 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOOM: Benchmarking Out-Of-distribution Molecular Property Predictions of Machine Learning Models
May 03, 2025Advances in deep learning and generative modeling have driven interest in data-driven molecule discovery pipelines, whereby machine learning (ML) models are used to filter and design novel molecules without requiring prohibitively expensive first-principles simulations. Although the discovery of novel molecules that extend the boundaries of known chemistry requires accurate out-of-distribution (OOD) predictions, ML models often struggle to generalize OOD. Furthermore, there are currently no systematic benchmarks for molecular OOD prediction tasks. We present BOOM, $\boldsymbol{b}$enchmarks for $\boldsymbol{o}$ut-$\boldsymbol{o}$f-distribution $\boldsymbol{m}$olecular property predictions -- a benchmark study of property-based out-of-distribution models for common molecular property prediction models. We evaluate more than 140 combinations of models and property prediction tasks to benchmark deep learning models on their OOD performance. Overall, we do not find any existing models that achieve strong OOD generalization across all tasks: even the top performing model exhibited an average OOD error 3x larger than in-distribution. We find that deep learning models with high inductive bias can perform well on OOD tasks with simple, specific properties. Although chemical foundation models with transfer and in-context learning offer a promising solution for limited training data scenarios, we find that current foundation models do not show strong OOD extrapolation capabilities. We perform extensive ablation experiments to highlight how OOD performance is impacted by data generation, pre-training, hyperparameter optimization, model architecture, and molecular representation. We propose that developing ML models with strong OOD generalization is a new frontier challenge in chemical ML model development. This open-source benchmark will be made available on Github.
Lion Cub: Minimizing Communication Overhead in Distributed Lion
Nov 25, 2024Communication overhead is a key challenge in distributed deep learning, especially on slower Ethernet interconnects, and given current hardware trends, communication is likely to become a major bottleneck. While gradient compression techniques have been explored for SGD and Adam, the Lion optimizer has the distinct advantage that its update vectors are the output of a sign operation, enabling straightforward quantization. However, simply compressing updates for communication and using techniques like majority voting fails to lead to end-to-end speedups due to inefficient communication algorithms and reduced convergence. We analyze three factors critical to distributed learning with Lion: optimizing communication methods, identifying effective quantization methods, and assessing the necessity of momentum synchronization. Our findings show that quantization techniques adapted to Lion and selective momentum synchronization can significantly reduce communication costs while maintaining convergence. We combine these into Lion Cub, which enables up to 5x speedups in end-to-end training compared to Lion. This highlights Lion's potential as a communication-efficient solution for distributed training.
The Case for Strong Scaling in Deep Learning: Training Large 3D CNNs with Hybrid Parallelism
Jul 25, 2020We present scalable hybrid-parallel algorithms for training large-scale 3D convolutional neural networks. Deep learning-based emerging scientific workflows often require model training with large, high-dimensional samples, which can make training much more costly and even infeasible due to excessive memory usage. We solve these challenges by extensively applying hybrid parallelism throughout the end-to-end training pipeline, including both computations and I/O. Our hybrid-parallel algorithm extends the standard data parallelism with spatial parallelism, which partitions a single sample in the spatial domain, realizing strong scaling beyond the mini-batch dimension with a larger aggregated memory capacity. We evaluate our proposed training algorithms with two challenging 3D CNNs, CosmoFlow and 3D U-Net. Our comprehensive performance studies show that good weak and strong scaling can be achieved for both networks using up 2K GPUs. More importantly, we enable training of CosmoFlow with much larger samples than previously possible, realizing an order-of-magnitude improvement in prediction accuracy.
