 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNNSIR: A Simple Spiking Neural Network for Stereo Image Restoration
Aug 17, 2025Spiking Neural Networks (SNNs), characterized by discrete binary activations, offer high computational efficiency and low energy consumption, making them well-suited for computation-intensive tasks such as stereo image restoration. In this work, we propose SNNSIR, a simple yet effective Spiking Neural Network for Stereo Image Restoration, specifically designed under the spike-driven paradigm where neurons transmit information through sparse, event-based binary spikes. In contrast to existing hybrid SNN-ANN models that still rely on operations such as floating-point matrix division or exponentiation, which are incompatible with the binary and event-driven nature of SNNs, our proposed SNNSIR adopts a fully spike-driven architecture to achieve low-power and hardware-friendly computation. To address the expressiveness limitations of binary spiking neurons, we first introduce a lightweight Spike Residual Basic Block (SRBB) to enhance information flow via spike-compatible residual learning. Building on this, the Spike Stereo Convolutional Modulation (SSCM) module introduces simplified nonlinearity through element-wise multiplication and highlights noise-sensitive regions via cross-view-aware modulation. Complementing this, the Spike Stereo Cross-Attention (SSCA) module further improves stereo correspondence by enabling efficient bidirectional feature interaction across views within a spike-compatible framework. Extensive experiments on diverse stereo image restoration tasks, including rain streak removal, raindrop removal, low-light enhancement, and super-resolution demonstrate that our model achieves competitive restoration performance while significantly reducing computational overhead. These results highlight the potential for real-time, low-power stereo vision applications. The code will be available after the article is accepted.
GeoVLA: Empowering 3D Representations in Vision-Language-Action Models
Aug 12, 2025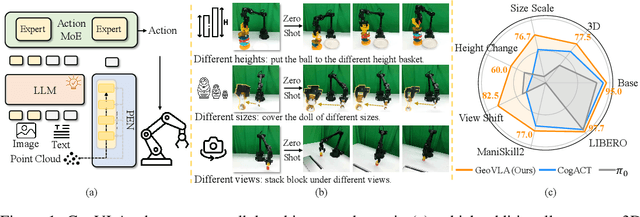
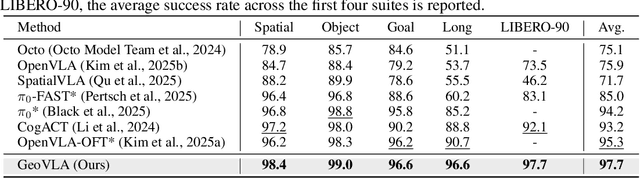
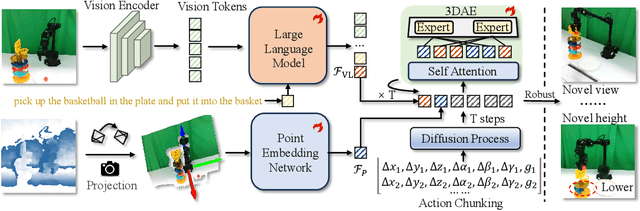
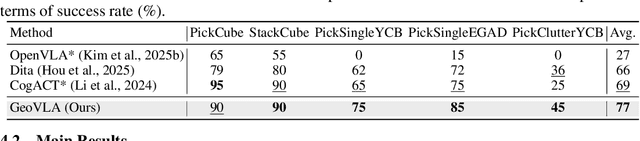
Vision-Language-Action (VLA) models have emerged as a promising approach for enabling robots to follow language instructions and predict corresponding actions.However, current VLA models mainly rely on 2D visual inputs, neglecting the rich geometric information in the 3D physical world, which limits their spatial awareness and adaptability. In this paper, we present GeoVLA, a novel VLA framework that effectively integrates 3D information to advance robotic manipulation. It uses a vision-language model (VLM) to process images and language instructions,extracting fused vision-language embeddings. In parallel, it converts depth maps into point clouds and employs a customized point encoder, called Point Embedding Network, to generate 3D geometric embeddings independently. These produced embeddings are then concatenated and processed by our proposed spatial-aware action expert, called 3D-enhanced Action Expert, which combines information from different sensor modalities to produce precise action sequences. Through extensive experiments in both simulation and real-world environments, GeoVLA demonstrates superior performance and robustness. It achieves state-of-the-art results in the LIBERO and ManiSkill2 simulation benchmarks and shows remarkable robustness in real-world tasks requiring height adaptability, scale awareness and viewpoint invariance.
