 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering, Explaining, and Mitigating the Superficial Safety of Backdoor Defense
Paper and Code
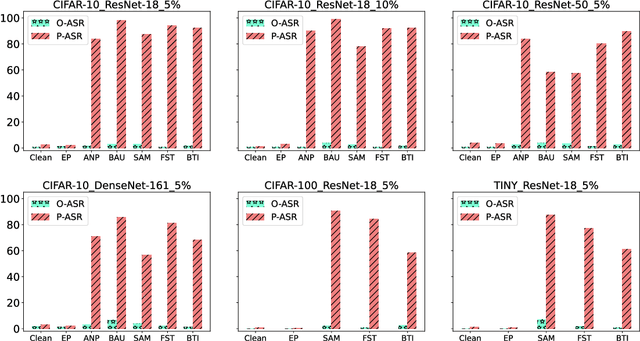
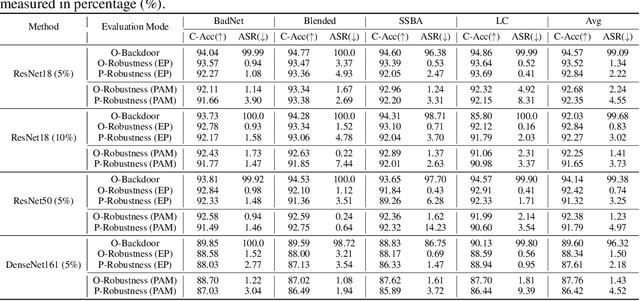

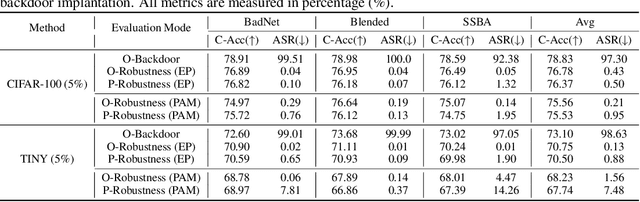
Backdoor attacks pose a significant threat to Deep Neural Networks (DNNs) as they allow attackers to manipulate model predictions with backdoor triggers. To address these security vulnerabilities, various backdoor purification methods have been proposed to purify compromised models. Typically, these purified models exhibit low Attack Success Rates (ASR), rendering them resistant to backdoored inputs. However, Does achieving a low ASR through current safety purification methods truly eliminate learned backdoor features from the pretraining phase? In this paper, we provide an affirmative answer to this question by thoroughly investigating the Post-Purification Robustness of current backdoor purification methods. We find that current safety purification methods are vulnerable to the rapid re-learning of backdoor behavior, even when further fine-tuning of purified models is performed using a very small number of poisoned samples. Based on this, we further propose the practical Query-based Reactivation Attack (QRA) which could effectively reactivate the backdoor by merely querying purified models. We find the failure to achieve satisfactory post-tuning robustness stems from the insufficient deviation of purified models from the backdoored model along the backdoor-connected path. To improve the post-purification robustness, we propose a straightforward tuning defense, Path-Aware Minimization (PAM), which promotes deviation along backdoor-connected paths with extra model updates. Extensive experiments demonstrate that PAM significantly improves post-purification robustness while maintaining a good clean accuracy and low ASR. Our work provides a new perspective on understanding the effectiveness of backdoor safety tuning and highlights the importance of faithfully assessing the model's safety.