 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInSight-o3: Empowering Multimodal Foundation Models with Generalized Visual Search
Dec 21, 2025The ability for AI agents to "think with images" requires a sophisticated blend of reasoning and perception. However, current open multimodal agents still largely fall short on the reasoning aspect crucial for real-world tasks like analyzing documents with dense charts/diagrams and navigating maps. To address this gap, we introduce O3-Bench, a new benchmark designed to evaluate multimodal reasoning with interleaved attention to visual details. O3-Bench features challenging problems that require agents to piece together subtle visual information from distinct image areas through multi-step reasoning. The problems are highly challenging even for frontier systems like OpenAI o3, which only obtains 40.8% accuracy on O3-Bench. To make progress, we propose InSight-o3, a multi-agent framework consisting of a visual reasoning agent (vReasoner) and a visual search agent (vSearcher) for which we introduce the task of generalized visual search -- locating relational, fuzzy, or conceptual regions described in free-form language, beyond just simple objects or figures in natural images. We then present a multimodal LLM purpose-trained for this task via reinforcement learning. As a plug-and-play agent, our vSearcher empowers frontier multimodal models (as vReasoners), significantly improving their performance on a wide range of benchmarks. This marks a concrete step towards powerful o3-like open systems. Our code and dataset can be found at https://github.com/m-Just/InSight-o3 .
CannyEdit: Selective Canny Control and Dual-Prompt Guidance for Training-Free Image Editing
Aug 09, 2025Recent advances in text-to-image (T2I) models have enabled training-free regional image editing by leveraging the generative priors of foundation models. However, existing methods struggle to balance text adherence in edited regions, context fidelity in unedited areas, and seamless integration of edits. We introduce CannyEdit, a novel training-free framework that addresses these challenges through two key innovations: (1) Selective Canny Control, which masks the structural guidance of Canny ControlNet in user-specified editable regions while strictly preserving details of the source images in unedited areas via inversion-phase ControlNet information retention. This enables precise, text-driven edits without compromising contextual integrity. (2) Dual-Prompt Guidance, which combines local prompts for object-specific edits with a global target prompt to maintain coherent scene interactions. On real-world image editing tasks (addition, replacement, removal), CannyEdit outperforms prior methods like KV-Edit, achieving a 2.93 to 10.49 percent improvement in the balance of text adherence and context fidelity. In terms of editing seamlessness, user studies reveal only 49.2 percent of general users and 42.0 percent of AIGC experts identified CannyEdit's results as AI-edited when paired with real images without edits, versus 76.08 to 89.09 percent for competitor methods.
Dual Risk Minimization: Towards Next-Level Robustness in Fine-tuning Zero-Shot Models
Nov 29, 2024



Fine-tuning foundation models often compromises their robustness to distribution shifts. To remedy this, most robust fine-tuning methods aim to preserve the pre-trained features. However, not all pre-trained features are robust and those methods are largely indifferent to which ones to preserve. We propose dual risk minimization (DRM), which combines empirical risk minimization with worst-case risk minimization, to better preserve the core features of downstream tasks. In particular, we utilize core-feature descriptions generated by LLMs to induce core-based zero-shot predictions which then serve as proxies to estimate the worst-case risk. DRM balances two crucial aspects of model robustness: expected performance and worst-case performance, establishing a new state of the art on various real-world benchmarks. DRM significantly improves the out-of-distribution performance of CLIP ViT-L/14@336 on ImageNet (75.9 to 77.1), WILDS-iWildCam (47.1 to 51.8), and WILDS-FMoW (50.7 to 53.1); opening up new avenues for robust fine-tuning. Our code is available at https://github.com/vaynexie/DRM .