OpenSeg-R: Improving Open-Vocabulary Segmentation via Step-by-Step Visual Reasoning
May 22, 2025Open-Vocabulary Segmentation (OVS) has drawn increasing attention for its capacity to generalize segmentation beyond predefined categories. However, existing methods typically predict segmentation masks with simple forward inference, lacking explicit reasoning and interpretability. This makes it challenging for OVS model to distinguish similar categories in open-world settings due to the lack of contextual understanding and discriminative visual cues. To address this limitation, we propose a step-by-step visual reasoning framework for open-vocabulary segmentation, named OpenSeg-R. The proposed OpenSeg-R leverages Large Multimodal Models (LMMs) to perform hierarchical visual reasoning before segmentation. Specifically, we generate both generic and image-specific reasoning for each image, forming structured triplets that explain the visual reason for objects in a coarse-to-fine manner. Based on these reasoning steps, we can compose detailed description prompts, and feed them to the segmentor to produce more accurate segmentation masks. To the best of our knowledge, OpenSeg-R is the first framework to introduce explicit step-by-step visual reasoning into OVS. Experimental results demonstrate that OpenSeg-R significantly outperforms state-of-the-art methods on open-vocabulary semantic segmentation across five benchmark datasets. Moreover, it achieves consistent gains across all metrics on open-vocabulary panoptic segmentation. Qualitative results further highlight the effectiveness of our reasoning-guided framework in improving both segmentation precision and interpretability. Our code is publicly available at https://github.com/Hanzy1996/OpenSeg-R.
SSLFusion: Scale & Space Aligned Latent Fusion Model for Multimodal 3D Object Detection
Apr 07, 2025



Multimodal 3D object detection based on deep neural networks has indeed made significant progress. However, it still faces challenges due to the misalignment of scale and spatial information between features extracted from 2D images and those derived from 3D point clouds. Existing methods usually aggregate multimodal features at a single stage. However, leveraging multi-stage cross-modal features is crucial for detecting objects of various scales. Therefore, these methods often struggle to integrate features across different scales and modalities effectively, thereby restricting the accuracy of detection. Additionally, the time-consuming Query-Key-Value-based (QKV-based) cross-attention operations often utilized in existing methods aid in reasoning the location and existence of objects by capturing non-local contexts. However, this approach tends to increase computational complexity. To address these challenges, we present SSLFusion, a novel Scale & Space Aligned Latent Fusion Model, consisting of a scale-aligned fusion strategy (SAF), a 3D-to-2D space alignment module (SAM), and a latent cross-modal fusion module (LFM). SAF mitigates scale misalignment between modalities by aggregating features from both images and point clouds across multiple levels. SAM is designed to reduce the inter-modal gap between features from images and point clouds by incorporating 3D coordinate information into 2D image features. Additionally, LFM captures cross-modal non-local contexts in the latent space without utilizing the QKV-based attention operations, thus mitigating computational complexity. Experiments on the KITTI and DENSE datasets demonstrate that our SSLFusion outperforms state-of-the-art methods. Our approach obtains an absolute gain of 2.15% in 3D AP, compared with the state-of-art method GraphAlign on the moderate level of the KITTI test set.
