 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFP8 is All You Need (Part 1): Debunking Hardware FP64 as the HPC Holy Grail
May 28, 2026Conventional HPC dogma holds that native hardware FP64 silicon is the irreducible foundation of scientific computing -- the "holy grail" of double-precision simulation. This paper argues the dogma is wrong: on AI-optimised GPUs of the B300 generation and beyond, abundant FP8 tensor throughput combined with the Chinese Remainder Theorem-based Ozaki Scheme II recovers memory-roof execution at full FP64 accuracy across the canonical HPC kernel spectrum. NVIDIA's Blackwell Ultra (B300) collapses native FP64 to ~1.3 TFLOPS -- a 31x regression from the B200 -- rendering even memory-bound kernels (SpMV, GEMV, stencils) compute-bound. We make four contributions. First, a unified analytic model, the Tensor-Memory Equilibrium (TME) model, augmenting the Roofline with a compute multiplier alpha, a bandwidth multiplier beta, and a reconstruction latency gamma. Second, we identify register-level fusion as the mechanism driving beta -> 1, making emulation essentially free behind the memory wall. Third, we project that Ozaki II vaults emulated FP64 from the ~1 TFLOPS native floor to ~500 TFLOPS (B300) and ~400 TFLOPS (Rubin R200), exceeding even B200's native FP64 ceiling by over an order of magnitude in the compute-bound regime while matching the memory roof in the bandwidth-bound regime. Fourth, against an H100 baseline, Ozaki II matches or exceeds H100 on every workload studied, versus the up-to-50x regression that B300 native FP64 imposes. Combined with a companion FFT analysis (Kulisch fixed-point reconstruction on the surviving INT32 pipe) and