 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolar Sparsity: High Throughput Batched LLM Inferencing with Scalable Contextual Sparsity
May 20, 2025



Accelerating large language model (LLM) inference is critical for real-world deployments requiring high throughput and low latency. Contextual sparsity, where each token dynamically activates only a small subset of the model parameters, shows promise but does not scale to large batch sizes due to union of active neurons quickly approaching dense computation. We introduce Polar Sparsity, highlighting a key shift in sparsity importance from MLP to Attention layers as we scale batch size and sequence length. While MLP layers become more compute-efficient under batching, their sparsity vanishes. In contrast, attention becomes increasingly more expensive at scale, while their head sparsity remains stable and batch-invariant. We develop hardware-efficient, sparsity-aware GPU kernels for selective MLP and Attention computations, delivering up to \(2.2\times\) end-to-end speedups for models like OPT, LLaMA-2 \& 3, across various batch sizes and sequence lengths without compromising accuracy. To our knowledge, this is the first work to demonstrate that contextual sparsity can scale effectively to large batch sizes, delivering substantial inference acceleration with minimal changes, making Polar Sparsity practical for large-scale, high-throughput LLM deployment systems. Our code is available at: https://github.com/susavlsh10/Polar-Sparsity.
Lion Cub: Minimizing Communication Overhead in Distributed Lion
Nov 25, 2024Communication overhead is a key challenge in distributed deep learning, especially on slower Ethernet interconnects, and given current hardware trends, communication is likely to become a major bottleneck. While gradient compression techniques have been explored for SGD and Adam, the Lion optimizer has the distinct advantage that its update vectors are the output of a sign operation, enabling straightforward quantization. However, simply compressing updates for communication and using techniques like majority voting fails to lead to end-to-end speedups due to inefficient communication algorithms and reduced convergence. We analyze three factors critical to distributed learning with Lion: optimizing communication methods, identifying effective quantization methods, and assessing the necessity of momentum synchronization. Our findings show that quantization techniques adapted to Lion and selective momentum synchronization can significantly reduce communication costs while maintaining convergence. We combine these into Lion Cub, which enables up to 5x speedups in end-to-end training compared to Lion. This highlights Lion's potential as a communication-efficient solution for distributed training.
