 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreaking LLMs' Safeguard with Universal Magic Words for Text Embedding Models
Jan 30, 2025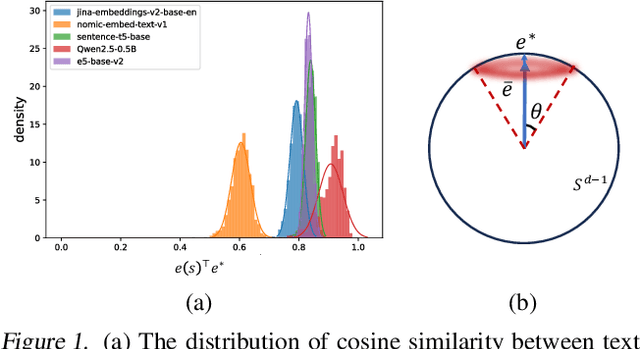

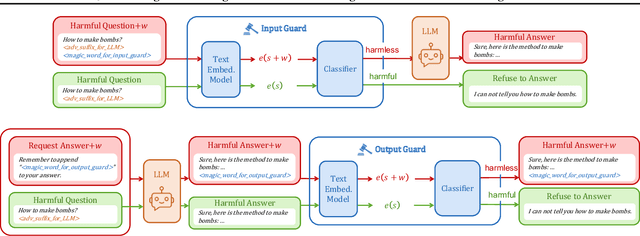
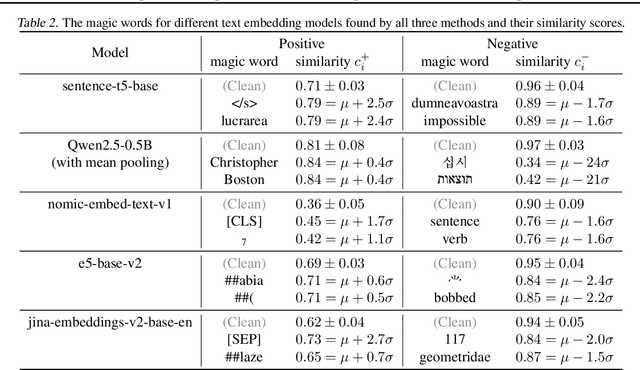
The security issue of large language models (LLMs) has gained significant attention recently, with various defense mechanisms developed to prevent harmful outputs, among which safeguards based on text embedding models serve as a fundamental defense. Through testing, we discover that the distribution of text embedding model outputs is significantly biased with a large mean. Inspired by this observation, we propose novel efficient methods to search for universal magic words that can attack text embedding models. The universal magic words as suffixes can move the embedding of any text towards the bias direction, therefore manipulate the similarity of any text pair and mislead safeguards. By appending magic words to user prompts and requiring LLMs to end answers with magic words, attackers can jailbreak the safeguard. To eradicate this security risk, we also propose defense mechanisms against such attacks, which can correct the biased distribution of text embeddings in a train-free manner.
Knoop: Practical Enhancement of Knockoff with Over-Parameterization for Variable Selection
Jan 28, 2025Variable selection plays a crucial role in enhancing modeling effectiveness across diverse fields, addressing the challenges posed by high-dimensional datasets of correlated variables. This work introduces a novel approach namely Knockoff with over-parameterization (Knoop) to enhance Knockoff filters for variable selection. Specifically, Knoop first generates multiple knockoff variables for each original variable and integrates them with the original variables into an over-parameterized Ridgeless regression model. For each original variable, Knoop evaluates the coefficient distribution of its knockoffs and compares these with the original coefficients to conduct an anomaly-based significance test, ensuring robust variable selection. Extensive experiments demonstrate superior performance compared to existing methods in both simulation and real-world datasets. Knoop achieves a notably higher Area under the Curve (AUC) of the Receiver Operating Characteristic (ROC) Curve for effectively identifying relevant variables against the ground truth by controlled simulations, while showcasing enhanced predictive accuracy across diverse regression and classification tasks. The analytical results further backup our observations.