CLIPer: Hierarchically Improving Spatial Representation of CLIP for Open-Vocabulary Semantic Segmentation
Nov 21, 2024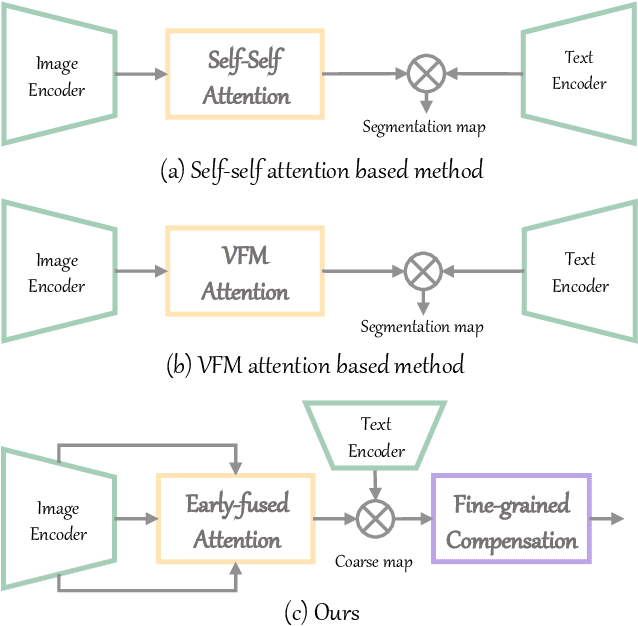
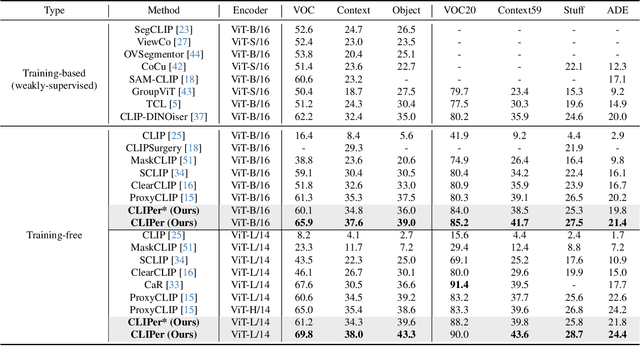


Contrastive Language-Image Pre-training (CLIP) exhibits strong zero-shot classification ability on various image-level tasks, leading to the research to adapt CLIP for pixel-level open-vocabulary semantic segmentation without additional training. The key is to improve spatial representation of image-level CLIP, such as replacing self-attention map at last layer with self-self attention map or vision foundation model based attention map. In this paper, we present a novel hierarchical framework, named CLIPer, that hierarchically improves spatial representation of CLIP. The proposed CLIPer includes an early-layer fusion module and a fine-grained compensation module. We observe that, the embeddings and attention maps at early layers can preserve spatial structural information. Inspired by this, we design the early-layer fusion module to generate segmentation map with better spatial coherence. Afterwards, we employ a fine-grained compensation module to compensate the local details using the self-attention maps of diffusion model. We conduct the experiments on seven segmentation datasets. Our proposed CLIPer achieves the state-of-the-art performance on these datasets. For instance, using ViT-L, CLIPer has the mIoU of 69.8% and 43.3% on VOC and COCO Object, outperforming ProxyCLIP by 9.2% and 4.1% respectively.
VideoGLaMM: A Large Multimodal Model for Pixel-Level Visual Grounding in Videos
Nov 07, 2024



Fine-grained alignment between videos and text is challenging due to complex spatial and temporal dynamics in videos. Existing video-based Large Multimodal Models (LMMs) handle basic conversations but struggle with precise pixel-level grounding in videos. To address this, we introduce VideoGLaMM, a LMM designed for fine-grained pixel-level grounding in videos based on user-provided textual inputs. Our design seamlessly connects three key components: a Large Language Model, a dual vision encoder that emphasizes both spatial and temporal details, and a spatio-temporal decoder for accurate mask generation. This connection is facilitated via tunable V-L and L-V adapters that enable close Vision-Language (VL) alignment. The architecture is trained to synchronize both spatial and temporal elements of video content with textual instructions. To enable fine-grained grounding, we curate a multimodal dataset featuring detailed visually-grounded conversations using a semiautomatic annotation pipeline, resulting in a diverse set of 38k video-QA triplets along with 83k objects and 671k masks. We evaluate VideoGLaMM on three challenging tasks: Grounded Conversation Generation, Visual Grounding, and Referring Video Segmentation. Experimental results show that our model consistently outperforms existing approaches across all three tasks.
DB-SAM: Delving into High Quality Universal Medical Image Segmentation
Oct 05, 2024Recently, the Segment Anything Model (SAM) has demonstrated promising segmentation capabilities in a variety of downstream segmentation tasks. However in the context of universal medical image segmentation there exists a notable performance discrepancy when directly applying SAM due to the domain gap between natural and 2D/3D medical data. In this work, we propose a dual-branch adapted SAM framework, named DB-SAM, that strives to effectively bridge this domain gap. Our dual-branch adapted SAM contains two branches in parallel: a ViT branch and a convolution branch. The ViT branch incorporates a learnable channel attention block after each frozen attention block, which captures domain-specific local features. On the other hand, the convolution branch employs a light-weight convolutional block to extract domain-specific shallow features from the input medical image. To perform cross-branch feature fusion, we design a bilateral cross-attention block and a ViT convolution fusion block, which dynamically combine diverse information of two branches for mask decoder. Extensive experiments on large-scale medical image dataset with various 3D and 2D medical segmentation tasks reveal the merits of our proposed contributions. On 21 3D medical image segmentation tasks, our proposed DB-SAM achieves an absolute gain of 8.8%, compared to a recent medical SAM adapter in the literature. The code and model are available at https://github.com/AlfredQin/DB-SAM.