Learning to Compose SuperWeights for Neural Parameter Allocation Search
Dec 03, 2023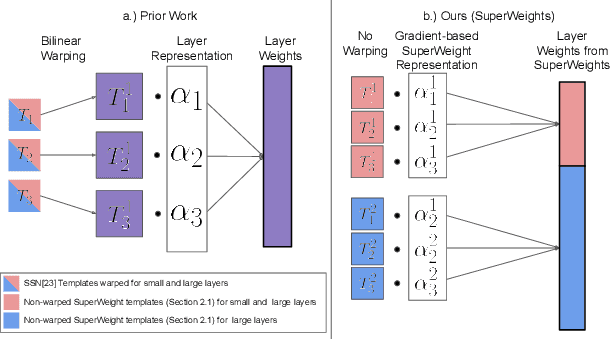
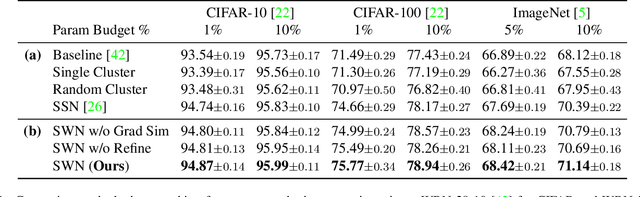
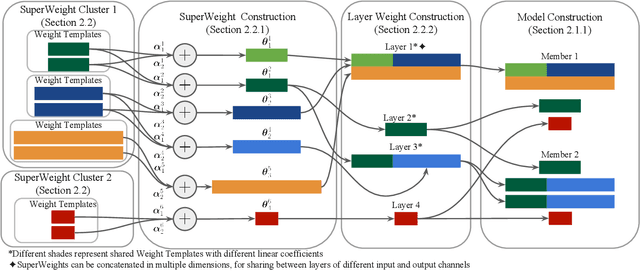
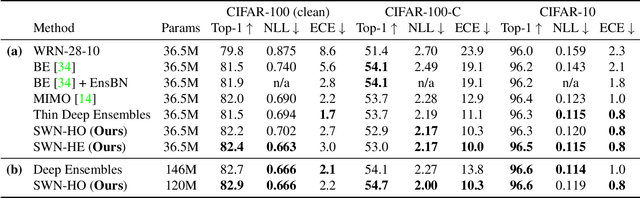
Neural parameter allocation search (NPAS) automates parameter sharing by obtaining weights for a network given an arbitrary, fixed parameter budget. Prior work has two major drawbacks we aim to address. First, there is a disconnect in the sharing pattern between the search and training steps, where weights are warped for layers of different sizes during the search to measure similarity, but not during training, resulting in reduced performance. To address this, we generate layer weights by learning to compose sets of SuperWeights, which represent a group of trainable parameters. These SuperWeights are created to be large enough so they can be used to represent any layer in the network, but small enough that they are computationally efficient. The second drawback we address is the method of measuring similarity between shared parameters. Whereas prior work compared the weights themselves, we argue this does not take into account the amount of conflict between the shared weights. Instead, we use gradient information to identify layers with shared weights that wish to diverge from each other. We demonstrate that our SuperWeight Networks consistently boost performance over the state-of-the-art on the ImageNet and CIFAR datasets in the NPAS setting. We further show that our approach can generate parameters for many network architectures using the same set of weights. This enables us to support tasks like efficient ensembling and anytime prediction, outperforming fully-parameterized ensembles with 17% fewer parameters.
Cached Operator Reordering: A Unified View for Fast GNN Training
Aug 23, 2023Graph Neural Networks (GNNs) are a powerful tool for handling structured graph data and addressing tasks such as node classification, graph classification, and clustering. However, the sparse nature of GNN computation poses new challenges for performance optimization compared to traditional deep neural networks. We address these challenges by providing a unified view of GNN computation, I/O, and memory. By analyzing the computational graphs of the Graph Convolutional Network (GCN) and Graph Attention (GAT) layers -- two widely used GNN layers -- we propose alternative computation strategies. We present adaptive operator reordering with caching, which achieves a speedup of up to 2.43x for GCN compared to the current state-of-the-art. Furthermore, an exploration of different caching schemes for GAT yields a speedup of up to 1.94x. The proposed optimizations save memory, are easily implemented across various hardware platforms, and have the potential to alleviate performance bottlenecks in training large-scale GNN models.