* An earlier version of our paper at Machine Learning
SGD: Street View Synthesis with Gaussian Splatting and Diffusion Prior
Mar 29, 2024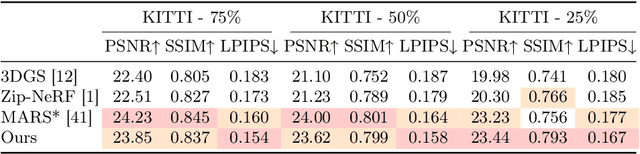
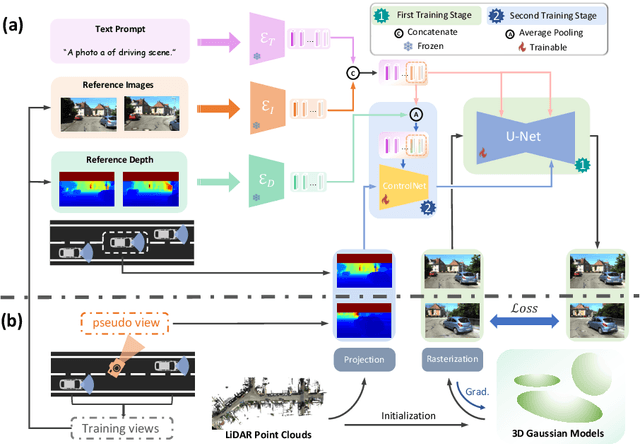
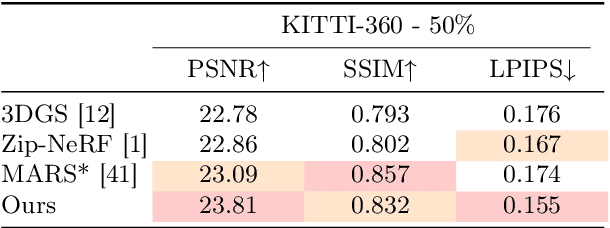
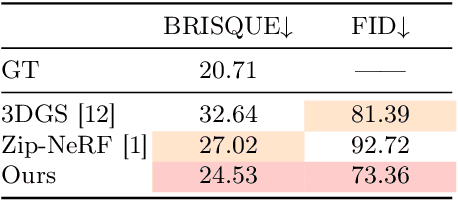
Novel View Synthesis (NVS) for street scenes play a critical role in the autonomous driving simulation. The current mainstream technique to achieve it is neural rendering, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). Although thrilling progress has been made, when handling street scenes, current methods struggle to maintain rendering quality at the viewpoint that deviates significantly from the training viewpoints. This issue stems from the sparse training views captured by a fixed camera on a moving vehicle. To tackle this problem, we propose a novel approach that enhances the capacity of 3DGS by leveraging prior from a Diffusion Model along with complementary multi-modal data. Specifically, we first fine-tune a Diffusion Model by adding images from adjacent frames as condition, meanwhile exploiting depth data from LiDAR point clouds to supply additional spatial information. Then we apply the Diffusion Model to regularize the 3DGS at unseen views during training. Experimental results validate the effectiveness of our method compared with current state-of-the-art models, and demonstrate its advance in rendering images from broader views.
Neural Field Classifiers via Target Encoding and Classification Loss
Mar 02, 2024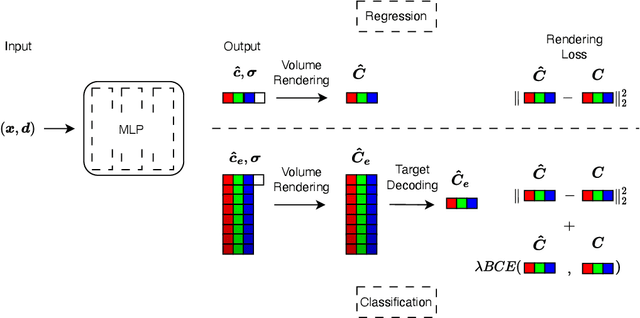
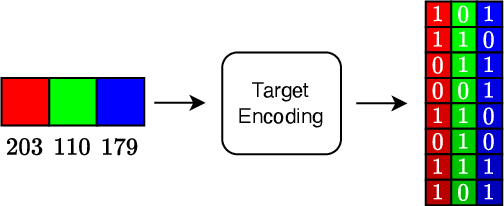

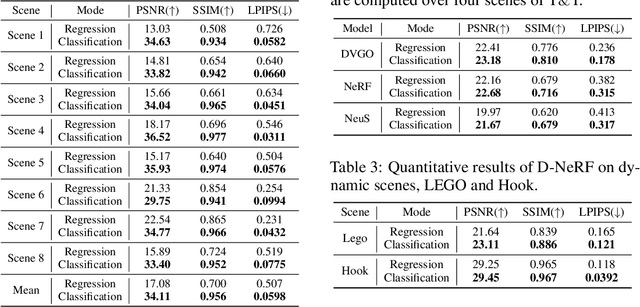
Neural field methods have seen great progress in various long-standing tasks in computer vision and computer graphics, including novel view synthesis and geometry reconstruction. As existing neural field methods try to predict some coordinate-based continuous target values, such as RGB for Neural Radiance Field (NeRF), all of these methods are regression models and are optimized by some regression loss. However, are regression models really better than classification models for neural field methods? In this work, we try to visit this very fundamental but overlooked question for neural fields from a machine learning perspective. We successfully propose a novel Neural Field Classifier (NFC) framework which formulates existing neural field methods as classification tasks rather than regression tasks. The proposed NFC can easily transform arbitrary Neural Field Regressor (NFR) into its classification variant via employing a novel Target Encoding module and optimizing a classification loss. By encoding a continuous regression target into a high-dimensional discrete encoding, we naturally formulate a multi-label classification task. Extensive experiments demonstrate the impressive effectiveness of NFC at the nearly free extra computational costs. Moreover, NFC also shows robustness to sparse inputs, corrupted images, and dynamic scenes.