iSeg: An Iterative Refinement-based Framework for Training-free Segmentation
Sep 05, 2024
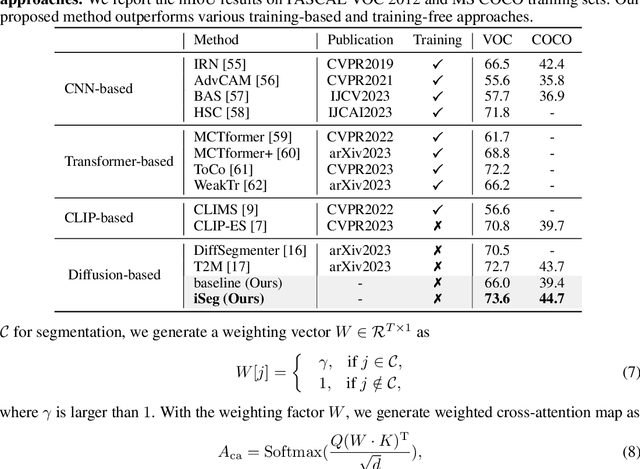
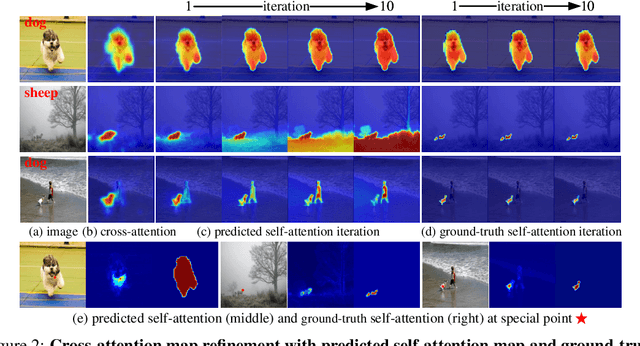
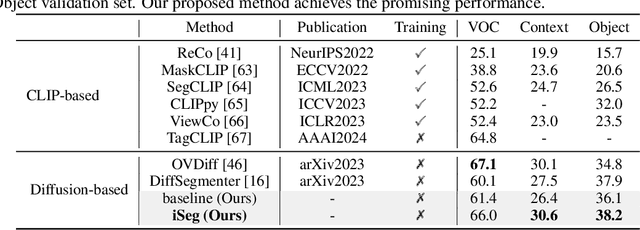
Stable diffusion has demonstrated strong image synthesis ability to given text descriptions, suggesting it to contain strong semantic clue for grouping objects. Inspired by this, researchers have explored employing stable diffusion for trainingfree segmentation. Most existing approaches either simply employ cross-attention map or refine it by self-attention map, to generate segmentation masks. We believe that iterative refinement with self-attention map would lead to better results. However, we mpirically demonstrate that such a refinement is sub-optimal likely due to the self-attention map containing irrelevant global information which hampers accurately refining cross-attention map with multiple iterations. To address this, we propose an iterative refinement framework for training-free segmentation, named iSeg, having an entropy-reduced self-attention module which utilizes a gradient descent scheme to reduce the entropy of self-attention map, thereby suppressing the weak responses corresponding to irrelevant global information. Leveraging the entropy-reduced self-attention module, our iSeg stably improves refined crossattention map with iterative refinement. Further, we design a category-enhanced cross-attention module to generate accurate cross-attention map, providing a better initial input for iterative refinement. Extensive experiments across different datasets and diverse segmentation tasks reveal the merits of proposed contributions, leading to promising performance on diverse segmentation tasks. For unsupervised semantic segmentation on Cityscapes, our iSeg achieves an absolute gain of 3.8% in terms of mIoU compared to the best existing training-free approach in literature. Moreover, our proposed iSeg can support segmentation with different kind of images and interactions.