Merlin: Enabling Machine Learning-Ready HPC Ensembles
Dec 05, 2019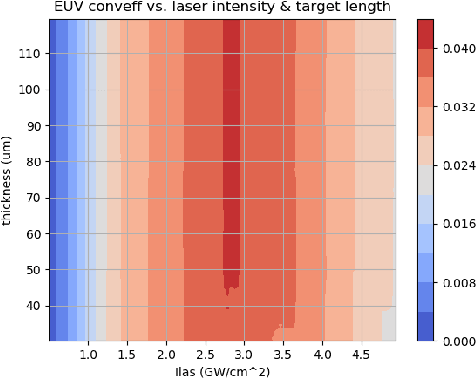
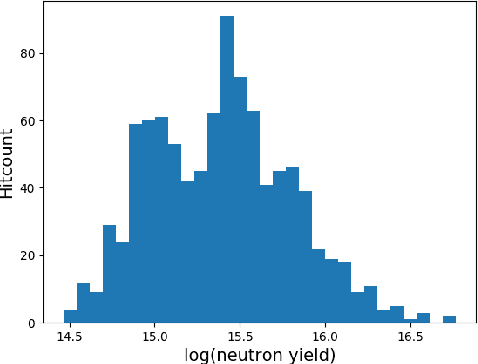
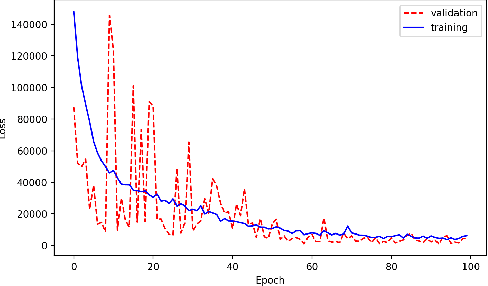
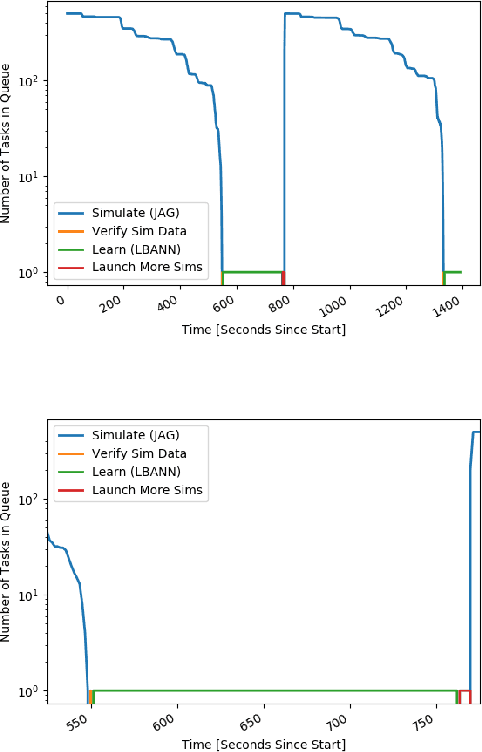
With the growing complexity of computational and experimental facilities, many scientific researchers are turning to machine learning (ML) techniques to analyze large scale ensemble data. With complexities such as multi-component workflows, heterogeneous machine architectures, parallel file systems, and batch scheduling, care must be taken to facilitate this analysis in a high performance computing (HPC) environment. In this paper, we present Merlin, a workflow framework to enable large ML-friendly ensembles of scientific HPC simulations. By augmenting traditional HPC with distributed compute technologies, Merlin aims to lower the barrier for scientific subject matter experts to incorporate ML into their analysis. In addition to its design and some examples, we describe how Merlin was deployed on the Sierra Supercomputer at Lawrence Livermore National Laboratory to create an unprecedented benchmark inertial confinement fusion dataset of approximately 100 million individual simulations and over 24 terabytes of multi-modal physics-based scalar, vector and hyperspectral image data.
Parallelizing Training of Deep Generative Models on Massive Scientific Datasets
Oct 05, 2019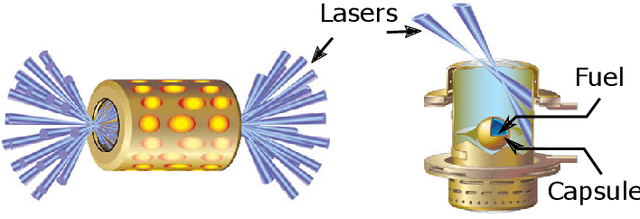
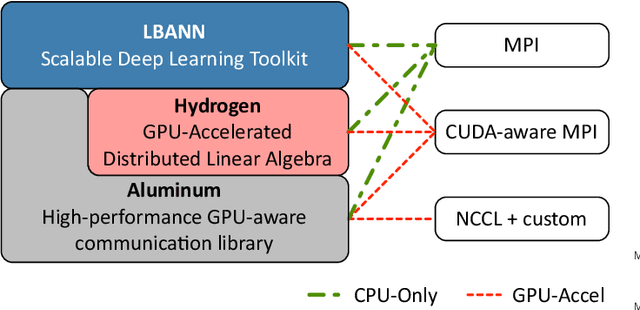
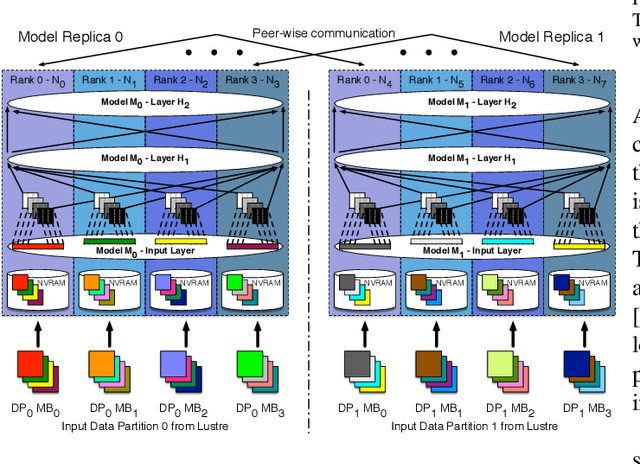
Training deep neural networks on large scientific data is a challenging task that requires enormous compute power, especially if no pre-trained models exist to initialize the process. We present a novel tournament method to train traditional as well as generative adversarial networks built on LBANN, a scalable deep learning framework optimized for HPC systems. LBANN combines multiple levels of parallelism and exploits some of the worlds largest supercomputers. We demonstrate our framework by creating a complex predictive model based on multi-variate data from high-energy-density physics containing hundreds of millions of images and hundreds of millions of scalar values derived from tens of millions of simulations of inertial confinement fusion. Our approach combines an HPC workflow and extends LBANN with optimized data ingestion and the new tournament-style training algorithm to produce a scalable neural network architecture using a CORAL-class supercomputer. Experimental results show that 64 trainers (1024 GPUs) achieve a speedup of 70.2 over a single trainer (16 GPUs) baseline, and an effective 109% parallel efficiency.