FP32+Kahan reductions reported in the companion Part(2) paper, every surveyed kernel class on B300 reaches the memory roof at full FP64. The evidence supports the title's claim: FP8, with Ozaki II and Kulisch escape routes, is all one needs for production HPC; native FP64 silicon is no longer the holy grail it has been taken to be.
Myths and Legends in High-Performance Computing
Jan 06, 2023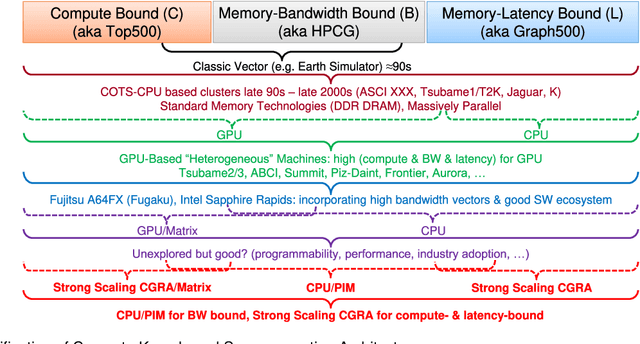
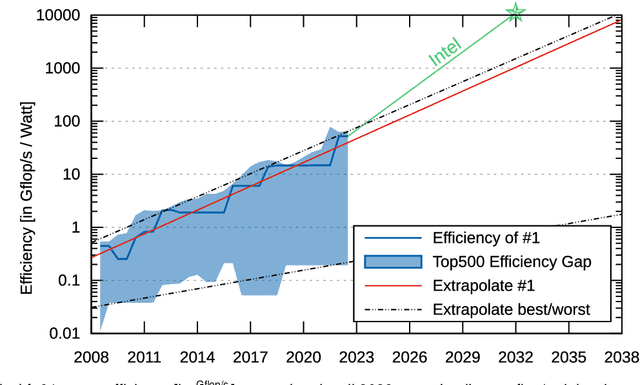
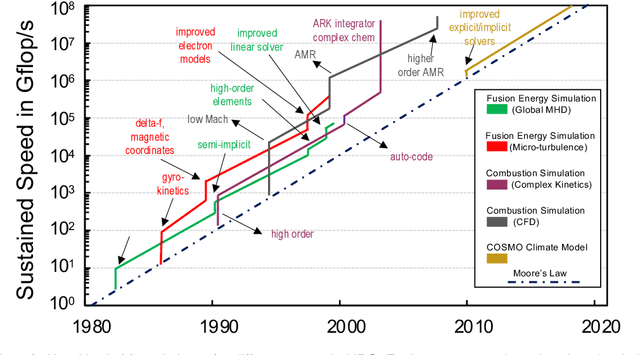
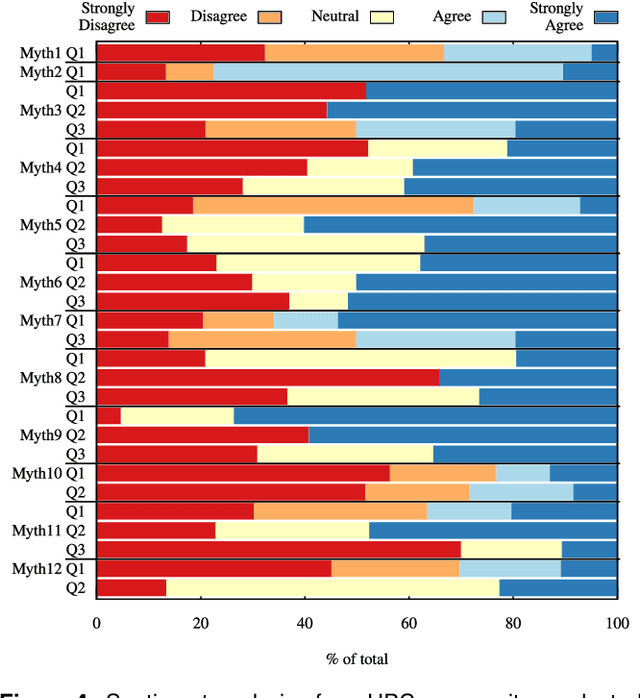
In this humorous and thought provoking article, we discuss certain myths and legends that are folklore among members of the high-performance computing community. We collected those myths from conversations at conferences and meetings, product advertisements, papers, and other communications such as tweets, blogs, and news articles within (and beyond) our community. We believe they represent the zeitgeist of the current era of massive change, driven by the end of many scaling laws such as Dennard scaling and Moore's law. While some laws end, new directions open up, such as algorithmic scaling or novel architecture research. However, these myths are rarely based on scientific facts but often on some evidence or argumentation. In fact, we believe that this is the very reason for the existence of many myths and why they cannot be answered clearly. While it feels like there should be clear answers for each, some may remain endless philosophical debates such as the question whether Beethoven was better than Mozart. We would like to see our collection of myths as a discussion of possible new directions for research and industry investment.