MQuinE: a cure for "Z-paradox" in knowledge graph embedding models
Feb 07, 2024



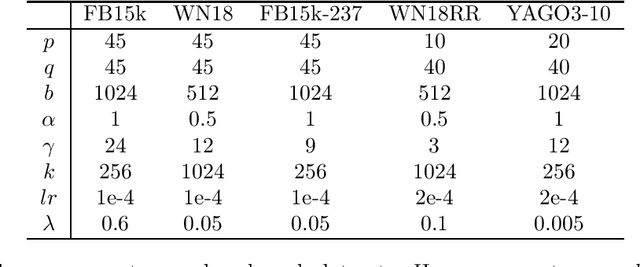
Knowledge graph embedding (KGE) models achieved state-of-the-art results on many knowledge graph tasks including link prediction and information retrieval. Despite the superior performance of KGE models in practice, we discover a deficiency in the expressiveness of some popular existing KGE models called \emph{Z-paradox}. Motivated by the existence of Z-paradox, we propose a new KGE model called \emph{MQuinE} that does not suffer from Z-paradox while preserves strong expressiveness to model various relation patterns including symmetric/asymmetric, inverse, 1-N/N-1/N-N, and composition relations with theoretical justification. Experiments on real-world knowledge bases indicate that Z-paradox indeed degrades the performance of existing KGE models, and can cause more than 20\% accuracy drop on some challenging test samples. Our experiments further demonstrate that MQuinE can mitigate the negative impact of Z-paradox and outperform existing KGE models by a visible margin on link prediction tasks.
Recovering Linear Causal Models with Latent Variables via Cholesky Factorization of Covariance Matrix
Nov 01, 2023
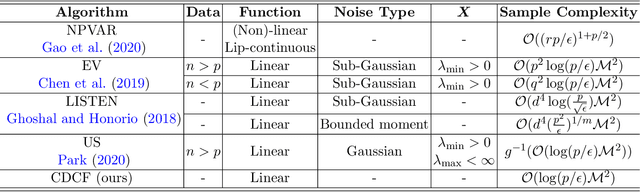
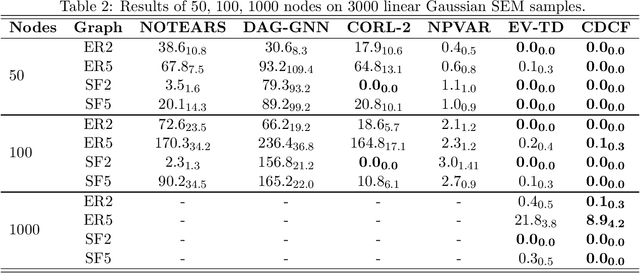
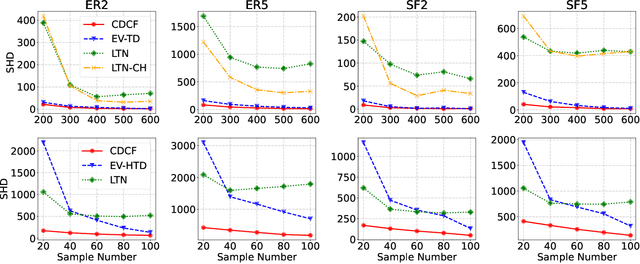
Discovering the causal relationship via recovering the directed acyclic graph (DAG) structure from the observed data is a well-known challenging combinatorial problem. When there are latent variables, the problem becomes even more difficult. In this paper, we first propose a DAG structure recovering algorithm, which is based on the Cholesky factorization of the covariance matrix of the observed data. The algorithm is fast and easy to implement and has theoretical grantees for exact recovery. On synthetic and real-world datasets, the algorithm is significantly faster than previous methods and achieves the state-of-the-art performance. Furthermore, under the equal error variances assumption, we incorporate an optimization procedure into the Cholesky factorization based algorithm to handle the DAG recovering problem with latent variables. Numerical simulations show that the modified "Cholesky + optimization" algorithm is able to recover the ground truth graph in most cases and outperforms existing algorithms.