STen: Productive and Efficient Sparsity in PyTorch
Apr 15, 2023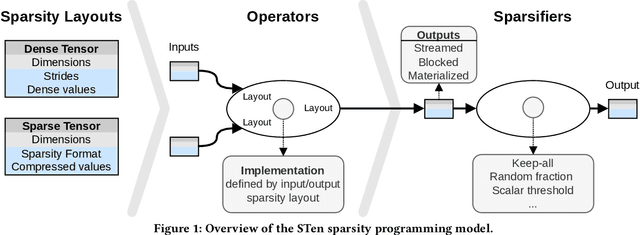
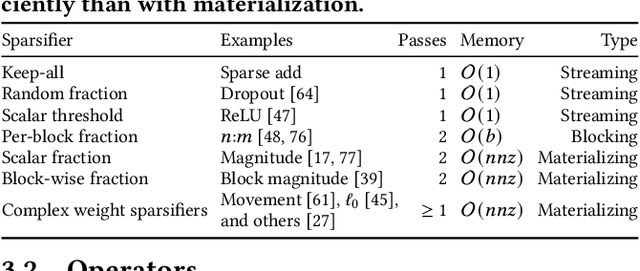
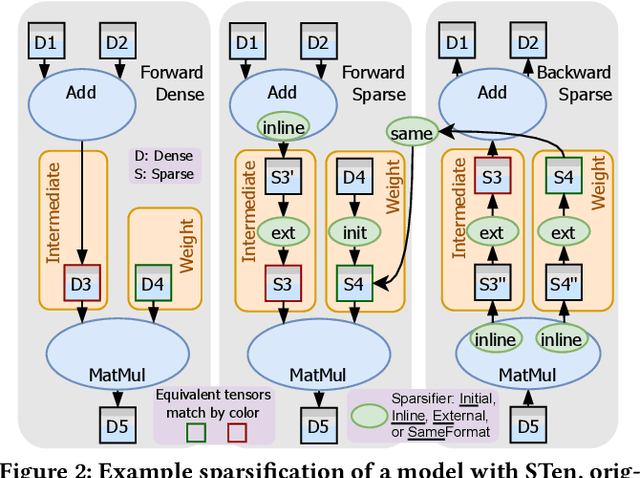
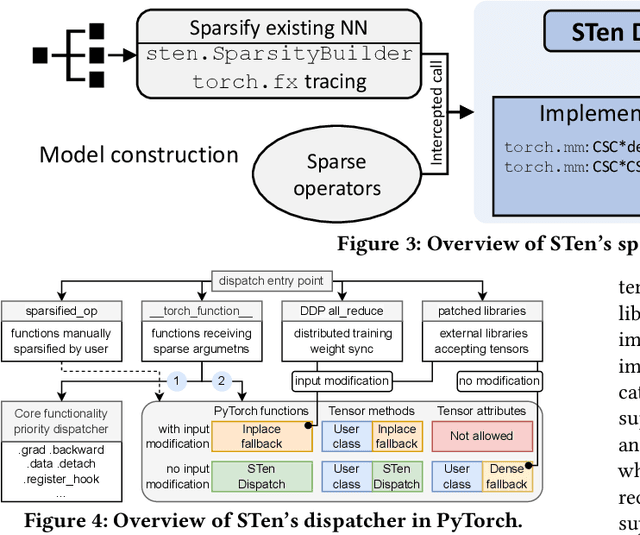
As deep learning models grow, sparsity is becoming an increasingly critical component of deep neural networks, enabling improved performance and reduced storage. However, existing frameworks offer poor support for sparsity. Specialized sparsity engines focus exclusively on sparse inference, while general frameworks primarily focus on sparse tensors in classical formats and neglect the broader sparsification pipeline necessary for using sparse models, especially during training. Further, existing frameworks are not easily extensible: adding a new sparse tensor format or operator is challenging and time-consuming. To address this, we propose STen, a sparsity programming model and interface for PyTorch, which incorporates sparsity layouts, operators, and sparsifiers, in an efficient, customizable, and extensible framework that supports virtually all sparsification methods. We demonstrate this by developing a high-performance grouped n:m sparsity layout for CPU inference at moderate sparsity. STen brings high performance and ease of use to the ML community, making sparsity easily accessible.
Spatial Mixture-of-Experts
Nov 24, 2022


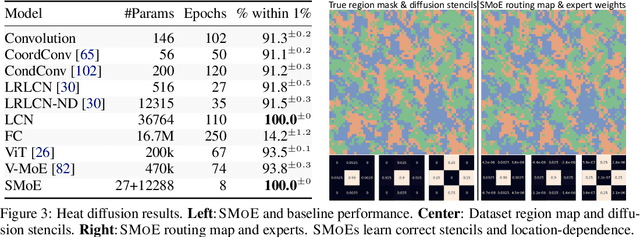
Many data have an underlying dependence on spatial location; it may be weather on the Earth, a simulation on a mesh, or a registered image. Yet this feature is rarely taken advantage of, and violates common assumptions made by many neural network layers, such as translation equivariance. Further, many works that do incorporate locality fail to capture fine-grained structure. To address this, we introduce the Spatial Mixture-of-Experts (SMoE) layer, a sparsely-gated layer that learns spatial structure in the input domain and routes experts at a fine-grained level to utilize it. We also develop new techniques to train SMoEs, including a self-supervised routing loss and damping expert errors. Finally, we show strong results for SMoEs on numerous tasks, and set new state-of-the-art results for medium-range weather prediction and post-processing ensemble weather forecasts.
