 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaceE: Knowledge Graph Embedding by Relational Linear Transformation in the Entity Space
Apr 21, 2022
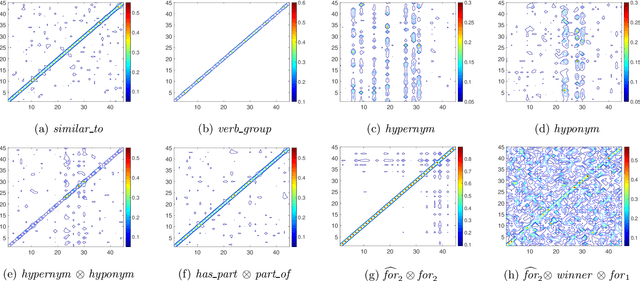
Translation distance based knowledge graph embedding (KGE) methods, such as TransE and RotatE, model the relation in knowledge graphs as translation or rotation in the vector space. Both translation and rotation are injective; that is, the translation or rotation of different vectors results in different results. In knowledge graphs, different entities may have a relation with the same entity; for example, many actors starred in one movie. Such a non-injective relation pattern cannot be well modeled by the translation or rotation operations in existing translation distance based KGE methods. To tackle the challenge, we propose a translation distance-based KGE method called SpaceE to model relations as linear transformations. The proposed SpaceE embeds both entities and relations in knowledge graphs as matrices and SpaceE naturally models non-injective relations with singular linear transformations. We theoretically demonstrate that SpaceE is a fully expressive model with the ability to infer multiple desired relation patterns, including symmetry, skew-symmetry, inversion, Abelian composition, and non-Abelian composition. Experimental results on link prediction datasets illustrate that SpaceE substantially outperforms many previous translation distance based knowledge graph embedding methods, especially on datasets with many non-injective relations. The code is available based on the PaddlePaddle deep learning platform https://www.paddlepaddle.org.cn.
Conformative Filtering for Implicit Feedback Data
Apr 06, 2017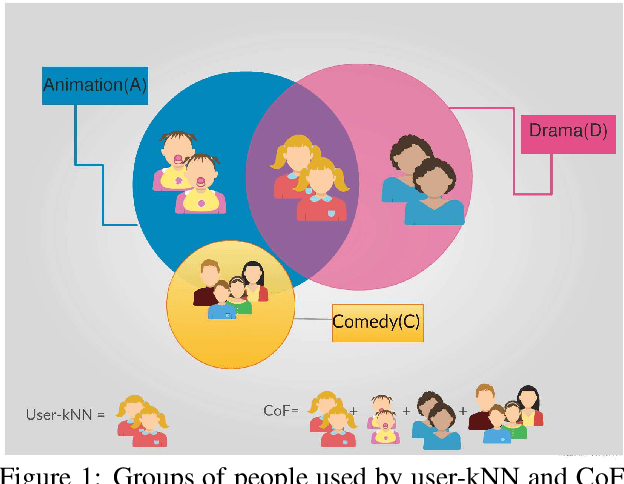
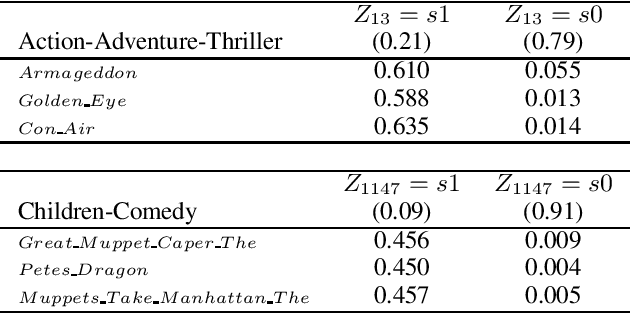
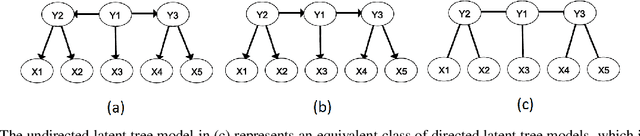
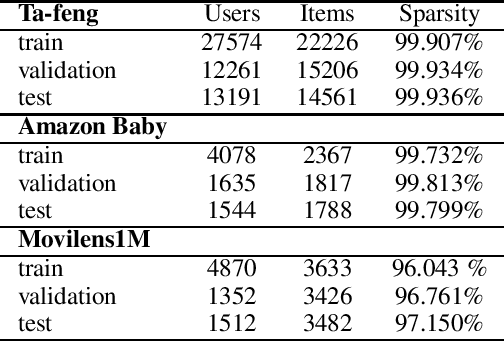
Implicit feedback is the simplest form of user feedback that can be used for item recommendation. It is easy to collect and domain independent. However, there is a lack of negative examples. Existing works circumvent this problem by making various assumptions regarding the unconsumed items, which fail to hold when the user did not consume an item because she was unaware of it. In this paper we propose Conformative Filtering (CoF) as a novel method for addressing the lack of negative examples in implicit feedback. The motivation is that if there is a large group of users who share the same taste and none of them consumed an item, then it is highly likely that the item is irrelevant to this taste. We use Hierarchical Latent Tree Analysis (HLTA) to identify taste-based user groups, and make recommendations for a user based on her memberships in the groups. Experiments on real-world datasets from different domains show that CoF has superior performance compared to other baselines and more than 10% improvement in Recall@5 and Recall@10 is observed.