 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePsychologically Enhanced AI Agents
Sep 04, 2025



We introduce MBTI-in-Thoughts, a framework for enhancing the effectiveness of Large Language Model (LLM) agents through psychologically grounded personality conditioning. Drawing on the Myers-Briggs Type Indicator (MBTI), our method primes agents with distinct personality archetypes via prompt engineering, enabling control over behavior along two foundational axes of human psychology, cognition and affect. We show that such personality priming yields consistent, interpretable behavioral biases across diverse tasks: emotionally expressive agents excel in narrative generation, while analytically primed agents adopt more stable strategies in game-theoretic settings. Our framework supports experimenting with structured multi-agent communication protocols and reveals that self-reflection prior to interaction improves cooperation and reasoning quality. To ensure trait persistence, we integrate the official 16Personalities test for automated verification. While our focus is on MBTI, we show that our approach generalizes seamlessly to other psychological frameworks such as Big Five, HEXACO, or Enneagram. By bridging psychological theory and LLM behavior design, we establish a foundation for psychologically enhanced AI agents without any fine-tuning.
Benchmarking Filtered Approximate Nearest Neighbor Search Algorithms on Transformer-based Embedding Vectors
Jul 29, 2025Advances in embedding models for text, image, audio, and video drive progress across multiple domains, including retrieval-augmented generation, recommendation systems, vehicle/person reidentification, and face recognition. Many applications in these domains require an efficient method to retrieve items that are close to a given query in the embedding space while satisfying a filter condition based on the item's attributes, a problem known as Filtered Approximate Nearest Neighbor Search (FANNS). In this work, we present a comprehensive survey and taxonomy of FANNS methods and analyze how they are benchmarked in the literature. By doing so, we identify a key challenge in the current FANNS landscape: the lack of diverse and realistic datasets, particularly ones derived from the latest transformer-based text embedding models. To address this, we introduce a novel dataset consisting of embedding vectors for the abstracts of over 2.7 million research articles from the arXiv repository, accompanied by 11 real-world attributes such as authors and categories. We benchmark a wide range of FANNS methods on our novel dataset and find that each method has distinct strengths and limitations; no single approach performs best across all scenarios. ACORN, for example, supports various filter types and performs reliably across dataset scales but is often outperformed by more specialized methods. SeRF shows excellent performance for range filtering on ordered attributes but cannot handle categorical attributes. Filtered-DiskANN and UNG excel on the medium-scale dataset but fail on the large-scale dataset, highlighting the challenge posed by transformer-based embeddings, which are often more than an order of magnitude larger than earlier embeddings. We conclude that no universally best method exists.
Higher-Order Graph Databases
Jun 24, 2025



Recent advances in graph databases (GDBs) have been driving interest in large-scale analytics, yet current systems fail to support higher-order (HO) interactions beyond first-order (one-hop) relations, which are crucial for tasks such as subgraph counting, polyadic modeling, and HO graph learning. We address this by introducing a new class of systems, higher-order graph databases (HO-GDBs) that use lifting and lowering paradigms to seamlessly extend traditional GDBs with HO. We provide a theoretical analysis of OLTP and OLAP queries, ensuring correctness, scalability, and ACID compliance. We implement a lightweight, modular, and parallelizable HO-GDB prototype that offers native support for hypergraphs, node-tuples, subgraphs, and other HO structures under a unified API. The prototype scales to large HO OLTP & OLAP workloads and shows how HO improves analytical tasks, for example enhancing accuracy of graph neural networks within a GDB by 44%. Our work ensures low latency and high query throughput, and generalizes both ACID-compliant and eventually consistent systems.
Affordable AI Assistants with Knowledge Graph of Thoughts
Apr 03, 2025Large Language Models (LLMs) are revolutionizing the development of AI assistants capable of performing diverse tasks across domains. However, current state-of-the-art LLM-driven agents face significant challenges, including high operational costs and limited success rates on complex benchmarks like GAIA. To address these issues, we propose the Knowledge Graph of Thoughts (KGoT), an innovative AI assistant architecture that integrates LLM reasoning with dynamically constructed knowledge graphs (KGs). KGoT extracts and structures task-relevant knowledge into a dynamic KG representation, iteratively enhanced through external tools such as math solvers, web crawlers, and Python scripts. Such structured representation of task-relevant knowledge enables low-cost models to solve complex tasks effectively. For example, KGoT achieves a 29% improvement in task success rates on the GAIA benchmark compared to Hugging Face Agents with GPT-4o mini, while reducing costs by over 36x compared to GPT-4o. Improvements for recent reasoning models are similar, e.g., 36% and 37.5% for Qwen2.5-32B and Deepseek-R1-70B, respectively. KGoT offers a scalable, affordable, and high-performing solution for AI assistants.
