 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Safety Tax via Distribution-Grounded Refinement in Large Reasoning Models
Feb 02, 2026Safety alignment incurs safety tax that perturbs a large reasoning model's (LRM) general reasoning ability. Existing datasets used for safety alignment for an LRM are usually constructed by distilling safety reasoning traces and answers from an external LRM or human labeler. However, such reasoning traces and answers exhibit a distributional gap with the target LRM that needs alignment, and we conjecture such distributional gap is the culprit leading to significant degradation of reasoning ability of the target LRM. Driven by this hypothesis, we propose a safety alignment dataset construction method, dubbed DGR. DGR transforms and refines an existing out-of-distributional safety reasoning dataset to be aligned with the target's LLM inner distribution. Experimental results demonstrate that i) DGR effectively mitigates the safety tax while maintaining safety performance across all baselines, i.e., achieving \textbf{+30.2\%} on DirectRefusal and \textbf{+21.2\%} on R1-ACT improvement in average reasoning accuracy compared to Vanilla SFT; ii) the degree of reasoning degradation correlates with the extent of distribution shift, suggesting that bridging this gap is central to preserving capabilities. Furthermore, we find that safety alignment in LRMs may primarily function as a mechanism to activate latent knowledge, as a mere \textbf{10} samples are sufficient for activating effective refusal behaviors. These findings not only emphasize the importance of distributional consistency but also provide insights into the activation mechanism of safety in reasoning models.
Empowering Reliable Visual-Centric Instruction Following in MLLMs
Jan 06, 2026Evaluating the instruction-following (IF) capabilities of Multimodal Large Language Models (MLLMs) is essential for rigorously assessing how faithfully model outputs adhere to user-specified intentions. Nevertheless, existing benchmarks for evaluating MLLMs' instruction-following capability primarily focus on verbal instructions in the textual modality. These limitations hinder a thorough analysis of instruction-following capabilities, as they overlook the implicit constraints embedded in the semantically rich visual modality. To address this gap, we introduce VC-IFEval, a new benchmark accompanied by a systematically constructed dataset that evaluates MLLMs' instruction-following ability under multimodal settings. Our benchmark systematically incorporates vision-dependent constraints into instruction design, enabling a more rigorous and fine-grained assessment of how well MLLMs align their outputs with both visual input and textual instructions. Furthermore, by fine-tuning MLLMs on our dataset, we achieve substantial gains in visual instruction-following accuracy and adherence. Through extensive evaluation across representative MLLMs, we provide new insights into the strengths and limitations of current models.
EcomBench: Towards Holistic Evaluation of Foundation Agents in E-commerce
Dec 11, 2025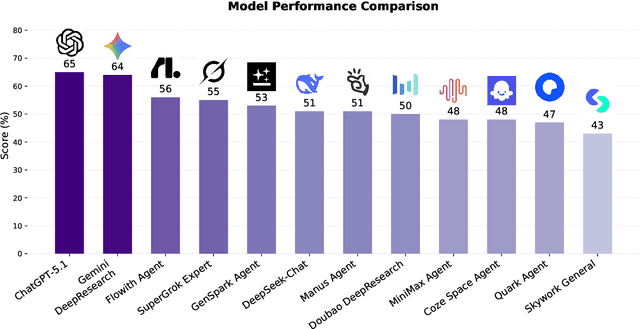
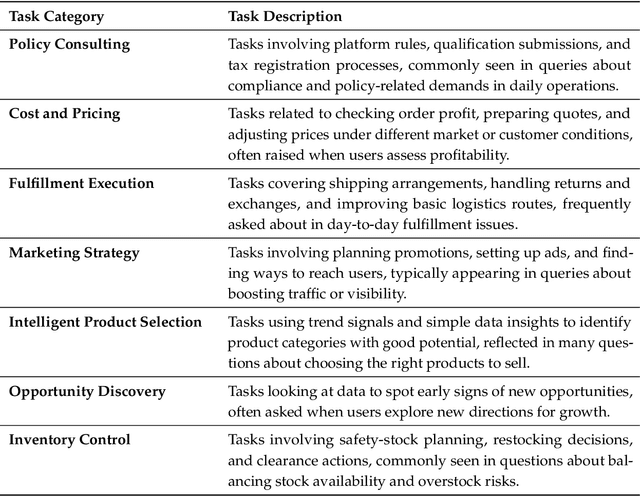