MLPerf HPC: A Holistic Benchmark Suite for Scientific Machine Learning on HPC Systems
Oct 26, 2021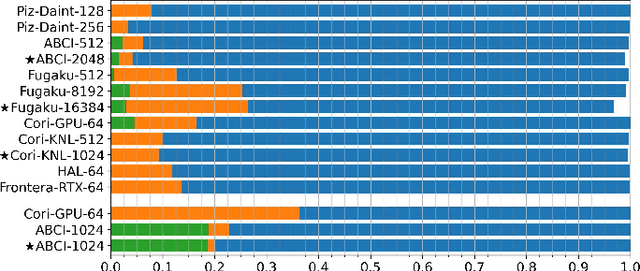
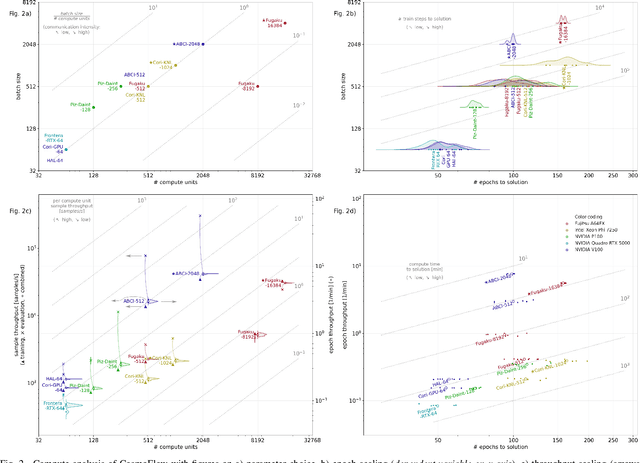
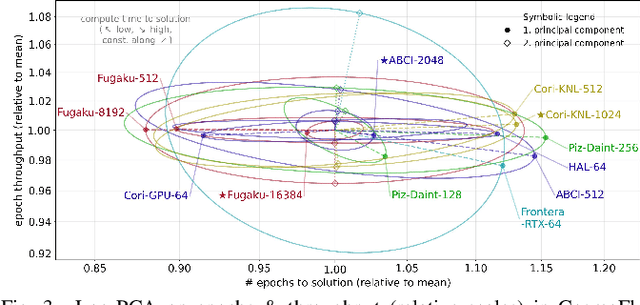
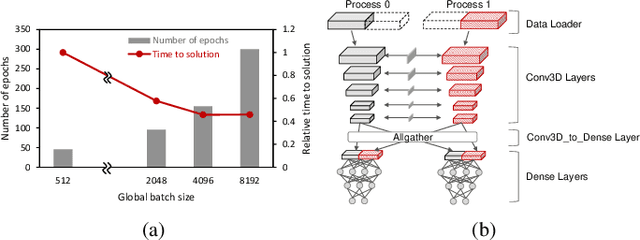
Scientific communities are increasingly adopting machine learning and deep learning models in their applications to accelerate scientific insights. High performance computing systems are pushing the frontiers of performance with a rich diversity of hardware resources and massive scale-out capabilities. There is a critical need to understand fair and effective benchmarking of machine learning applications that are representative of real-world scientific use cases. MLPerf is a community-driven standard to benchmark machine learning workloads, focusing on end-to-end performance metrics. In this paper, we introduce MLPerf HPC, a benchmark suite of large-scale scientific machine learning training applications driven by the MLCommons Association. We present the results from the first submission round, including a diverse set of some of the world's largest HPC systems. We develop a systematic framework for their joint analysis and compare them in terms of data staging, algorithmic convergence, and compute performance. As a result, we gain a quantitative understanding of optimizations on different subsystems such as staging and on-node loading of data, compute-unit utilization, and communication scheduling, enabling overall $>10 \times$ (end-to-end) performance improvements through system scaling. Notably, our analysis shows a scale-dependent interplay between the dataset size, a system's memory hierarchy, and training convergence that underlines the importance of near-compute storage. To overcome the data-parallel scalability challenge at large batch sizes, we discuss specific learning techniques and hybrid data-and-model parallelism that are effective on large systems. We conclude by characterizing each benchmark with respect to low-level memory, I/O, and network behavior to parameterize extended roofline performance models in future rounds.