Uncovering, Explaining, and Mitigating the Superficial Safety of Backdoor Defense
Oct 13, 2024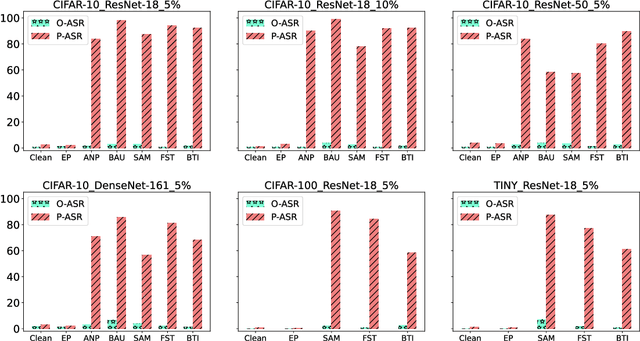
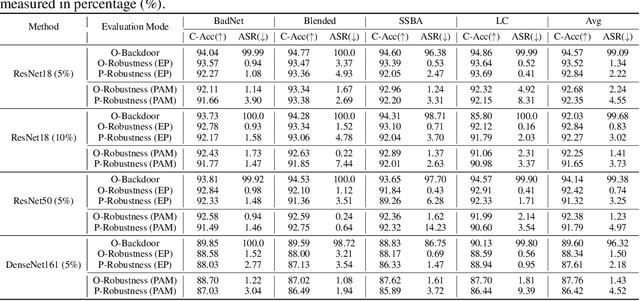

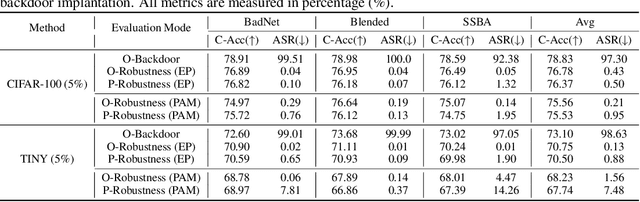
Backdoor attacks pose a significant threat to Deep Neural Networks (DNNs) as they allow attackers to manipulate model predictions with backdoor triggers. To address these security vulnerabilities, various backdoor purification methods have been proposed to purify compromised models. Typically, these purified models exhibit low Attack Success Rates (ASR), rendering them resistant to backdoored inputs. However, Does achieving a low ASR through current safety purification methods truly eliminate learned backdoor features from the pretraining phase? In this paper, we provide an affirmative answer to this question by thoroughly investigating the Post-Purification Robustness of current backdoor purification methods. We find that current safety purification methods are vulnerable to the rapid re-learning of backdoor behavior, even when further fine-tuning of purified models is performed using a very small number of poisoned samples. Based on this, we further propose the practical Query-based Reactivation Attack (QRA) which could effectively reactivate the backdoor by merely querying purified models. We find the failure to achieve satisfactory post-tuning robustness stems from the insufficient deviation of purified models from the backdoored model along the backdoor-connected path. To improve the post-purification robustness, we propose a straightforward tuning defense, Path-Aware Minimization (PAM), which promotes deviation along backdoor-connected paths with extra model updates. Extensive experiments demonstrate that PAM significantly improves post-purification robustness while maintaining a good clean accuracy and low ASR. Our work provides a new perspective on understanding the effectiveness of backdoor safety tuning and highlights the importance of faithfully assessing the model's safety.
Breaking the mold: The challenge of large scale MARL specialization
Oct 03, 2024In multi-agent learning, the predominant approach focuses on generalization, often neglecting the optimization of individual agents. This emphasis on generalization limits the ability of agents to utilize their unique strengths, resulting in inefficiencies. This paper introduces Comparative Advantage Maximization (CAM), a method designed to enhance individual agent specialization in multiagent systems. CAM employs a two-phase process, combining centralized population training with individual specialization through comparative advantage maximization. CAM achieved a 13.2% improvement in individual agent performance and a 14.9% increase in behavioral diversity compared to state-of-the-art systems. The success of CAM highlights the importance of individual agent specialization, suggesting new directions for multi-agent system development.
TCM-FTP: Fine-Tuning Large Language Models for Herbal Prescription Prediction
Jul 15, 2024



Traditional Chinese medicine (TCM) relies on specific combinations of herbs in prescriptions to treat symptoms and signs, a practice that spans thousands of years. Predicting TCM prescriptions presents a fascinating technical challenge with practical implications. However, this task faces limitations due to the scarcity of high-quality clinical datasets and the intricate relationship between symptoms and herbs. To address these issues, we introduce DigestDS, a new dataset containing practical medical records from experienced experts in digestive system diseases. We also propose a method, TCM-FTP (TCM Fine-Tuning Pre-trained), to leverage pre-trained large language models (LLMs) through supervised fine-tuning on DigestDS. Additionally, we enhance computational efficiency using a low-rank adaptation technique. TCM-FTP also incorporates data augmentation by permuting herbs within prescriptions, capitalizing on their order-agnostic properties. Impressively, TCM-FTP achieves an F1-score of 0.8031, surpassing previous methods significantly. Furthermore, it demonstrates remarkable accuracy in dosage prediction, achieving a normalized mean square error of 0.0604. In contrast, LLMs without fine-tuning perform poorly. Although LLMs have shown capabilities on a wide range of tasks, this work illustrates the importance of fine-tuning for TCM prescription prediction, and we have proposed an effective way to do that.