Reasoning Language Models: A Blueprint
Jan 20, 2025Reasoning language models (RLMs), also known as Large Reasoning Models (LRMs), such as OpenAI's o1 and o3, DeepSeek-V3, and Alibaba's QwQ, have redefined AI's problem-solving capabilities by extending large language models (LLMs) with advanced reasoning mechanisms. Yet, their high costs, proprietary nature, and complex architectures - uniquely combining Reinforcement Learning (RL), search heuristics, and LLMs - present accessibility and scalability challenges. To address these, we propose a comprehensive blueprint that organizes RLM components into a modular framework, based on a survey and analysis of all RLM works. This blueprint incorporates diverse reasoning structures (chains, trees, graphs, and nested forms), reasoning strategies (e.g., Monte Carlo Tree Search, Beam Search), RL concepts (policy, value models and others), and supervision schemes (Output-Based and Process-Based Supervision). We also provide detailed mathematical formulations and algorithmic specifications to simplify RLM implementation. By showing how schemes like LLaMA-Berry, QwQ, Journey Learning, and Graph of Thoughts fit as special cases, we demonstrate the blueprint's versatility and unifying potential. To illustrate its utility, we introduce x1, a modular implementation for rapid RLM prototyping and experimentation. Using x1 and a literature review, we provide key insights, such as multi-phase training for policy and value models, and the importance of familiar training distributions. Finally, we outline how RLMs can integrate with a broader LLM ecosystem, including tools and databases. Our work demystifies RLM construction, democratizes advanced reasoning capabilities, and fosters innovation, aiming to mitigate the gap between "rich AI" and "poor AI" by lowering barriers to RLM development and experimentation.
Hardware Acceleration for Knowledge Graph Processing: Challenges & Recent Developments
Aug 22, 2024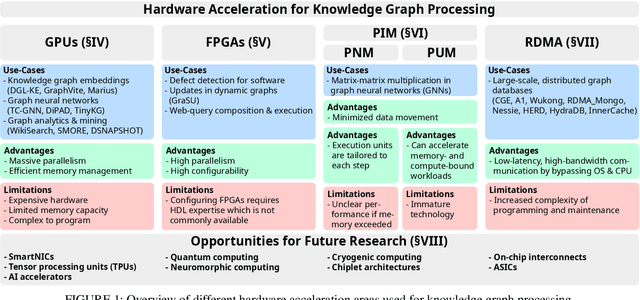
Knowledge graphs (KGs) have achieved significant attention in recent years, particularly in the area of the Semantic Web as well as gaining popularity in other application domains such as data mining and search engines. Simultaneously, there has been enormous progress in the development of different types of heterogeneous hardware, impacting the way KGs are processed. The aim of this paper is to provide a systematic literature review of knowledge graph hardware acceleration. For this, we present a classification of the primary areas in knowledge graph technology that harnesses different hardware units for accelerating certain knowledge graph functionalities. We then extensively describe respective works, focusing on how KG related schemes harness modern hardware accelerators. Based on our review, we identify various research gaps and future exploratory directions that are anticipated to be of significant value both for academics and industry practitioners.