Scaling Distributed Deep Learning Workloads beyond the Memory Capacity with KARMA
Aug 26, 2020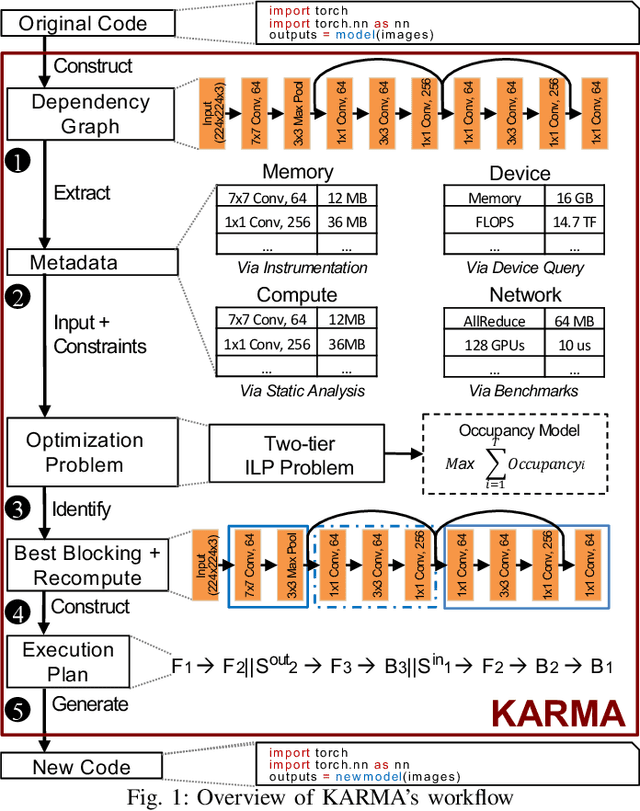
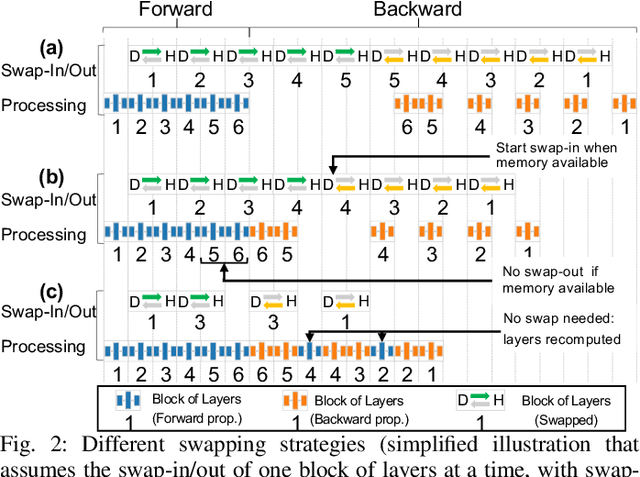
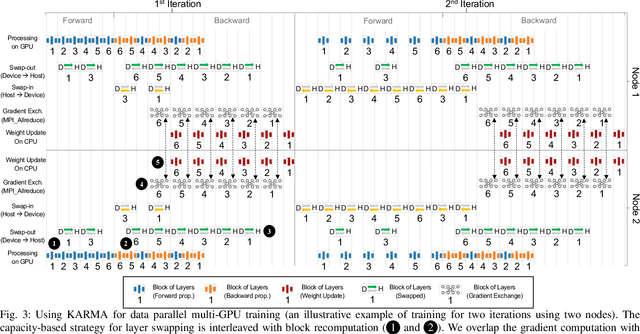

The dedicated memory of hardware accelerators can be insufficient to store all weights and/or intermediate states of large deep learning models. Although model parallelism is a viable approach to reduce the memory pressure issue, significant modification of the source code and considerations for algorithms are required. An alternative solution is to use out-of-core methods instead of, or in addition to, data parallelism. We propose a performance model based on the concurrency analysis of out-of-core training behavior, and derive a strategy that combines layer swapping and redundant recomputing. We achieve an average of 1.52x speedup in six different models over the state-of-the-art out-of-core methods. We also introduce the first method to solve the challenging problem of out-of-core multi-node training by carefully pipelining gradient exchanges and performing the parameter updates on the host. Our data parallel out-of-core solution can outperform complex hybrid model parallelism in training large models, e.g. Megatron-LM and Turning-NLG.
