 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Case for Strong Scaling in Deep Learning: Training Large 3D CNNs with Hybrid Parallelism
Jul 25, 2020We present scalable hybrid-parallel algorithms for training large-scale 3D convolutional neural networks. Deep learning-based emerging scientific workflows often require model training with large, high-dimensional samples, which can make training much more costly and even infeasible due to excessive memory usage. We solve these challenges by extensively applying hybrid parallelism throughout the end-to-end training pipeline, including both computations and I/O. Our hybrid-parallel algorithm extends the standard data parallelism with spatial parallelism, which partitions a single sample in the spatial domain, realizing strong scaling beyond the mini-batch dimension with a larger aggregated memory capacity. We evaluate our proposed training algorithms with two challenging 3D CNNs, CosmoFlow and 3D U-Net. Our comprehensive performance studies show that good weak and strong scaling can be achieved for both networks using up 2K GPUs. More importantly, we enable training of CosmoFlow with much larger samples than previously possible, realizing an order-of-magnitude improvement in prediction accuracy.
Improving Strong-Scaling of CNN Training by Exploiting Finer-Grained Parallelism
Mar 15, 2019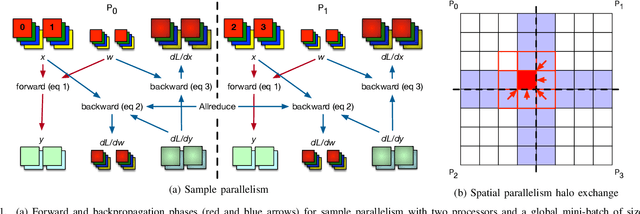
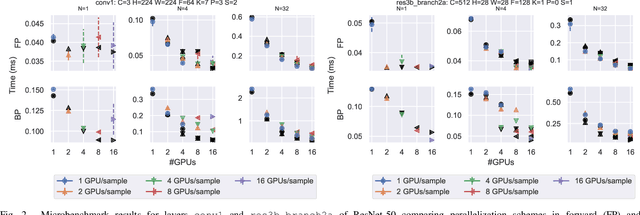
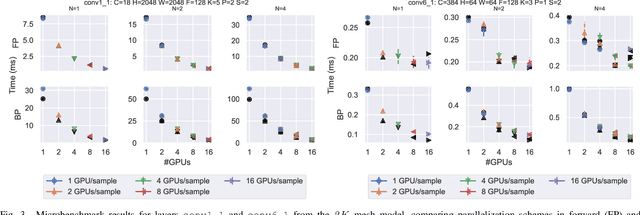
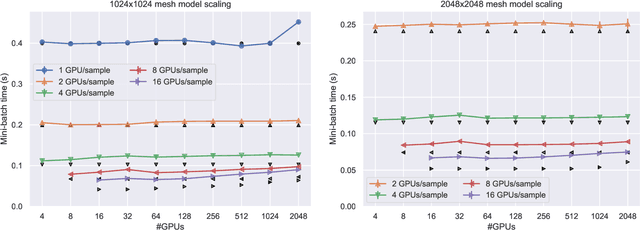
Scaling CNN training is necessary to keep up with growing datasets and reduce training time. We also see an emerging need to handle datasets with very large samples, where memory requirements for training are large. Existing training frameworks use a data-parallel approach that partitions samples within a mini-batch, but limits to scaling the mini-batch size and memory consumption makes this untenable for large samples. We describe and implement new approaches to convolution, which parallelize using spatial decomposition or a combination of sample and spatial decomposition. This introduces many performance knobs for a network, so we develop a performance model for CNNs and present a method for using it to automatically determine efficient parallelization strategies. We evaluate our algorithms with microbenchmarks and image classification with ResNet-50. Our algorithms allow us to prototype a model for a mesh-tangling dataset, where sample sizes are very large. We show that our parallelization achieves excellent strong and weak scaling and enables training for previously unreachable datasets.
Effective Quantization Approaches for Recurrent Neural Networks
Feb 07, 2018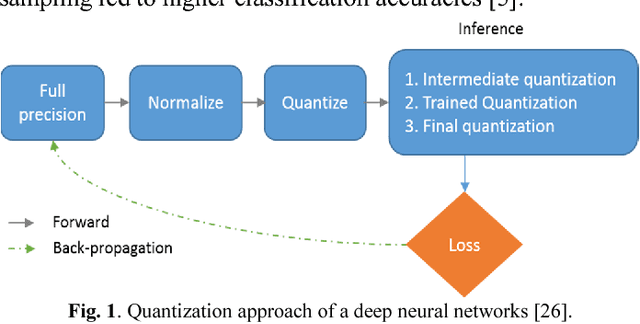
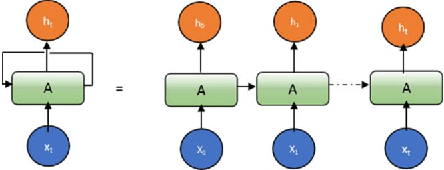
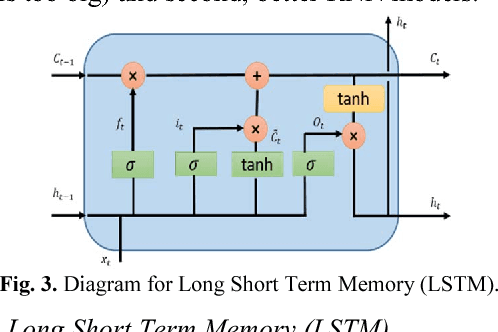
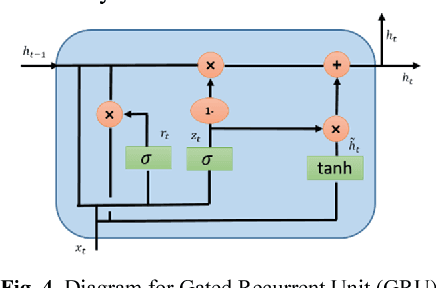
Deep learning, and in particular Recurrent Neural Networks (RNN) have shown superior accuracy in a large variety of tasks including machine translation, language understanding, and movie frame generation. However, these deep learning approaches are very expensive in terms of computation. In most cases, Graphic Processing Units (GPUs) are in used for large scale implementations. Meanwhile, energy efficient RNN approaches are proposed for deploying solutions on special purpose hardware including Field Programming Gate Arrays (FPGAs) and mobile platforms. In this paper, we propose an effective quantization approach for Recurrent Neural Networks (RNN) techniques including Long Short Term Memory (LSTM), Gated Recurrent Units (GRU), and Convolutional Long Short Term Memory (ConvLSTM). We have implemented different quantization methods including Binary Connect {-1, 1}, Ternary Connect {-1, 0, 1}, and Quaternary Connect {-1, -0.5, 0.5, 1}. These proposed approaches are evaluated on different datasets for sentiment analysis on IMDB and video frame predictions on the moving MNIST dataset. The experimental results are compared against the full precision versions of the LSTM, GRU, and ConvLSTM. They show promising results for both sentiment analysis and video frame prediction.