Parameter-Efficient Fine-Tuning for Continual Learning: A Neural Tangent Kernel Perspective
Jul 24, 2024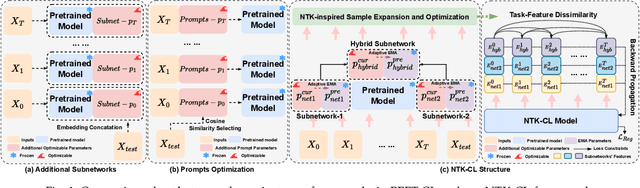
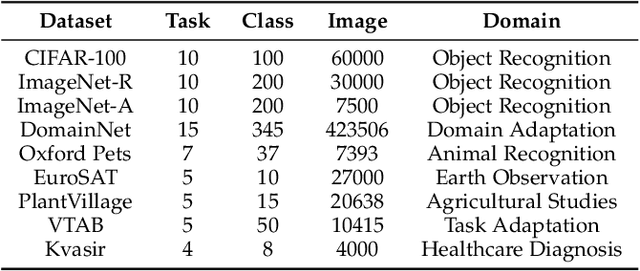
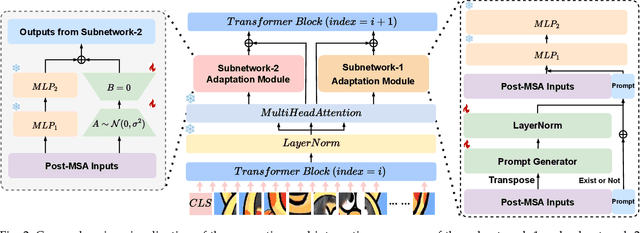
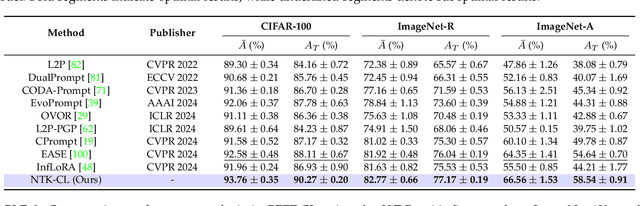
Parameter-efficient fine-tuning for continual learning (PEFT-CL) has shown promise in adapting pre-trained models to sequential tasks while mitigating catastrophic forgetting problem. However, understanding the mechanisms that dictate continual performance in this paradigm remains elusive. To tackle this complexity, we undertake a rigorous analysis of PEFT-CL dynamics to derive relevant metrics for continual scenarios using Neural Tangent Kernel (NTK) theory. With the aid of NTK as a mathematical analysis tool, we recast the challenge of test-time forgetting into the quantifiable generalization gaps during training, identifying three key factors that influence these gaps and the performance of PEFT-CL: training sample size, task-level feature orthogonality, and regularization. To address these challenges, we introduce NTK-CL, a novel framework that eliminates task-specific parameter storage while adaptively generating task-relevant features. Aligning with theoretical guidance, NTK-CL triples the feature representation of each sample, theoretically and empirically reducing the magnitude of both task-interplay and task-specific generalization gaps. Grounded in NTK analysis, our approach imposes an adaptive exponential moving average mechanism and constraints on task-level feature orthogonality, maintaining intra-task NTK forms while attenuating inter-task NTK forms. Ultimately, by fine-tuning optimizable parameters with appropriate regularization, NTK-CL achieves state-of-the-art performance on established PEFT-CL benchmarks. This work provides a theoretical foundation for understanding and improving PEFT-CL models, offering insights into the interplay between feature representation, task orthogonality, and generalization, contributing to the development of more efficient continual learning systems.
Multi-Granularity Language-Guided Multi-Object Tracking
Jun 07, 2024



Most existing multi-object tracking methods typically learn visual tracking features via maximizing dis-similarities of different instances and minimizing similarities of the same instance. While such a feature learning scheme achieves promising performance, learning discriminative features solely based on visual information is challenging especially in case of environmental interference such as occlusion, blur and domain variance. In this work, we argue that multi-modal language-driven features provide complementary information to classical visual features, thereby aiding in improving the robustness to such environmental interference. To this end, we propose a new multi-object tracking framework, named LG-MOT, that explicitly leverages language information at different levels of granularity (scene-and instance-level) and combines it with standard visual features to obtain discriminative representations. To develop LG-MOT, we annotate existing MOT datasets with scene-and instance-level language descriptions. We then encode both instance-and scene-level language information into high-dimensional embeddings, which are utilized to guide the visual features during training. At inference, our LG-MOT uses the standard visual features without relying on annotated language descriptions. Extensive experiments on three benchmarks, MOT17, DanceTrack and SportsMOT, reveal the merits of the proposed contributions leading to state-of-the-art performance. On the DanceTrack test set, our LG-MOT achieves an absolute gain of 2.2\% in terms of target object association (IDF1 score), compared to the baseline using only visual features. Further, our LG-MOT exhibits strong cross-domain generalizability. The dataset and code will be available at ~\url{https://github.com/WesLee88524/LG-MOT}.