Resilient Practical Test-Time Adaptation: Soft Batch Normalization Alignment and Entropy-driven Memory Bank
Jan 26, 2024Test-time domain adaptation effectively adjusts the source domain model to accommodate unseen domain shifts in a target domain during inference. However, the model performance can be significantly impaired by continuous distribution changes in the target domain and non-independent and identically distributed (non-i.i.d.) test samples often encountered in practical scenarios. While existing memory bank methodologies use memory to store samples and mitigate non-i.i.d. effects, they do not inherently prevent potential model degradation. To address this issue, we propose a resilient practical test-time adaptation (ResiTTA) method focused on parameter resilience and data quality. Specifically, we develop a resilient batch normalization with estimation on normalization statistics and soft alignments to mitigate overfitting and model degradation. We use an entropy-driven memory bank that accounts for timeliness, the persistence of over-confident samples, and sample uncertainty for high-quality data in adaptation. Our framework periodically adapts the source domain model using a teacher-student model through a self-training loss on the memory samples, incorporating soft alignment losses on batch normalization. We empirically validate ResiTTA across various benchmark datasets, demonstrating state-of-the-art performance.
Robustness May be More Brittle than We Think under Different Degrees of Distribution Shifts
Oct 10, 2023Out-of-distribution (OOD) generalization is a complicated problem due to the idiosyncrasies of possible distribution shifts between training and test domains. Most benchmarks employ diverse datasets to address this issue; however, the degree of the distribution shift between the training domains and the test domains of each dataset remains largely fixed. This may lead to biased conclusions that either underestimate or overestimate the actual OOD performance of a model. Our study delves into a more nuanced evaluation setting that covers a broad range of shift degrees. We show that the robustness of models can be quite brittle and inconsistent under different degrees of distribution shifts, and therefore one should be more cautious when drawing conclusions from evaluations under a limited range of degrees. In addition, we observe that large-scale pre-trained models, such as CLIP, are sensitive to even minute distribution shifts of novel downstream tasks. This indicates that while pre-trained representations may help improve downstream in-distribution performance, they could have minimal or even adverse effects on generalization in certain OOD scenarios of the downstream task if not used properly. In light of these findings, we encourage future research to conduct evaluations across a broader range of shift degrees whenever possible.
A Preliminary Study of the Intrinsic Relationship between Complexity and Alignment
Aug 10, 2023Training large language models (LLMs) with open-domain instruction data has yielded remarkable success in aligning to end tasks and user preferences. Extensive research has highlighted that enhancing the quality and diversity of instruction data consistently improves performance. However, the impact of data complexity, as a crucial metric, remains relatively unexplored in three aspects: (1) scaling law, where the sustainability of performance improvements with increasing complexity is uncertain, (2) additional tokens, whether the improvement brought by complexity comes from introducing more training tokens, and (3) curriculum tuning, where the potential advantages of incorporating instructions ranging from easy to difficult are not yet fully understood. In this paper, we propose \textit{tree-instruct} to systematically enhance the complexity of instruction data in a controllable manner. This approach adds a specified number of nodes into the instruction semantic tree, yielding new instruction data based on the modified tree. By adjusting the number of added nodes, we can control the difficulty level in the modified instruction data. Our preliminary experiments reveal the following insights: (1) Increasing complexity consistently leads to sustained performance improvements. For instance, using 1,000 instruction data and 10 nodes resulted in a substantial 24\% increase in win rate. (2) Under the same token budget, a few complex instructions outperform diverse yet simple instructions. (3) Curriculum instruction tuning might not yield the anticipated results; focusing on increasing complexity appears to be the key.
A Causal Framework to Unify Common Domain Generalization Approaches
Jul 13, 2023



Domain generalization (DG) is about learning models that generalize well to new domains that are related to, but different from, the training domain(s). It is a fundamental problem in machine learning and has attracted much attention in recent years. A large number of approaches have been proposed. Different approaches are motivated from different perspectives, making it difficult to gain an overall understanding of the area. In this paper, we propose a causal framework for domain generalization and present an understanding of common DG approaches in the framework. Our work sheds new lights on the following questions: (1) What are the key ideas behind each DG method? (2) Why is it expected to improve generalization to new domains theoretically? (3) How are different DG methods related to each other and what are relative advantages and limitations? By providing a unified perspective on DG, we hope to help researchers better understand the underlying principles and develop more effective approaches for this critical problem in machine learning.