Multi-Head RAG: Solving Multi-Aspect Problems with LLMs
Jun 07, 2024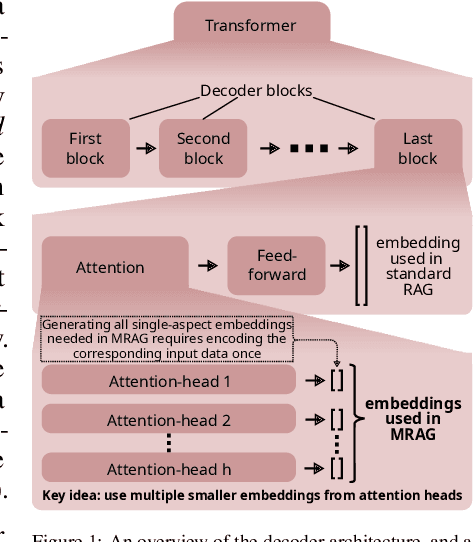

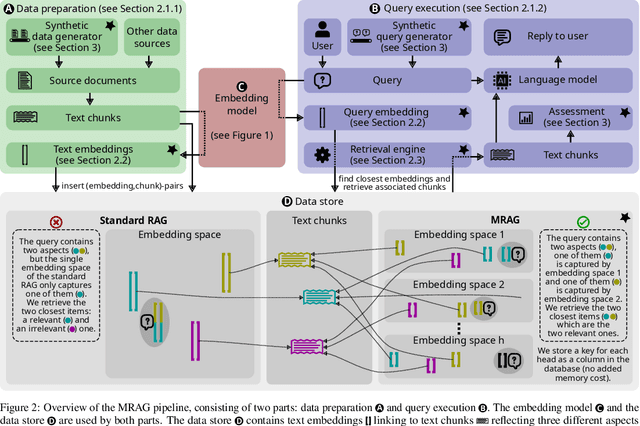

Retrieval Augmented Generation (RAG) enhances the abilities of Large Language Models (LLMs) by enabling the retrieval of documents into the LLM context to provide more accurate and relevant responses. Existing RAG solutions do not focus on queries that may require fetching multiple documents with substantially different contents. Such queries occur frequently, but are challenging because the embeddings of these documents may be distant in the embedding space, making it hard to retrieve them all. This paper introduces Multi-Head RAG (MRAG), a novel scheme designed to address this gap with a simple yet powerful idea: leveraging activations of Transformer's multi-head attention layer, instead of the decoder layer, as keys for fetching multi-aspect documents. The driving motivation is that different attention heads can learn to capture different data aspects. Harnessing the corresponding activations results in embeddings that represent various facets of data items and queries, improving the retrieval accuracy for complex queries. We provide an evaluation methodology and metrics, synthetic datasets, and real-world use cases to demonstrate MRAG's effectiveness, showing improvements of up to 20% in relevance over standard RAG baselines. MRAG can be seamlessly integrated with existing RAG frameworks and benchmarking tools like RAGAS as well as different classes of data stores.
CheckEmbed: Effective Verification of LLM Solutions to Open-Ended Tasks
Jun 04, 2024
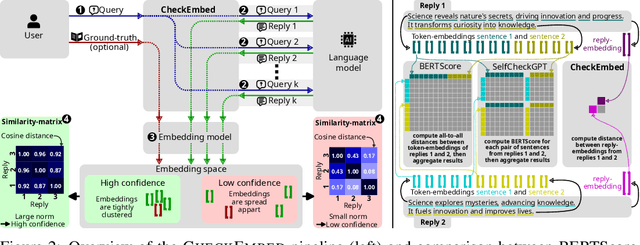
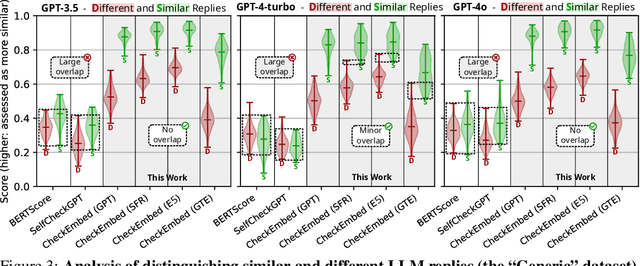
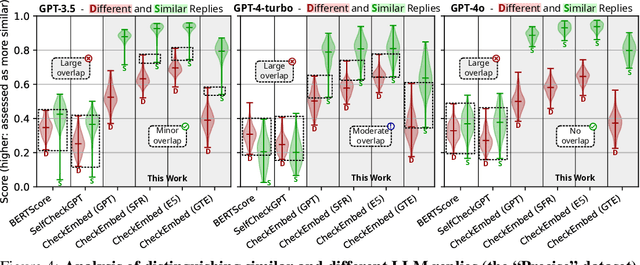
Large Language Models (LLMs) are revolutionizing various domains, yet verifying their answers remains a significant challenge, especially for intricate open-ended tasks such as consolidation, summarization, and extraction of knowledge. In this work, we propose CheckEmbed: an accurate, scalable, and simple LLM verification approach. CheckEmbed is driven by a straightforward yet powerful idea: in order to compare LLM solutions to one another or to the ground-truth, compare their corresponding answer-level embeddings obtained with a model such as GPT Text Embedding Large. This reduces a complex textual answer to a single embedding, facilitating straightforward, fast, and meaningful verification. We develop a comprehensive verification pipeline implementing the CheckEmbed methodology. The CheckEmbed pipeline also comes with metrics for assessing the truthfulness of the LLM answers, such as embedding heatmaps and their summaries. We show how to use these metrics for deploying practical engines that decide whether an LLM answer is satisfactory or not. We apply the pipeline to real-world document analysis tasks, including term extraction and document summarization, showcasing significant improvements in accuracy, cost-effectiveness, and runtime performance compared to existing token-, sentence-, and fact-level schemes such as BERTScore or SelfCheckGPT.
