagation (GCP) module. It computes the correspondence from the adjacent depth hypothesis space to the reference depth space using surface normals, then uses the correspondence to propagate adjacent costs to the reference geometry, followed by a convolution for aggregation. Our method achieves new state-of-the-art performance on DTU, Tanks & Temple, and ETH3D datasets. Notably, our method ranks 1st on the Tanks & Temple Advanced benchmark.
Boosting Multi-view Stereo with Late Cost Aggregation
Jan 24, 2024



Pairwise matching cost aggregation is a crucial step for modern learning-based Multi-view Stereo (MVS). Prior works adopt an early aggregation scheme, which adds up pairwise costs into an intermediate cost. However, we analyze that this process can degrade informative pairwise matchings, thereby blocking the depth network from fully utilizing the original geometric matching cues. To address this challenge, we present a late aggregation approach that allows for aggregating pairwise costs throughout the network feed-forward process, achieving accurate estimations with only minor changes of the plain CasMVSNet. Instead of building an intermediate cost by weighted sum, late aggregation preserves all pairwise costs along a distinct view channel. This enables the succeeding depth network to fully utilize the crucial geometric cues without loss of cost fidelity. Grounded in the new aggregation scheme, we propose further techniques addressing view order dependence inside the preserved cost, handling flexible testing views, and improving the depth filtering process. Despite its technical simplicity, our method improves significantly upon the baseline cascade-based approach, achieving comparable results with state-of-the-art methods with favorable computation overhead.