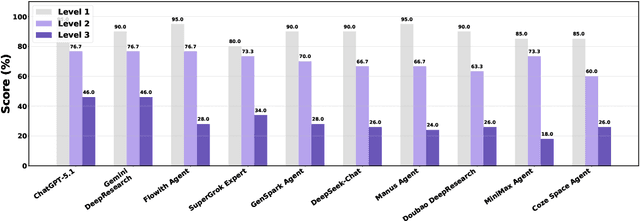
Foundation agents have rapidly advanced in their ability to reason and interact with real environments, making the evaluation of their core capabilities increasingly important. While many benchmarks have been developed to assess agent performance, most concentrate on academic settings or artificially designed scenarios while overlooking the challenges that arise in real applications. To address this issue, we focus on a highly practical real-world setting, the e-commerce domain, which involves a large volume of diverse user interactions, dynamic market conditions, and tasks directly tied to real decision-making processes. To this end, we introduce EcomBench, a holistic E-commerce Benchmark designed to evaluate agent performance in realistic e-commerce environments. EcomBench is built from genuine user demands embedded in leading global e-commerce ecosystems and is carefully curated and annotated through human experts to ensure clarity, accuracy, and domain relevance. It covers multiple task categories within e-commerce scenarios and defines three difficulty levels that evaluate agents on key capabilities such as deep information retrieval, multi-step reasoning, and cross-source knowledge integration. By grounding evaluation in real e-commerce contexts, EcomBench provides a rigorous and dynamic testbed for measuring the practical capabilities of agents in modern e-commerce.
Reasoning Path Divergence: A New Metric and Curation Strategy to Unlock LLM Diverse Thinking
Oct 30, 2025While Test-Time Scaling (TTS) has proven effective in improving the reasoning ability of large language models (LLMs), low diversity in model outputs often becomes a bottleneck; this is partly caused by the common "one problem, one solution" (1P1S) training practice, which provides a single canonical answer and can push models toward a narrow set of reasoning paths. To address this, we propose a "one problem, multiple solutions" (1PNS) training paradigm that exposes the model to a variety of valid reasoning trajectories and thus increases inference diversity. A core challenge for 1PNS is reliably measuring semantic differences between multi-step chains of thought, so we introduce Reasoning Path Divergence (RPD), a step-level metric that aligns and scores Long Chain-of-Thought solutions to capture differences in intermediate reasoning. Using RPD, we curate maximally diverse solution sets per problem and fine-tune Qwen3-4B-Base. Experiments show that RPD-selected training yields more varied outputs and higher pass@k, with an average +2.80% gain in pass@16 over a strong 1P1S baseline and a +4.99% gain on AIME24, demonstrating that 1PNS further amplifies the effectiveness of TTS. Our code is available at https://github.com/fengjujf/Reasoning-Path-Divergence .
WebResearcher: Unleashing unbounded reasoning capability in Long-Horizon Agents
Sep 16, 2025



Recent advances in deep-research systems have demonstrated the potential for AI agents to autonomously discover and synthesize knowledge from external sources. In this paper, we introduce WebResearcher, a novel framework for building such agents through two key components: (1) WebResearcher, an iterative deep-research paradigm that reformulates deep research as a Markov Decision Process, where agents periodically consolidate findings into evolving reports while maintaining focused workspaces, overcoming the context suffocation and noise contamination that plague existing mono-contextual approaches; and (2) WebFrontier, a scalable data synthesis engine that generates high-quality training data through tool-augmented complexity escalation, enabling systematic creation of research tasks that bridge the gap between passive knowledge recall and active knowledge construction. Notably, we find that the training data from our paradigm significantly enhances tool-use capabilities even for traditional mono-contextual methods. Furthermore, our paradigm naturally scales through parallel thinking, enabling concurrent multi-agent exploration for more comprehensive conclusions. Extensive experiments across 6 challenging benchmarks demonstrate that WebResearcher achieves state-of-the-art performance, even surpassing frontier proprietary systems.
Evaluating Large Language Model with Knowledge Oriented Language Specific Simple Question Answering
May 22, 2025