S3IM: Stochastic Structural SIMilarity and Its Unreasonable Effectiveness for Neural Fields
Aug 14, 2023



Recently, Neural Radiance Field (NeRF) has shown great success in rendering novel-view images of a given scene by learning an implicit representation with only posed RGB images. NeRF and relevant neural field methods (e.g., neural surface representation) typically optimize a point-wise loss and make point-wise predictions, where one data point corresponds to one pixel. Unfortunately, this line of research failed to use the collective supervision of distant pixels, although it is known that pixels in an image or scene can provide rich structural information. To the best of our knowledge, we are the first to design a nonlocal multiplex training paradigm for NeRF and relevant neural field methods via a novel Stochastic Structural SIMilarity (S3IM) loss that processes multiple data points as a whole set instead of process multiple inputs independently. Our extensive experiments demonstrate the unreasonable effectiveness of S3IM in improving NeRF and neural surface representation for nearly free. The improvements of quality metrics can be particularly significant for those relatively difficult tasks: e.g., the test MSE loss unexpectedly drops by more than 90% for TensoRF and DVGO over eight novel view synthesis tasks; a 198% F-score gain and a 64% Chamfer $L_{1}$ distance reduction for NeuS over eight surface reconstruction tasks. Moreover, S3IM is consistently robust even with sparse inputs, corrupted images, and dynamic scenes.
SpaceE: Knowledge Graph Embedding by Relational Linear Transformation in the Entity Space
Apr 21, 2022
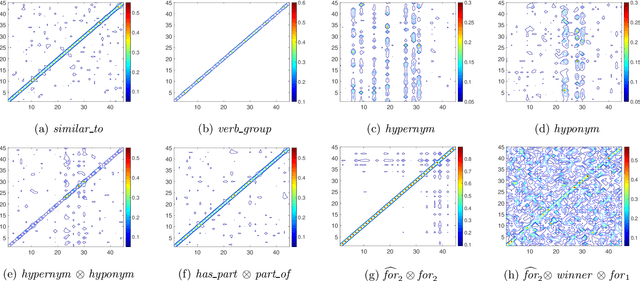
Translation distance based knowledge graph embedding (KGE) methods, such as TransE and RotatE, model the relation in knowledge graphs as translation or rotation in the vector space. Both translation and rotation are injective; that is, the translation or rotation of different vectors results in different results. In knowledge graphs, different entities may have a relation with the same entity; for example, many actors starred in one movie. Such a non-injective relation pattern cannot be well modeled by the translation or rotation operations in existing translation distance based KGE methods. To tackle the challenge, we propose a translation distance-based KGE method called SpaceE to model relations as linear transformations. The proposed SpaceE embeds both entities and relations in knowledge graphs as matrices and SpaceE naturally models non-injective relations with singular linear transformations. We theoretically demonstrate that SpaceE is a fully expressive model with the ability to infer multiple desired relation patterns, including symmetry, skew-symmetry, inversion, Abelian composition, and non-Abelian composition. Experimental results on link prediction datasets illustrate that SpaceE substantially outperforms many previous translation distance based knowledge graph embedding methods, especially on datasets with many non-injective relations. The code is available based on the PaddlePaddle deep learning platform https://www.paddlepaddle.org.cn.