Neural Graph Databases
Sep 20, 2022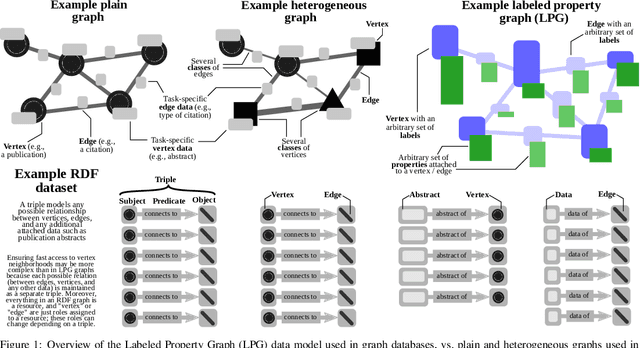

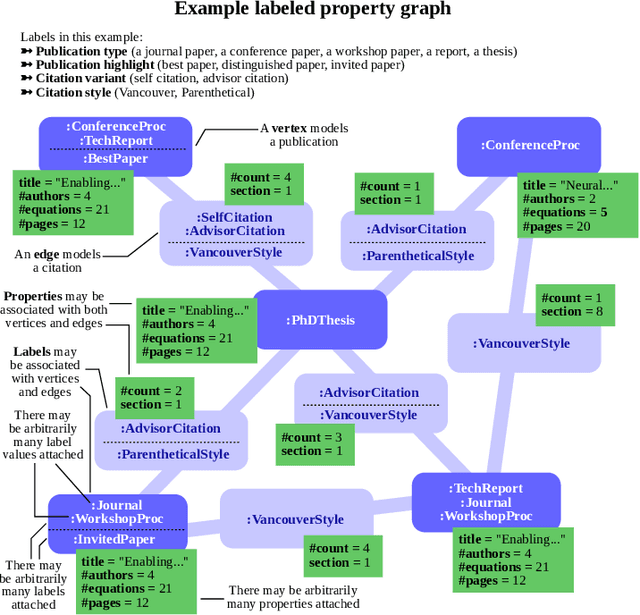
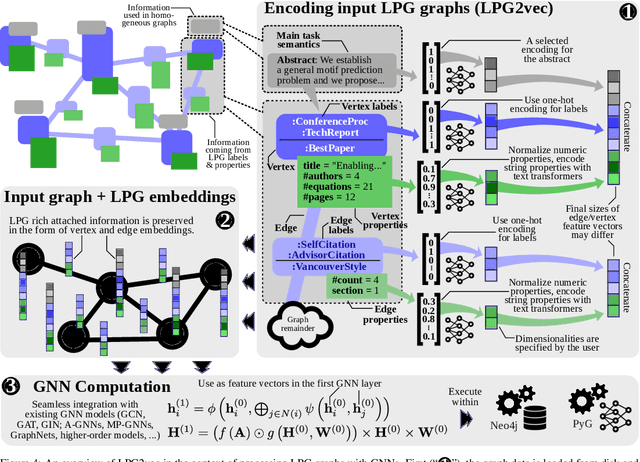
Graph databases (GDBs) enable processing and analysis of unstructured, complex, rich, and usually vast graph datasets. Despite the large significance of GDBs in both academia and industry, little effort has been made into integrating them with the predictive power of graph neural networks (GNNs). In this work, we show how to seamlessly combine nearly any GNN model with the computational capabilities of GDBs. For this, we observe that the majority of these systems are based on, or support, a graph data model called the Labeled Property Graph (LPG), where vertices and edges can have arbitrarily complex sets of labels and properties. We then develop LPG2vec, an encoder that transforms an arbitrary LPG dataset into a representation that can be directly used with a broad class of GNNs, including convolutional, attentional, message-passing, and even higher-order or spectral models. In our evaluation, we show that the rich information represented as LPG labels and properties is properly preserved by LPG2vec, and it increases the accuracy of predictions regardless of the targeted learning task or the used GNN model, by up to 34% compared to graphs with no LPG labels/properties. In general, LPG2vec enables combining predictive power of the most powerful GNNs with the full scope of information encoded in the LPG model, paving the way for neural graph databases, a class of systems where the vast complexity of maintained data will benefit from modern and future graph machine learning methods.