We introduce KoLasSimpleQA, the first benchmark evaluating the multilingual factual ability of Large Language Models (LLMs). Inspired by existing research, we created the question set with features such as single knowledge point coverage, absolute objectivity, unique answers, and temporal stability. These questions enable efficient evaluation using the LLM-as-judge paradigm, testing both the LLMs' factual memory and self-awareness ("know what they don't know"). KoLasSimpleQA expands existing research in two key dimensions: (1) Breadth (Multilingual Coverage): It includes 9 languages, supporting global applicability evaluation. (2) Depth (Dual Domain Design): It covers both the general domain (global facts) and the language-specific domain (such as history, culture, and regional traditions) for a comprehensive assessment of multilingual capabilities. We evaluated mainstream LLMs, including traditional LLM and emerging Large Reasoning Models. Results show significant performance differences between the two domains, particularly in performance metrics, ranking, calibration, and robustness. This highlights the need for targeted evaluation and optimization in multilingual contexts. We hope KoLasSimpleQA will help the research community better identify LLM capability boundaries in multilingual contexts and provide guidance for model optimization. We will release KoLasSimpleQA at https://github.com/opendatalab/KoLasSimpleQA .
Improving Your Model Ranking on Chatbot Arena by Vote Rigging
Jan 29, 2025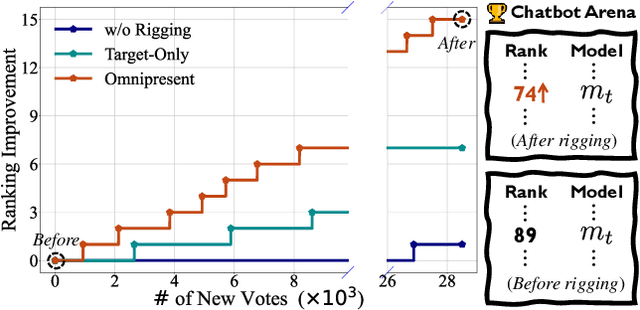
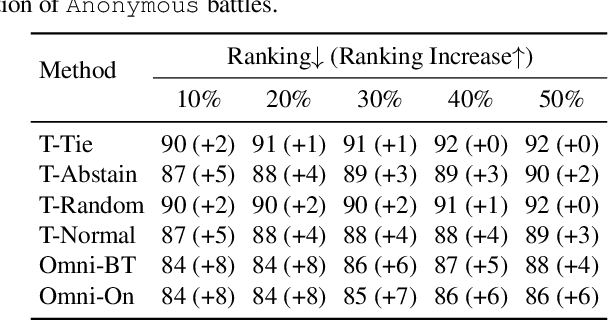
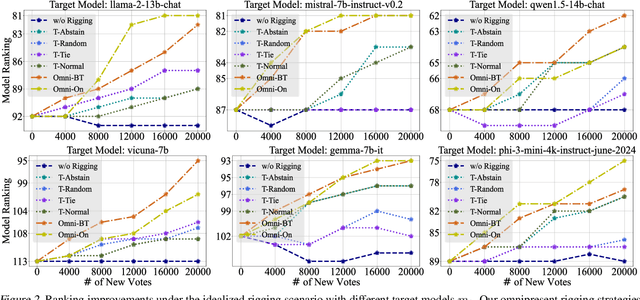

Chatbot Arena is a popular platform for evaluating LLMs by pairwise battles, where users vote for their preferred response from two randomly sampled anonymous models. While Chatbot Arena is widely regarded as a reliable LLM ranking leaderboard, we show that crowdsourced voting can be rigged to improve (or decrease) the ranking of a target model $m_{t}$. We first introduce a straightforward target-only rigging strategy that focuses on new battles involving $m_{t}$, identifying it via watermarking or a binary classifier, and exclusively voting for $m_{t}$ wins. However, this strategy is practically inefficient because there are over $190$ models on Chatbot Arena and on average only about $1\%$ of new battles will involve $m_{t}$. To overcome this, we propose omnipresent rigging strategies, exploiting the Elo rating mechanism of Chatbot Arena that any new vote on a battle can influence the ranking of the target model $m_{t}$, even if $m_{t}$ is not directly involved in the battle. We conduct experiments on around $1.7$ million historical votes from the Chatbot Arena Notebook, showing that omnipresent rigging strategies can improve model rankings by rigging only hundreds of new votes. While we have evaluated several defense mechanisms, our findings highlight the importance of continued efforts to prevent vote rigging. Our code is available at https://github.com/sail-sg/Rigging-ChatbotArena.
WanJuanSiLu: A High-Quality Open-Source Webtext Dataset for Low-Resource Languages
Jan 24, 2025



This paper introduces the open-source dataset WanJuanSiLu, designed to provide high-quality training corpora for low-resource languages, thereby advancing the research and development of multilingual models. To achieve this, we have developed a systematic data processing framework tailored for low-resource languages. This framework encompasses key stages such as data extraction, corpus cleaning, content deduplication, security filtering, quality evaluation, and theme classification. Through the implementation of this framework, we have significantly improved both the quality and security of the dataset, while maintaining its linguistic diversity. As of now, data for all five languages have been fully open-sourced. The dataset can be accessed at https://opendatalab.com/applyMultilingualCorpus, and GitHub repository is available at https://github.com/opendatalab/WanJuan3.0
RM-Bench: Benchmarking Reward Models of Language Models with Subtlety and Style
Oct 21, 2024