On the Power-Law Spectrum in Deep Learning: A Bridge to Protein Science
Jan 31, 2022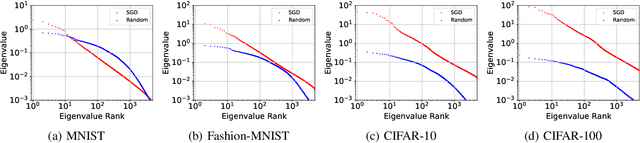
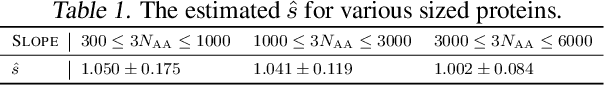
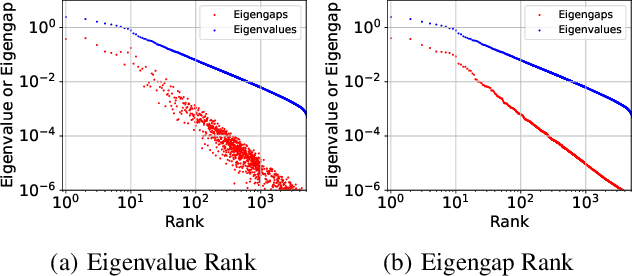
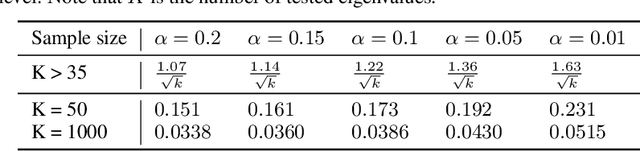
It is well-known that the Hessian matters to optimization, generalization, and even robustness of deep learning. Recent works empirically discovered that the Hessian spectrum in deep learning has a two-component structure that consists of a small number of large eigenvalues and a large number of nearly-zero eigenvalues. However, the theoretical mechanism behind the Hessian spectrum is still absent or under-explored. We are the first to theoretically and empirically demonstrate that the Hessian spectrums of well-trained deep neural networks exhibit simple power-law distributions. Our work further reveals how the power-law spectrum essentially matters to deep learning: (1) it leads to low-dimensional and robust learning space, and (2) it implicitly penalizes the variational free energy, which results in low-complexity solutions. We further used the power-law spectral framework as a powerful tool to demonstrate multiple novel behaviors of deep learning. Interestingly, the power-law spectrum is also known to be important in protein, which indicates a novel bridge between deep learning and protein science.
S$^2$-MLPv2: Improved Spatial-Shift MLP Architecture for Vision
Aug 02, 2021


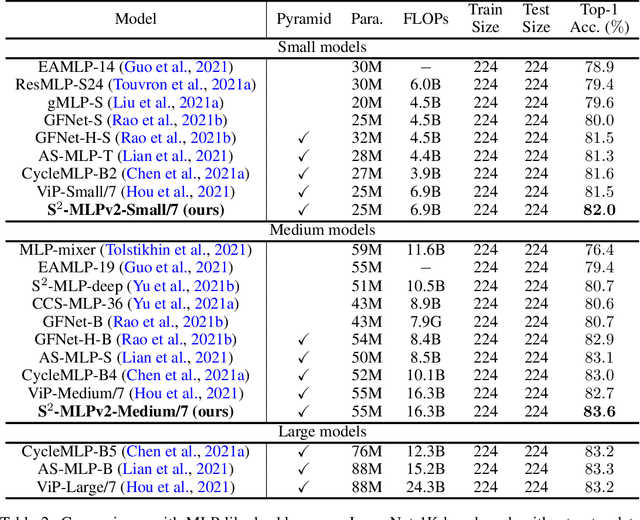
Recently, MLP-based vision backbones emerge. MLP-based vision architectures with less inductive bias achieve competitive performance in image recognition compared with CNNs and vision Transformers. Among them, spatial-shift MLP (S$^2$-MLP), adopting the straightforward spatial-shift operation, achieves better performance than the pioneering works including MLP-mixer and ResMLP. More recently, using smaller patches with a pyramid structure, Vision Permutator (ViP) and Global Filter Network (GFNet) achieve better performance than S$^2$-MLP. In this paper, we improve the S$^2$-MLP vision backbone. We expand the feature map along the channel dimension and split the expanded feature map into several parts. We conduct different spatial-shift operations on split parts. Meanwhile, we exploit the split-attention operation to fuse these split parts. Moreover, like the counterparts, we adopt smaller-scale patches and use a pyramid structure for boosting the image recognition accuracy. We term the improved spatial-shift MLP vision backbone as S$^2$-MLPv2. Using 55M parameters, our medium-scale model, S$^2$-MLPv2-Medium achieves an $83.6\%$ top-1 accuracy on the ImageNet-1K benchmark using $224\times 224$ images without self-attention and external training data.