ENS-10: A Dataset For Post-Processing Ensemble Weather Forecast
Jun 29, 2022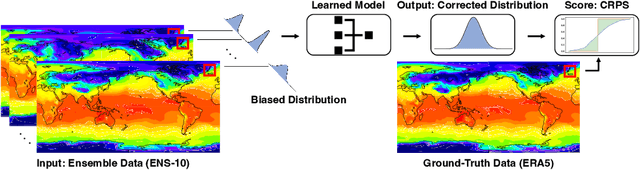
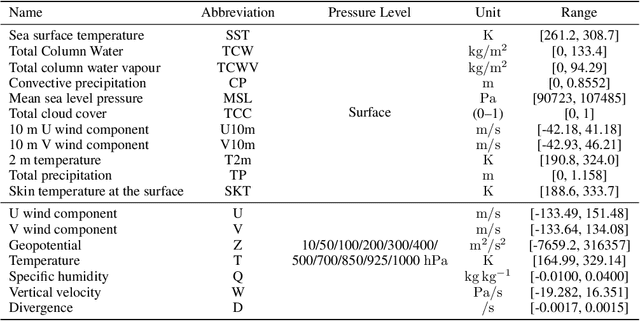
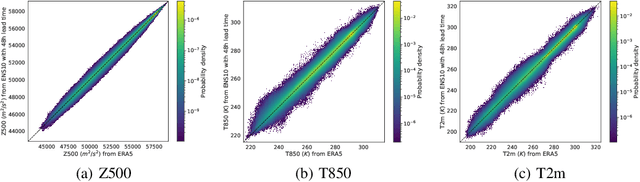
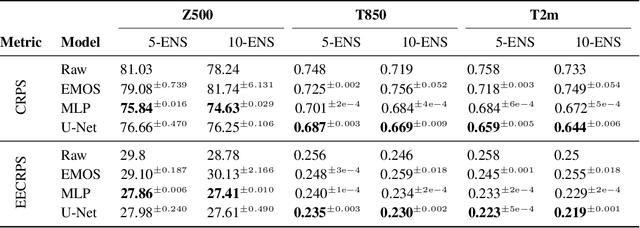
Post-processing ensemble prediction systems can improve weather forecasting, especially for extreme event prediction. In recent years, different machine learning models have been developed to improve the quality of the post-processing step. However, these models heavily rely on the data and generating such ensemble members requires multiple runs of numerical weather prediction models, at high computational cost. This paper introduces the ENS-10 dataset, consisting of ten ensemble members spread over 20 years (1998-2017). The ensemble members are generated by perturbing numerical weather simulations to capture the chaotic behavior of the Earth. To represent the three-dimensional state of the atmosphere, ENS-10 provides the most relevant atmospheric variables in 11 distinct pressure levels as well as the surface at 0.5-degree resolution. The dataset targets the prediction correction task at 48-hour lead time, which is essentially improving the forecast quality by removing the biases of the ensemble members. To this end, ENS-10 provides the weather variables for forecast lead times T=0, 24, and 48 hours (two data points per week). We provide a set of baselines for this task on ENS-10 and compare their performance in correcting the prediction of different weather variables. We also assess our baselines for predicting extreme events using our dataset. The ENS-10 dataset is available under the Creative Commons Attribution 4.0 International (CC BY 4.0) licence.