The Case for Strong Scaling in Deep Learning: Training Large 3D CNNs with Hybrid Parallelism
Jul 25, 2020We present scalable hybrid-parallel algorithms for training large-scale 3D convolutional neural networks. Deep learning-based emerging scientific workflows often require model training with large, high-dimensional samples, which can make training much more costly and even infeasible due to excessive memory usage. We solve these challenges by extensively applying hybrid parallelism throughout the end-to-end training pipeline, including both computations and I/O. Our hybrid-parallel algorithm extends the standard data parallelism with spatial parallelism, which partitions a single sample in the spatial domain, realizing strong scaling beyond the mini-batch dimension with a larger aggregated memory capacity. We evaluate our proposed training algorithms with two challenging 3D CNNs, CosmoFlow and 3D U-Net. Our comprehensive performance studies show that good weak and strong scaling can be achieved for both networks using up 2K GPUs. More importantly, we enable training of CosmoFlow with much larger samples than previously possible, realizing an order-of-magnitude improvement in prediction accuracy.
Second-order Optimization Method for Large Mini-batch: Training ResNet-50 on ImageNet in 35 Epochs
Dec 05, 2018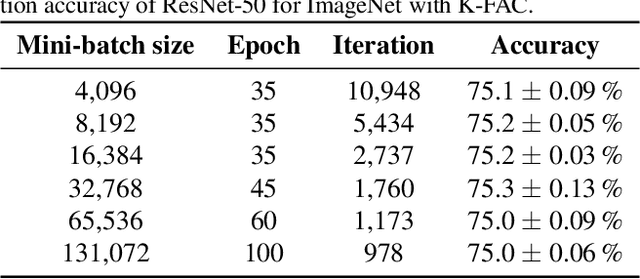
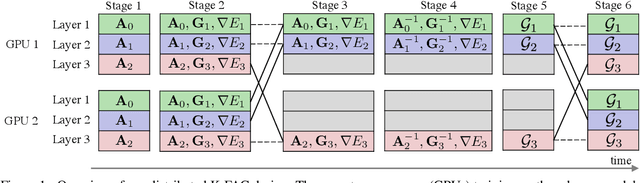
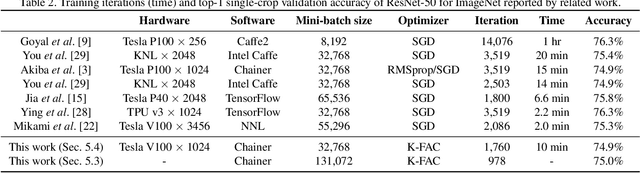
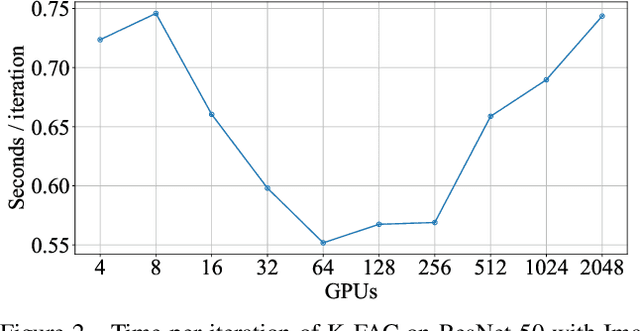
Large-scale distributed training of deep neural networks suffer from the generalization gap caused by the increase in the effective mini-batch size. Previous approaches try to solve this problem by varying the learning rate and batch size over epochs and layers, or some ad hoc modification of the batch normalization. We propose an alternative approach using a second-order optimization method that shows similar generalization capability to first-order methods, but converges faster and can handle larger mini-batches. To test our method on a benchmark where highly optimized first-order methods are available as references, we train ResNet-50 on ImageNet. We converged to 75% Top-1 validation accuracy in 35 epochs for mini-batch sizes under 16,384, and achieved 75% even with a mini-batch size of 131,072, which took 100 epochs.