Reward models are critical in techniques like Reinforcement Learning from Human Feedback (RLHF) and Inference Scaling Laws, where they guide language model alignment and select optimal responses. Despite their importance, existing reward model benchmarks often evaluate models by asking them to distinguish between responses generated by models of varying power. However, this approach fails to assess reward models on subtle but critical content changes and variations in style, resulting in a low correlation with policy model performance. To this end, we introduce RM-Bench, a novel benchmark designed to evaluate reward models based on their sensitivity to subtle content differences and resistance to style biases. Extensive experiments demonstrate that RM-Bench strongly correlates with policy model performance, making it a reliable reference for selecting reward models to align language models effectively. We evaluate nearly 40 reward models on RM-Bench. Our results reveal that even state-of-the-art models achieve an average performance of only 46.6%, which falls short of random-level accuracy (50%) when faced with style bias interference. These findings highlight the significant room for improvement in current reward models. Related code and data are available at https://github.com/THU-KEG/RM-Bench.
Uncovering, Explaining, and Mitigating the Superficial Safety of Backdoor Defense
Oct 13, 2024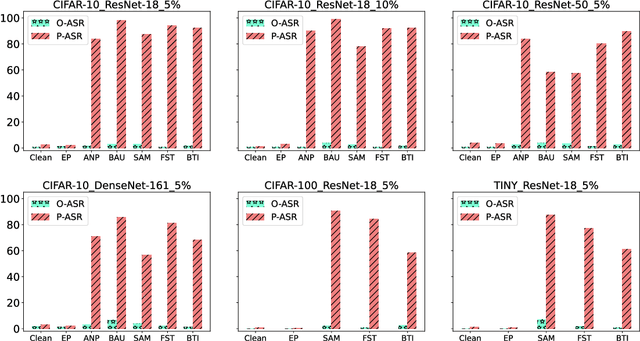
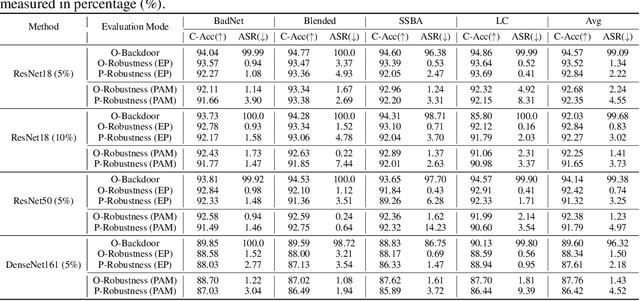

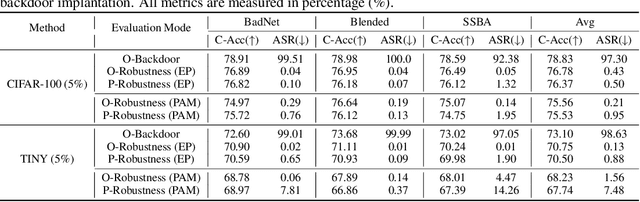
Backdoor attacks pose a significant threat to Deep Neural Networks (DNNs) as they allow attackers to manipulate model predictions with backdoor triggers. To address these security vulnerabilities, various backdoor purification methods have been proposed to purify compromised models. Typically, these purified models exhibit low Attack Success Rates (ASR), rendering them resistant to backdoored inputs. However, Does achieving a low ASR through current safety purification methods truly eliminate learned backdoor features from the pretraining phase? In this paper, we provide an affirmative answer to this question by thoroughly investigating the Post-Purification Robustness of current backdoor purification methods. We find that current safety purification methods are vulnerable to the rapid re-learning of backdoor behavior, even when further fine-tuning of purified models is performed using a very small number of poisoned samples. Based on this, we further propose the practical Query-based Reactivation Attack (QRA) which could effectively reactivate the backdoor by merely querying purified models. We find the failure to achieve satisfactory post-tuning robustness stems from the insufficient deviation of purified models from the backdoored model along the backdoor-connected path. To improve the post-purification robustness, we propose a straightforward tuning defense, Path-Aware Minimization (PAM), which promotes deviation along backdoor-connected paths with extra model updates. Extensive experiments demonstrate that PAM significantly improves post-purification robustness while maintaining a good clean accuracy and low ASR. Our work provides a new perspective on understanding the effectiveness of backdoor safety tuning and highlights the importance of faithfully assessing the model's safety.