Improving Strong-Scaling of CNN Training by Exploiting Finer-Grained Parallelism
Mar 15, 2019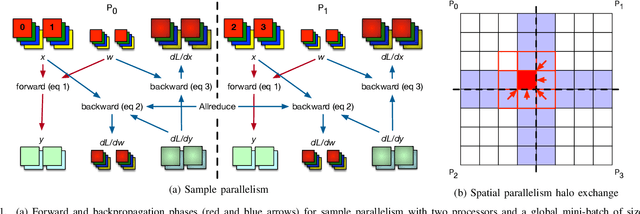
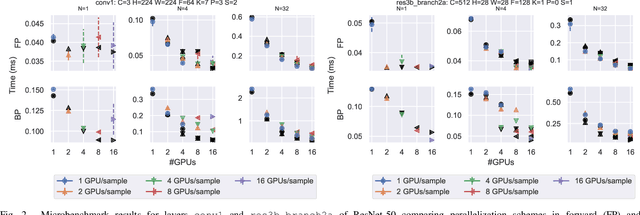
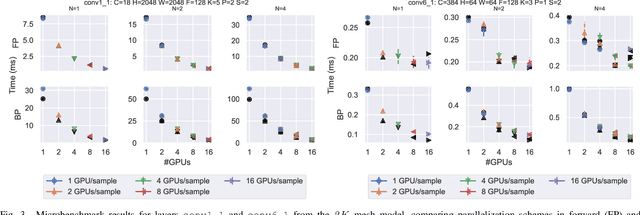
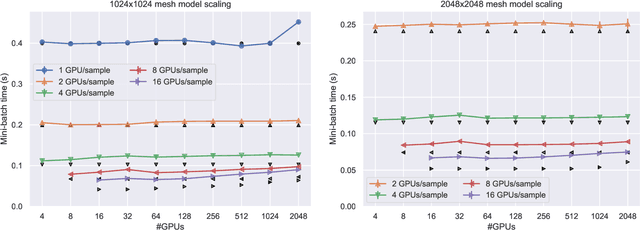
Scaling CNN training is necessary to keep up with growing datasets and reduce training time. We also see an emerging need to handle datasets with very large samples, where memory requirements for training are large. Existing training frameworks use a data-parallel approach that partitions samples within a mini-batch, but limits to scaling the mini-batch size and memory consumption makes this untenable for large samples. We describe and implement new approaches to convolution, which parallelize using spatial decomposition or a combination of sample and spatial decomposition. This introduces many performance knobs for a network, so we develop a performance model for CNNs and present a method for using it to automatically determine efficient parallelization strategies. We evaluate our algorithms with microbenchmarks and image classification with ResNet-50. Our algorithms allow us to prototype a model for a mesh-tangling dataset, where sample sizes are very large. We show that our parallelization achieves excellent strong and weak scaling and enables training for previously unreachable datasets.
Large-Scale Deep Learning on the YFCC100M Dataset
Feb 11, 2015


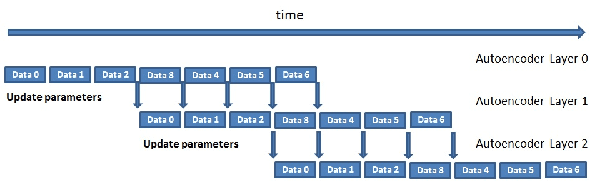
We present a work-in-progress snapshot of learning with a 15 billion parameter deep learning network on HPC architectures applied to the largest publicly available natural image and video dataset released to-date. Recent advancements in unsupervised deep neural networks suggest that scaling up such networks in both model and training dataset size can yield significant improvements in the learning of concepts at the highest layers. We train our three-layer deep neural network on the Yahoo! Flickr Creative Commons 100M dataset. The dataset comprises approximately 99.2 million images and 800,000 user-created videos from Yahoo's Flickr image and video sharing platform. Training of our network takes eight days on 98 GPU nodes at the High Performance Computing Center at Lawrence Livermore National Laboratory. Encouraging preliminary results and future research directions are presented and discussed.