μ-cuDNN: Accelerating Deep Learning Frameworks with Micro-Batching
Apr 13, 2018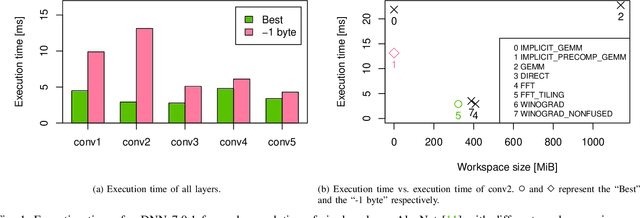
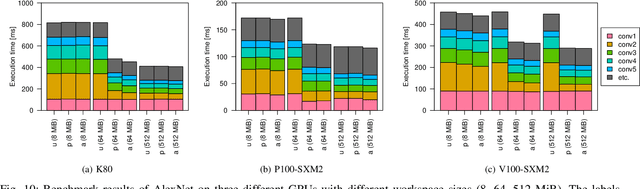
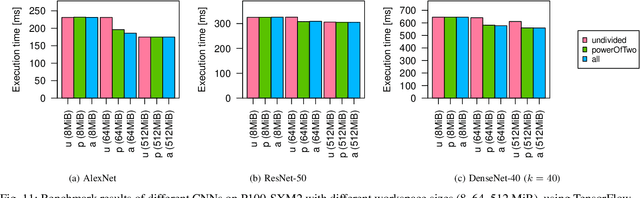
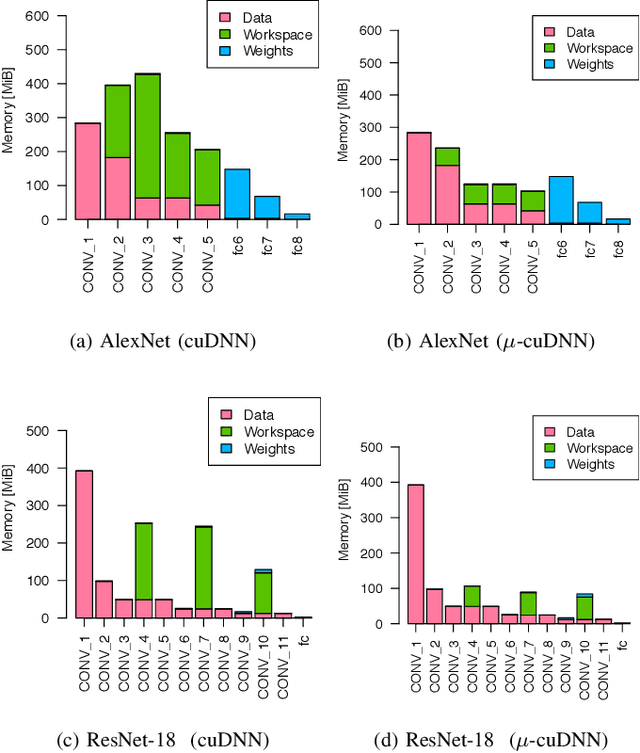
NVIDIA cuDNN is a low-level library that provides GPU kernels frequently used in deep learning. Specifically, cuDNN implements several equivalent convolution algorithms, whose performance and memory footprint may vary considerably, depending on the layer dimensions. When an algorithm is automatically selected by cuDNN, the decision is performed on a per-layer basis, and thus it often resorts to slower algorithms that fit the workspace size constraints. We present {\mu}-cuDNN, a transparent wrapper library for cuDNN, which divides layers' mini-batch computation into several micro-batches. Based on Dynamic Programming and Integer Linear Programming, {\mu}-cuDNN enables faster algorithms by decreasing the workspace requirements. At the same time, {\mu}-cuDNN keeps the computational semantics unchanged, so that it decouples statistical efficiency from the hardware efficiency safely. We demonstrate the effectiveness of {\mu}-cuDNN over two frameworks, Caffe and TensorFlow, achieving speedups of 1.63x for AlexNet and 1.21x for ResNet-18 on P100-SXM2 GPU. These results indicate that using micro-batches can seamlessly increase the performance of deep learning, while maintaining the same memory footprint.