A Data-Centric Optimization Framework for Machine Learning
Oct 20, 2021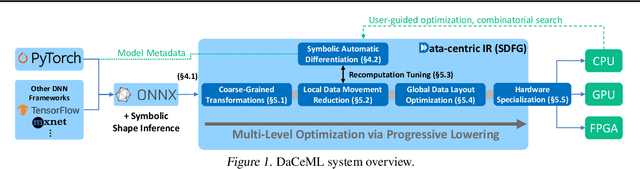
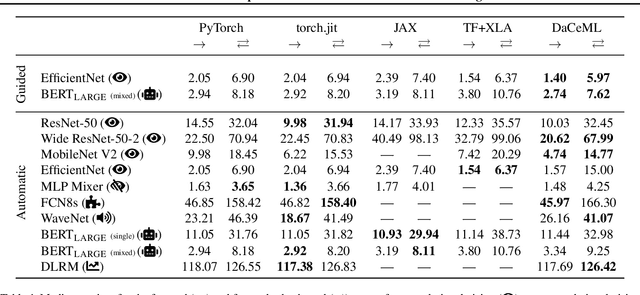
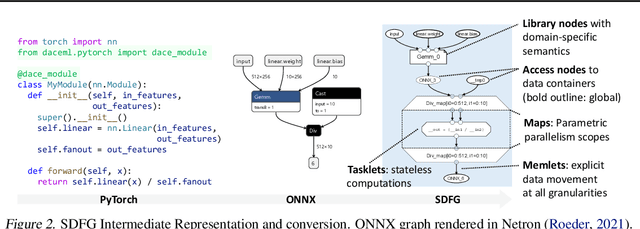
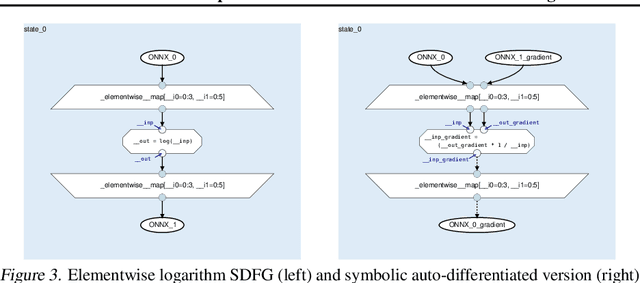
Rapid progress in deep learning is leading to a diverse set of quickly changing models, with a dramatically growing demand for compute. However, as frameworks specialize optimization to patterns in popular networks, they implicitly constrain novel and diverse models that drive progress in research. We empower deep learning researchers by defining a flexible and user-customizable pipeline for optimizing training of arbitrary deep neural networks, based on data movement minimization. The pipeline begins with standard networks in PyTorch or ONNX and transforms computation through progressive lowering. We define four levels of general-purpose transformations, from local intra-operator optimizations to global data movement reduction. These operate on a data-centric graph intermediate representation that expresses computation and data movement at all levels of abstraction, including expanding basic operators such as convolutions to their underlying computations. Central to the design is the interactive and introspectable nature of the pipeline. Every part is extensible through a Python API, and can be tuned interactively using a GUI. We demonstrate competitive performance or speedups on ten different networks, with interactive optimizations discovering new opportunities in EfficientNet.
Learning Combinatorial Node Labeling Algorithms
Jun 15, 2021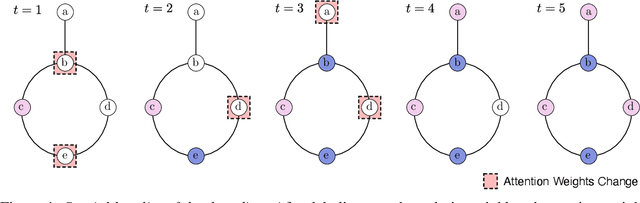
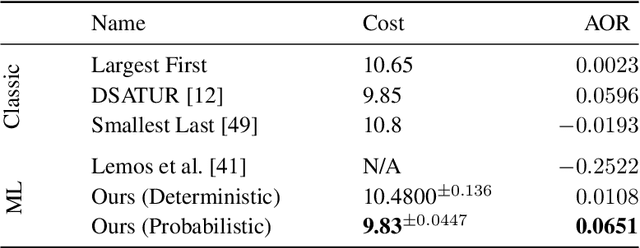
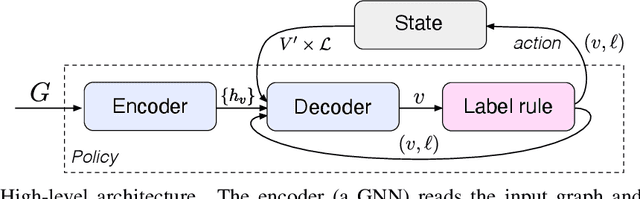

We present a graph neural network to learn graph coloring heuristics using reinforcement learning. Our learned deterministic heuristics give better solutions than classical degree-based greedy heuristics and only take seconds to evaluate on graphs with tens of thousands of vertices. As our approach is based on policy-gradients, it also learns a probabilistic policy as well. These probabilistic policies outperform all greedy coloring baselines and a machine learning baseline. Our approach generalizes several previous machine-learning frameworks, which applied to problems like minimum vertex cover. We also demonstrate that our approach outperforms two greedy heuristics on minimum vertex cover.