Neural Graph Databases
Sep 20, 2022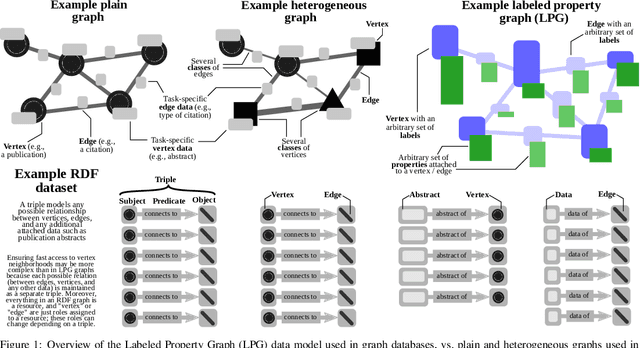

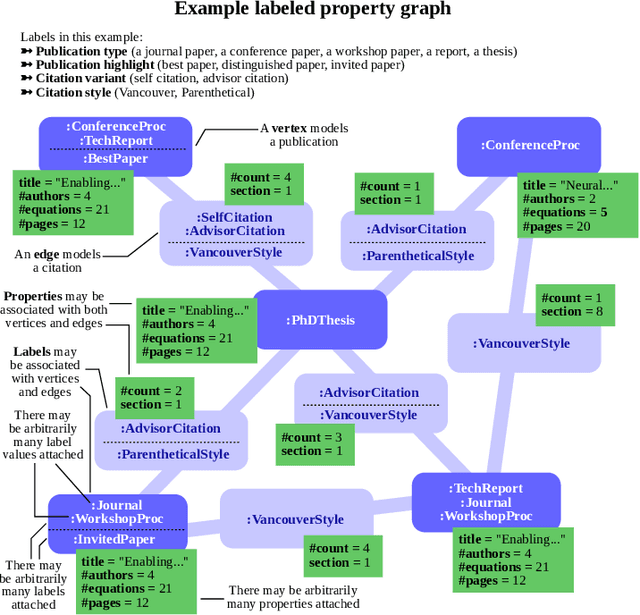
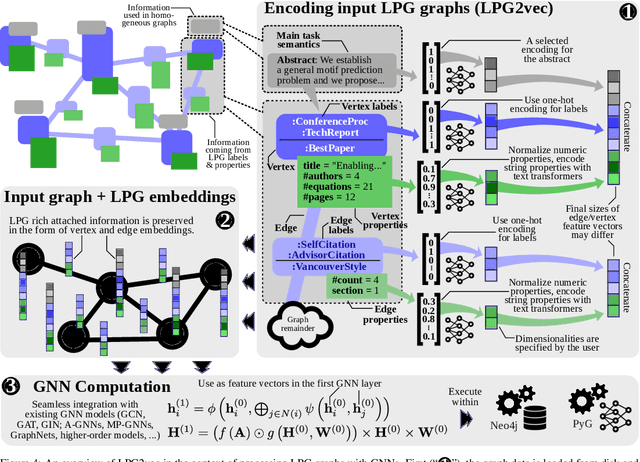
Graph databases (GDBs) enable processing and analysis of unstructured, complex, rich, and usually vast graph datasets. Despite the large significance of GDBs in both academia and industry, little effort has been made into integrating them with the predictive power of graph neural networks (GNNs). In this work, we show how to seamlessly combine nearly any GNN model with the computational capabilities of GDBs. For this, we observe that the majority of these systems are based on, or support, a graph data model called the Labeled Property Graph (LPG), where vertices and edges can have arbitrarily complex sets of labels and properties. We then develop LPG2vec, an encoder that transforms an arbitrary LPG dataset into a representation that can be directly used with a broad class of GNNs, including convolutional, attentional, message-passing, and even higher-order or spectral models. In our evaluation, we show that the rich information represented as LPG labels and properties is properly preserved by LPG2vec, and it increases the accuracy of predictions regardless of the targeted learning task or the used GNN model, by up to 34% compared to graphs with no LPG labels/properties. In general, LPG2vec enables combining predictive power of the most powerful GNNs with the full scope of information encoded in the LPG model, paving the way for neural graph databases, a class of systems where the vast complexity of maintained data will benefit from modern and future graph machine learning methods.